

什么是向量嵌入?
向量嵌入的类型
有几种不同类型的向量嵌入,它们通常用于各种应用。以下是一些示例:
词嵌入将单个单词表示为向量。Word2Vec、GloVe 和 FastText 等技术通过从大型文本语料库中捕获语义关系和上下文信息来学习词嵌入。
句子嵌入将整个句子表示为向量。诸如通用句子编码器 (USE) 和 SkipThought 之类的模型生成可以捕捉句子整体含义和上下文的嵌入。
文档嵌入将文档(从报纸文章和学术论文到书籍的任何内容)表示为向量。它们捕获整个文档的语义信息和上下文。Doc2Vec 和 Paragraph Vectors 等技术旨在学习文档嵌入。
图像嵌入通过捕获不同的视觉特征将图像表示为向量。卷积神经网络 (CNN) 和 ResNet 和 VGG 等预训练模型等技术会生成图像嵌入,用于图像分类、对象检测和图像相似性等任务。
用户嵌入将系统或平台中的用户表示为向量。它们捕获用户偏好、行为和特征。用户嵌入可用于从推荐系统到个性化营销以及用户细分的各种应用。
产品嵌入将电子商务或推荐系统中的产品表示为向量。它们捕获产品的属性、特征和任何其他可用的语义信息。然后,算法可以使用这些嵌入来根据产品的向量表示进行比较、推荐和分析产品。
嵌入和向量是同一回事吗?
在向量嵌入的上下文中,是的,嵌入和向量是同一回事。两者都指数据的数值表示,其中每个数据点都由高维空间中的向量表示。
术语“向量”仅指具有特定维度的数字数组。在向量嵌入的情况下,这些向量在连续空间中表示上述任何数据点。相反,“嵌入”专门指将数据表示为向量的技术,这种方式可以捕获有意义的信息、语义关系或上下文特征。嵌入旨在捕获数据的底层结构或属性,并且通常通过训练算法或模型来学习。
虽然嵌入和向量在向量嵌入的上下文中可以互换使用,但“嵌入”强调以有意义和结构化的方式表示数据的概念,而“向量”指数字表示本身。
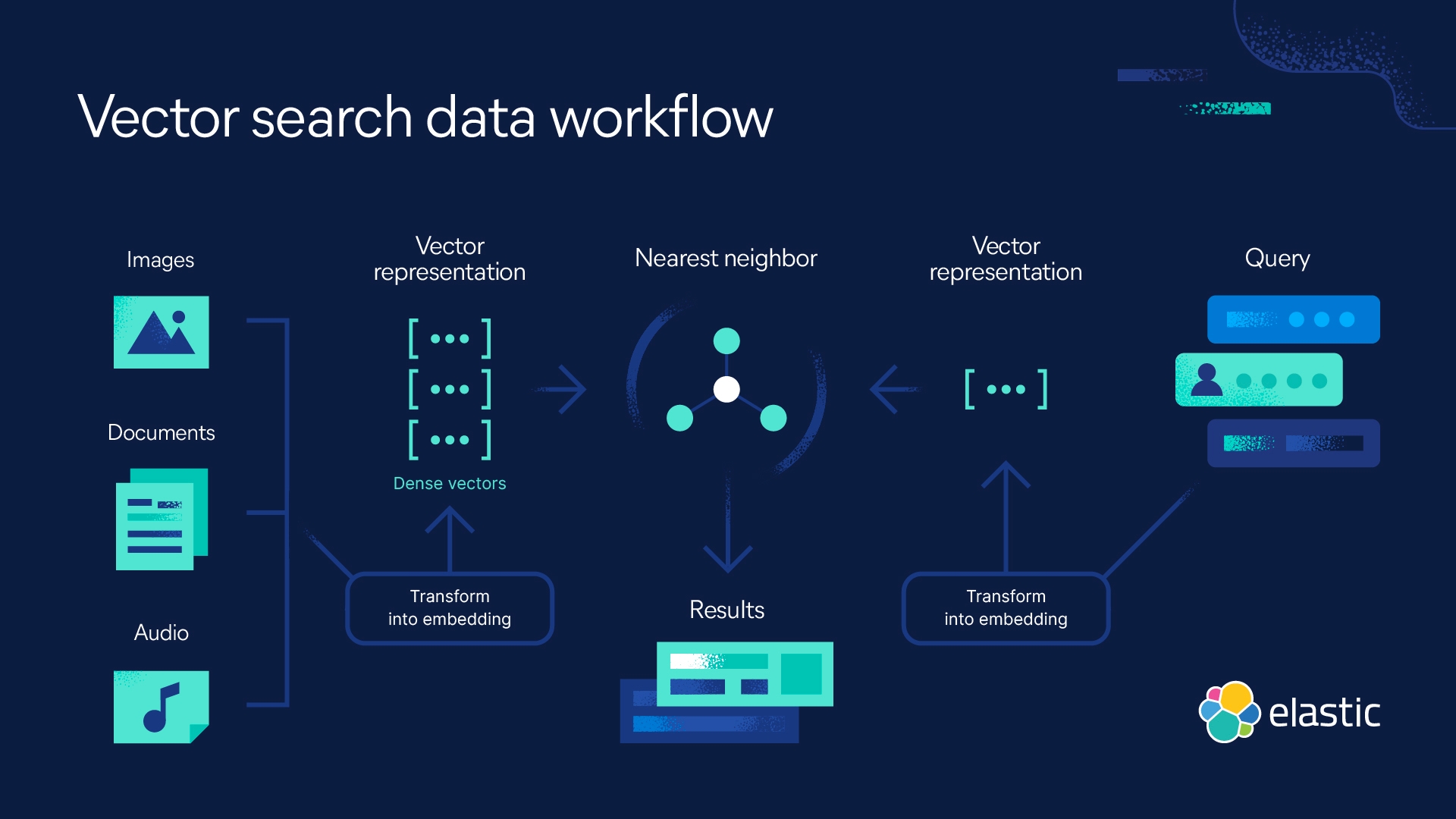
如何创建向量嵌入?
向量嵌入是通过机器学习过程创建的,在该过程中,模型被训练成将上面列出的任何数据片段(以及其他数据片段)转换为数值向量。以下是其工作原理的快速概述:
- 首先,收集一个大型数据集,该数据集表示您要为其创建嵌入的数据类型,例如文本或图像。
- 接下来,您将预处理数据。这需要通过删除噪声、规范化文本、调整图像大小或根据您正在使用的数据类型执行各种其他任务来清理和准备数据。
- 您将选择一个适合您的数据目标的神经网络模型,并将预处理的数据馈送到模型中。
- 该模型通过在训练期间调整其内部参数来学习数据中的模式和关系。例如,它会学习关联经常一起出现的单词,或识别图像中的视觉特征。
- 当模型学习时,它会生成数值向量(或嵌入),这些向量代表数据的含义或特征。每个数据点,例如单词或图像,都由一个唯一的向量表示。
- 此时,您可以通过衡量嵌入在特定任务上的表现或使用人工评估给定结果的相似程度来评估嵌入的质量和有效性。
- 一旦您判断嵌入运行良好,就可以使用它们来分析和处理您的数据集。
向量嵌入是什么样的?
向量的长度或维度取决于您使用的特定嵌入技术以及您希望如何表示数据。例如,如果您正在创建词嵌入,它们的维度通常在几百到几千之间——这对于人类来说太复杂而无法进行可视化图解。句子或文档嵌入可能具有更高的维度,因为它们捕获更复杂的语义信息。
向量嵌入本身通常表示为数字序列,例如 [0.2, 0.8, -0.4, 0.6, ...]。序列中的每个数字都对应于特定的特征或维度,并有助于数据点的整体表示。也就是说,向量中的实际数字本身没有意义。正是数字之间的相对值和关系捕获了语义信息,并使算法能够有效地处理和分析数据。
向量嵌入的应用
向量嵌入在各个领域都有广泛的应用。以下是一些您可能会遇到的常见应用:
自然语言处理 (NLP) 广泛使用向量嵌入来进行情感分析、命名实体识别、文本分类、机器翻译、问题解答和文档相似度等任务。通过使用嵌入,算法可以更有效地理解和处理文本相关的数据。
搜索引擎使用向量嵌入来检索信息并帮助识别语义关系。向量嵌入帮助搜索引擎接收用户查询并返回相关的专题网页、推荐文章、纠正查询中拼写错误的单词,并建议用户可能觉得有用的类似相关查询。此应用程序通常用于支持语义搜索。
个性化推荐系统利用向量嵌入来捕获用户偏好和项目特征。它们帮助将用户配置文件与用户可能也喜欢的项目(例如产品、电影、歌曲或新闻文章)进行匹配,这是基于用户和项目在向量中的紧密匹配。一个熟悉的例子是 Netflix 的推荐系统。有没有想过它是如何选择符合您口味的电影的?它是通过使用项目-项目相似度度量来推荐与用户通常观看内容相似的内容。
视觉内容也可以通过向量嵌入进行分析。在这些类型的向量嵌入上训练的算法可以对图像进行分类、识别物体并在其他图像中检测它们、搜索相似的图像,并将各种图像(以及视频)分类到不同的类别中。Google Lens 使用的图像识别技术是一种常用的图像分析工具。
异常检测算法使用向量嵌入来识别各种数据类型中不寻常的模式或离群值。该算法在表示正常行为的嵌入上进行训练,因此它可以学习识别与正常情况的偏差,这些偏差可以根据嵌入之间的距离或不相似性度量来检测。这在网络安全应用程序中特别方便。
图分析使用图嵌入,其中图是点(称为节点)的集合,由线(称为边)连接。每个节点代表一个实体,例如人、网页或产品,每条边代表这些实体之间的关系或连接。这些向量嵌入可以执行从在社交网络中推荐朋友到检测网络安全异常(如上所述)的所有操作。
音频和音乐也可以被处理和嵌入。向量嵌入捕获音频特征,使算法能够有效地分析音频数据。这可以用于各种应用,如音乐推荐、流派分类、音频相似度搜索、语音识别和说话人验证。
开始使用 Elasticsearch 进行向量嵌入
Elasticsearch 平台将强大的机器学习和人工智能原生集成到解决方案中,帮助您构建使您的用户受益并更快完成工作的应用程序。Elasticsearch 是 Elastic Stack 的核心组件,Elastic Stack 是一组用于数据摄取、丰富、存储、分析和可视化的开源工具。
Elasticsearch 可以帮助您:
- 改善用户体验并提高转化率
- 启用新的见解、自动化、分析和报告
- 提高员工在内部文档和应用程序中的生产力
使用AI Playground,使用您自己的数据体验前沿的 AI 搜索功能。