

什么是信息检索?
信息检索简史
信息检索的根源可以追溯到古代,当时建立了图书馆和档案馆来组织和存储信息,包括对学术著作进行索引和字母排序。到 1800 年代,打孔卡被用于处理信息,1931 年,伊曼纽尔·戈德堡获得了第一个成功的机电文档检索设备的专利,该设备被称为“统计机”,旨在搜索胶片上编码的数据。
信息检索在 20 世纪中期随着现代计算机的发展开始正式化为一门科学学科。Gerard Salton 和 Hans Peter Luhn 开创了早期自动文档检索模型。Salton 和康奈尔大学的同事在 1960 年代创建了 SMART 信息检索系统,这是该领域的一个里程碑,被认为为现代 IR 技术和关键概念奠定了基础,包括术语-文档矩阵、向量空间模型、相关性反馈和 Rocchio 分类。
到 1970 年代,随着更先进的检索技术、概率模型和完全阐明的向量处理框架的出现,该领域取得了显著进展。随着 1990 年代后期搜索引擎的出现,曾经主要由学术界、机构和图书馆使用的 IR 系统和模型被广泛使用。
信息检索模型的类型
不同类型的信息检索模型旨在解决特定的挑战并建立检索相关信息的过程。有构成该领域基础的经典模型,试图解决传统方法局限性的非经典模型,以及通常通过集成机器学习和语言模型等先进技术而更进一步的替代 IR 模型。在总体层面,最常见的信息检索模型类型包括
布尔模型
布尔模型是最简单和最早的信息检索模型之一,它基于布尔逻辑,该逻辑使用包括 AND、OR 和 NOT 在内的运算符来组合查询术语。文档表示为术语集,并且处理查询以识别与指定条件匹配的文档。尽管它对于精确查询匹配有效,但布尔模型无法根据相关性对文档进行排名或提供部分匹配。
向量空间模型
在此模型中,文档和查询在多维空间中表示为向量。每个维度对应一个唯一的术语,并且每个维度中的值表示该术语在文档或查询中的重要性和频率。计算查询向量和文档向量之间的余弦相似度以确定文档与查询的相关性。向量空间模型的开发部分是为了解决布尔模型的缺点,它可以提供基于相关性分数的排名结果,并且广泛用于文本检索。
概率模型
此模型估计文档与给定查询相关的概率。它会考虑诸如术语频率和文档长度之类的因素来计算相关性概率。它对于处理大量数据特别有用。由于它使用加权统计数据,因此该模型非常适合提供排名结果。
潜在语义索引 (LSI)
LSI 使用奇异值分解 (SVD) 来捕获术语和文档之间的语义关系。与语义搜索类似,语义索引使用意图和上下文来识别概念相关的文档,即使它们不共享确切的术语。这种关键能力使 LSI 有助于提取文本主体中单词的上下文含义。
Okapi BM25
BM25 是概率模型中较流行的变体之一,它是一个搜索相关性排序函数。搜索引擎使用它来评估文档与搜索查询的相关性。它根据查询术语在每个文档中的出现情况对一组文档进行排名,而不管文档中术语之间的相互关系如何,并且由具有不同组件和参数的许多评分函数组成。BM 代表“最佳匹配”。
为什么信息检索如此重要?
在信息时代,每时每刻都会以前所未有的规模生成数据。如果没有可行的方式来访问信息,数据实际上是无用的。信息检索系统确保用户能够在不断增长的信息过载噪音中获得他们所需的相关信息。
信息检索在现代世界的几乎每个行业和领域都发挥着至关重要的作用,从学术界和电子商务到医疗保健和国防。它是一种人机界面,有助于在企业和个人层面上进行决策、研究和知识发现。从搜索本地桌面到发现世界新闻,或从基因组研究到垃圾邮件过滤,信息检索是我们生活中几乎每个方面都必不可少的。
搜索引擎依靠信息检索模型来提供准确的搜索结果。电子商务平台使用检索模型来根据用户偏好和行为推荐产品。数字图书馆依靠信息检索科学来帮助用户进行研究。在医疗保健领域,信息检索系统协助搜索数据库中相关的患者记录、医学研究和治疗方案。法律专业人士使用信息检索来梳理大量的法律案例以寻找先例。
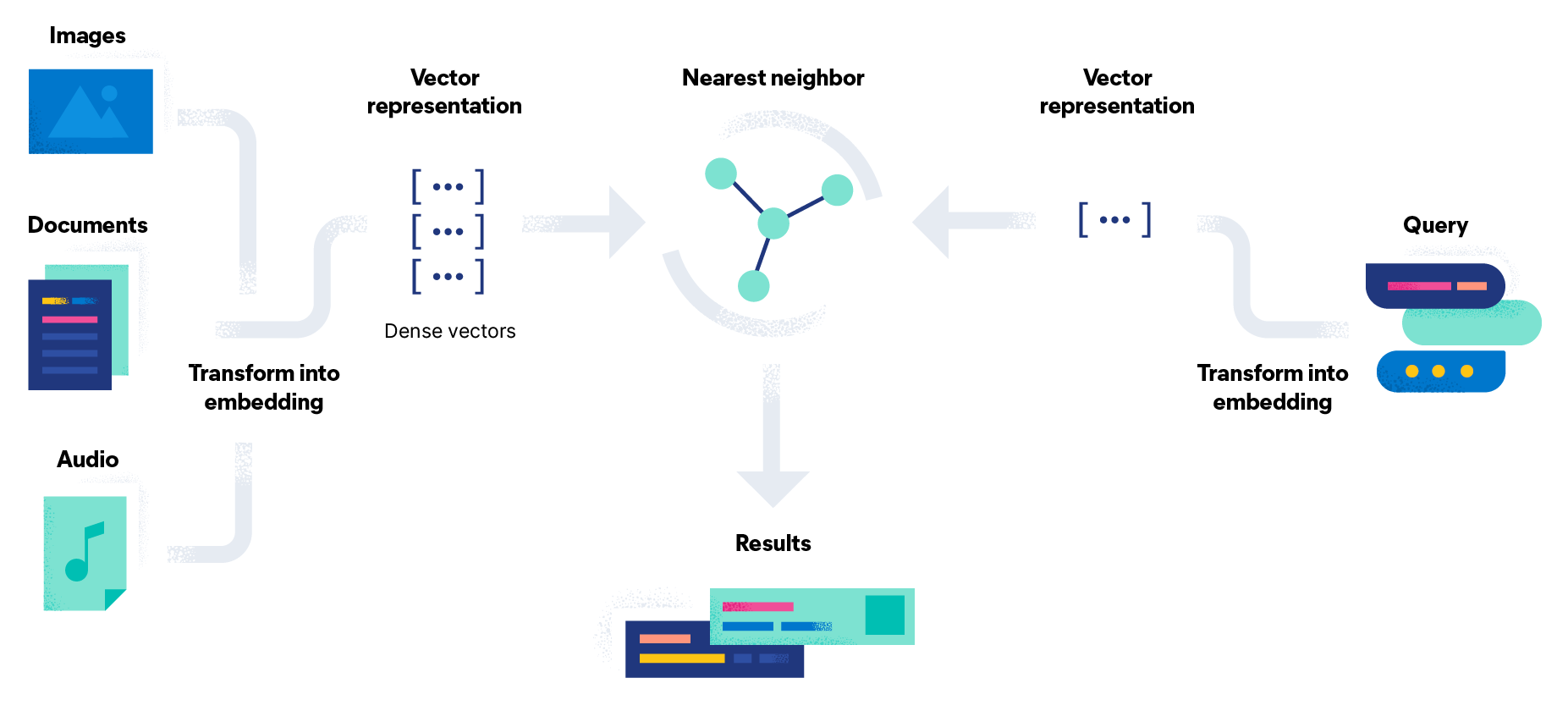
信息检索系统如何工作?
当用户在系统中输入正式查询以说明其信息需求时,通常会触发信息检索过程。信息检索系统会在内容集合或信息数据库中创建文档索引。处理来自文本文件、图像、音频和视频等数据对象,以提取相关术语和替代数据,并使用数据结构来有效地存储和检索这些实体。
当用户提交查询时,系统会处理它以识别相关术语并确定其重要性。然后,系统根据文档与查询的相关性对文档进行排名。在许多情况下,使用信息检索模型和算法来计算一个数值分数,该分数基于集合或数据库中的每个对象与查询的匹配程度。许多查询不会完全匹配:最相关的文档以排名列表的形式呈现给用户。这些排名结果代表了信息检索搜索和数据库搜索之间的关键区别之一。
信息检索系统的主要组成部分
信息检索系统由几个关键组件组成
文档集合
系统可以从中检索信息的文档集。
索引组件
处理源数据和文档以创建索引,将术语和数据映射到包含它们的文档——通常是在专用的、优化的数据结构中。
查询处理器
查询处理器分析用户查询和关键字,并准备它们以与索引实体进行匹配。
排名算法
排名算法确定文档与查询的相关性并为其分配分数。最常见的是 BM25(最佳匹配 25)排名算法,它以其修改后的词频方法而著称,该方法避免了用关键字和重复术语过度饱和文档。
用户界面
用户界面是用户与系统交互、提交查询并呈现结果的显示界面。在这里,可以根据结果对用户查询的满足程度来调整结果。在某些情况下,机制可能允许用户提供有关检索到的文档相关性的反馈,这些反馈可以用于改进未来的检索。
信息检索的优势
信息检索模型的主要优势包括
- 高效的信息访问:最重要的是,信息检索系统为人们节省了无数的时间和精力。信息检索使用户能够快速访问相关信息,而无需手动搜索大量文档和数据。
- 知识发现:信息检索是一个强大的工具,使我们能够理解数据。通过信息检索,用户可以识别数据中可能最初不明显的趋势、模式和关系。
- 个性化:一些信息检索系统可以根据个人用户的偏好和行为,以有意义的方式定制结果。
- 决策支持:当专业人员需要时,他们可以访问最相关的信息,从而做出明智的决策。
信息检索的挑战和局限性
尽管取得了重大进展,但信息检索从未完美。仍然存在已知的问题、挑战和局限性,包括
歧义 自然语言本身就具有歧义性,这使得准确解释用户查询具有挑战性。模糊和不确定性的类似问题可能会影响索引和评估过程,尤其是在图像和视频等对象方面。
相关性 确定相关性是主观的,并且可能因用户上下文和意图而异。用于确定价值和重要性的标准可能受一组不完善的通用标准约束,这些标准不能反映个人用户的特定需求。
语义差距 由于文本表示和人类理解之间的差距,检索系统在捕获内容的更深层含义方面可能会遇到困难。信息和用户表达的模糊性是成功信息检索的主要障碍。由人工智能驱动的先进自然语言处理旨在弥合这些语义和歧义差距。
可扩展性 随着数据量的增加,维护高效且有效的检索和索引变得更加复杂,需要越来越多的资源和计算能力。
信息检索的未来趋势
随着生成式人工智能和机器学习的最新突破,我们所知的信息检索可能正处于变革性变革的边缘。
先进的机器学习技术已经通过从用户交互中学习并适应不断变化的上下文、位置和偏好来增强检索。改进的自然语言处理和语义分析可以更好地理解用户查询和文档内容。检索系统也在不断发展,以便更有效地处理不断增长的多媒体内容。
生成式人工智能对信息检索的影响有可能产生革命性的变化。我们将不会获得我们已经习惯的排名结果列表,该列表需要手动梳理现有链接和文档以找到我们正在寻找的内容,而是会收到对我们问题的实际答案。上下文将从一个问题延续到另一个问题,从而允许进行复杂的、对话式的、多步骤的查询,几乎消除了人类语言处理和意图的障碍。搜索引擎将代替我们完成工作,而不是我们自己拼凑答案,将信息合成为特定的、定制的结果,以原创内容的形式提供我们需要的全部内容,而不是我们不需要的任何内容。
深入了解 2024 年的技术搜索趋势。观看本次网络研讨会,了解最佳实践、新兴方法以及顶级趋势如何在 2024 年影响开发人员。
使用 Elasticsearch 进行信息检索
Elastic 致力于不断改进Elastic Stack 中可用的信息检索功能。我们最新的检索模型Elastic Learned Sparse Encoder使用预训练的语言模型增强了 Elastic 的开箱即用检索。为了实现真正的一键体验,我们已将其与新的Elasticsearch 相关性引擎集成在一起。
Elasticsearch 还具有出色的词汇检索功能和丰富的工具来组合不同查询的结果,这是一种称为混合检索的概念。我们还在使用 NLP 和向量搜索增强聊天机器人功能,发布第三方自然语言处理模型用于文本嵌入,并使用 BEIR 的一个子集评估我们的性能。
下一步应该做什么
当您准备就绪时... 这里有四种方法可以帮助您利用业务数据中的见解
- 开始免费试用,了解 Elastic 如何帮助您的业务。
- 浏览我们的解决方案,了解 Elasticsearch 平台的工作原理以及它们如何满足您的需求。
- 了解如何在企业中交付生成式人工智能.
- 与您认识的喜欢阅读此文章的人分享此文章。通过电子邮件、LinkedIn、Twitter 或 Facebook 与他们分享。