定义
什么是向量搜索?
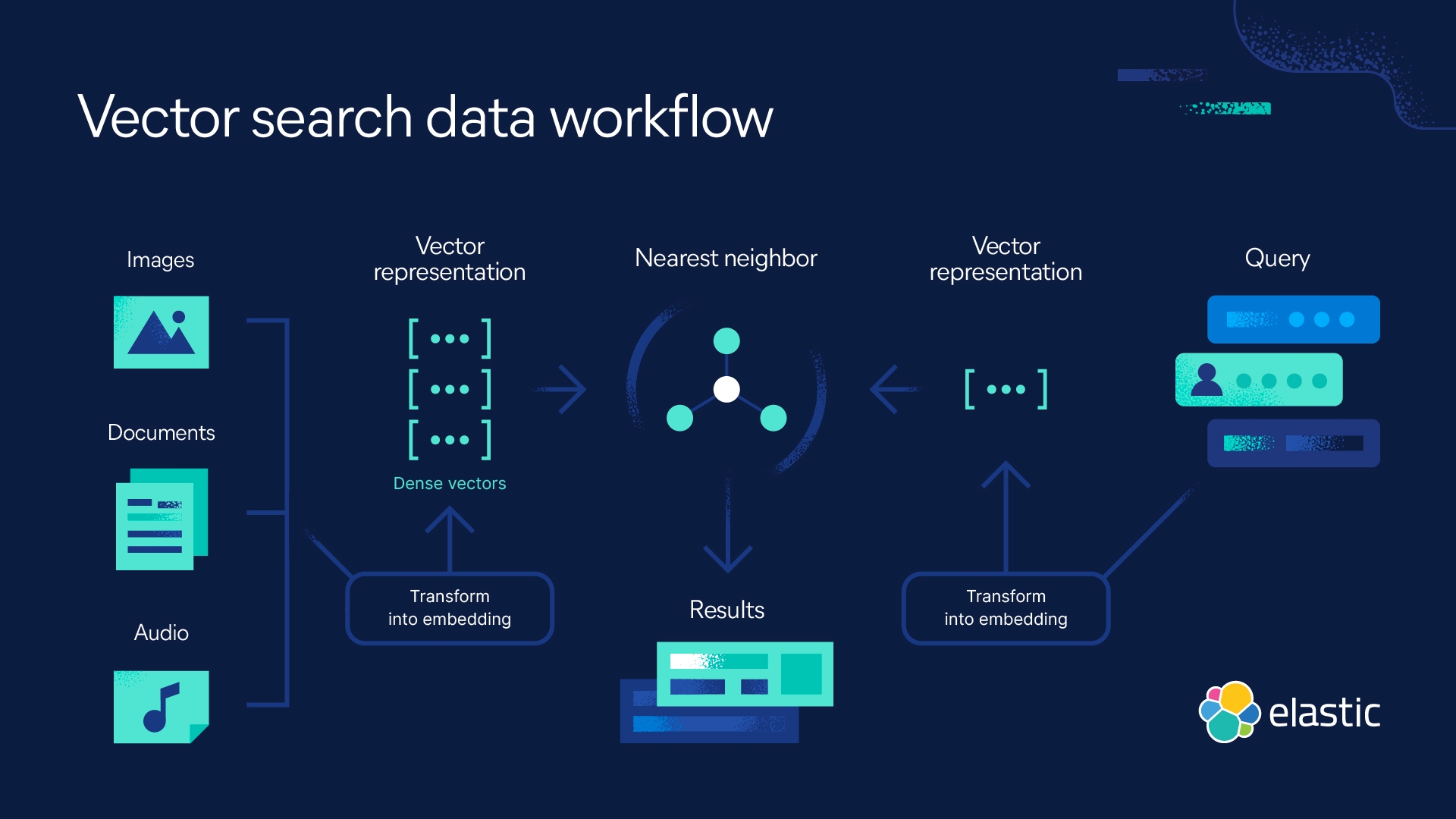
向量搜索利用机器学习 (ML) 来捕获非结构化数据(包括文本和图像)的含义和上下文,并将其转换为数值表示。向量搜索常用于语义搜索,它使用近似最近邻 (ANN) 算法查找相似的数据。与传统的关键字搜索相比,向量搜索可以产生更相关的结果并更快地执行。

为什么向量搜索很重要?
您是否经常遇到想查找某物,但不确定它叫什么的情况?您可能知道它的用途或有相关描述。但如果没有关键字,您只能进行搜索。
向量搜索克服了这一限制,允许您通过您的意思进行搜索。它可以根据相似性搜索快速提供查询答案。这是因为向量嵌入可以捕获文本以外的非结构化数据,如视频、图像和音频。您可以通过将向量搜索与过滤和聚合相结合来优化相关性,从而增强搜索体验,方法是实施混合搜索并将其与传统评分相结合。
向量搜索用例
向量搜索不仅为下一代搜索体验提供动力,还为一系列新的可能性打开了大门。
如何开始
通过 Elastic 轻松实现向量搜索和 NLP
您不必费力就能实现向量搜索并应用 NLP 模型。借助 Elasticsearch Relevance Engine™ (ESRE),您将获得一套用于构建 AI 搜索应用程序的工具包,这些工具包可与生成式 AI 和大型语言模型 (LLM) 一起使用。
借助 ESRE,您可以构建创新的搜索应用程序,生成嵌入,存储和搜索向量,并使用 Elastic 的 Learned Sparse Encoder 实现语义搜索。了解更多关于如何将 Elasticsearch 用作您的向量数据库的信息,或尝试这个自主学习的向量搜索实践课程。


