什么是词嵌入?
词嵌入定义
词嵌入是自然语言处理 (NLP)中使用的一种技术,它将词表示为数字,以便计算机可以处理它们。这是一种用于学习文本数值表示的流行方法。
由于机器需要帮助才能处理单词,因此每个单词都需要被分配一个数字格式才能被处理。 这可以通过几种不同的方法来实现
- 独热编码为文本主体中的每个词分配一个唯一的数字。这个数字被转换为表示该词的二进制向量(使用 0 和 1)。
- 基于计数的表示计算一个词在文本主体中出现的次数,并为其分配一个相应的向量。
- SLIM 组合利用这两种方法,使计算机能够理解词的含义以及它们在文本中出现的频率。
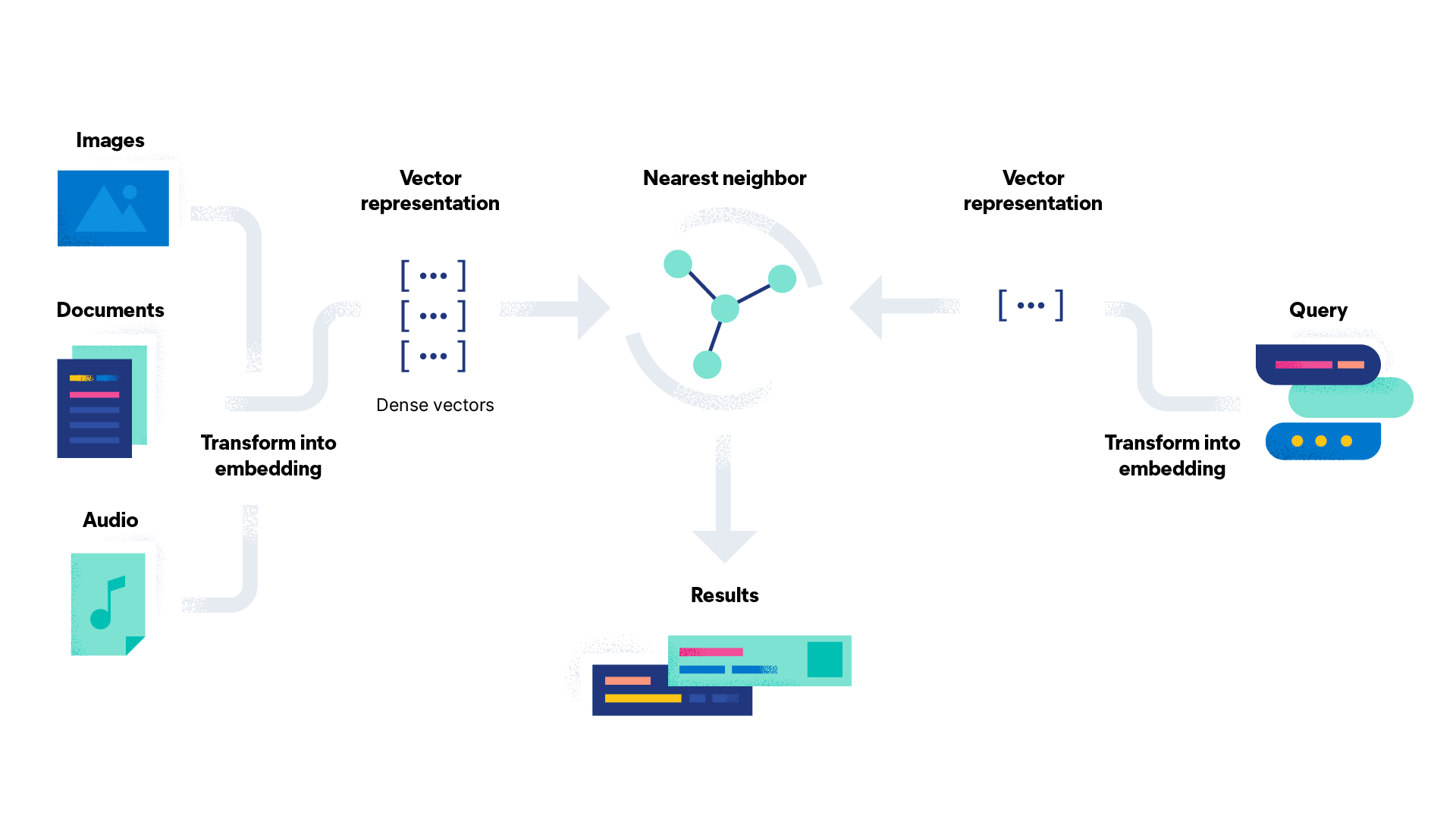
词嵌入创建一个高维空间,其中每个词都被分配一个密集的数字向量(下面会详细介绍)。然后,计算机可以使用这些向量来理解词之间的关系并进行预测。
词嵌入如何在自然语言处理中工作?
词嵌入通过将词表示为高维空间(可能高达 1000 维)中实数的密集向量,在自然语言处理中工作。向量化是将词转换为数值向量的过程。密集向量是指大多数条目都不是零的向量。它与稀疏向量(如独热编码)相反,后者有许多零条目。这个高维空间被称为嵌入空间。
具有相似含义或在相似上下文中使用的词被分配相似的向量,这意味着它们在嵌入空间中彼此靠近。例如,“茶”和“咖啡”是相似的词,它们会彼此靠近,而“茶”和“海”则会相距较远,因为它们的含义不同并且不经常一起使用,即使它们的拼写相似。
虽然在自然语言处理中创建词嵌入的方法有很多种,但它们都涉及在大量称为语料库的文本数据上进行训练。语料库可以有所不同;维基百科和 Google 新闻是用于预训练嵌入语料库的两个常见示例。
语料库也可以是自定义嵌入层,当其他预训练语料库无法提供足够的数据时,该嵌入层专门为用例而设计。在训练期间,模型学习根据该数据中词语的使用模式将每个词与唯一的向量相关联。这些模型可用于将任何新文本数据中的词转换为密集向量。
词嵌入是如何生成的?
词嵌入可以使用多种技术生成。选择哪种技术取决于任务的特定要求。您必须考虑数据集的大小、数据的领域以及语言的复杂性。以下是一些比较流行的词嵌入技术的工作原理
- Word2vec 是一种基于两层神经网络的算法,它输入文本语料库并输出一组向量(因此得名)。一个常用的 Word2vec 例子是“国王 – 男人 + 女人 = 女王”。通过推断“国王”和“男人”之间的关系,以及“男人”和“女人”之间的关系,该算法可以将“女王”识别为与“国王”对应的合适词。Word2vec 使用 Skip-Gram 或连续词袋 (CBOW) 算法进行训练。Skip-Gram 尝试从目标词预测上下文词。连续词袋的功能则相反,使用周围词的上下文来预测目标词。
- GloVe(全局向量)基于这样一种观点,即一个词的含义可以从它在文本语料库中与其他词的共现中推断出来。该算法创建一个共现矩阵,捕捉词语在语料库中一起出现的频率。
- fasText 是 Word2vec 模型的扩展,它基于将词表示为字符 n-gram 或子词单元包而不是单个词的想法。使用类似于 Skip-Gram 的模型,fasText 捕获有关词的内部结构的信息,这有助于它处理新的和不熟悉的词汇。
- ELMo(来自语言模型的嵌入)与上面提到的词嵌入不同,因为它使用一个深度神经网络来分析词出现的整个上下文。这使得它能够捕捉到其他嵌入技术可能无法捕捉到的含义上的细微差别。
- TF-IDF(词频-逆文档频率)是一个数学值,通过将词频 (TF) 与逆文档频率 (IDF) 相乘确定。TF 指的是文档中目标词语与文档中总词语的比率。IDF 是总文档数与包含目标词语的文档数之比的对数。
词嵌入的优势是什么?
与自然语言处理中表示词语的传统方法相比,词嵌入具有多个优势。词嵌入已成为自然语言处理中的标准方法,有许多预训练的嵌入可用于各种应用。这种广泛的可用性使研究人员和开发人员更容易将其纳入模型,而无需从头开始训练它们。
词嵌入已被用于改进语言建模,即预测文本序列中下一个词的任务。通过将词语表示为向量,模型可以更好地捕捉词语出现的上下文,并做出更准确的预测。
构建词嵌入比传统工程技术更快,因为在大型文本语料库上训练神经网络的过程是无监督的,从而节省了时间和精力。一旦训练好嵌入,就可以将其用作各种自然语言处理任务的输入特征,而无需额外的特征工程。
词嵌入的维度通常比独热编码向量低得多。这意味着它们需要更少的内存和计算资源来存储和操作。由于词嵌入是词语的密集向量表示,因此它比稀疏向量技术更有效地表示词语。这也使其能够更好地捕捉词语之间的语义关系。
词嵌入的缺点是什么?
虽然词嵌入有很多优点,但也存在一些值得考虑的缺点。
训练词嵌入的计算成本可能很高,尤其是在使用大型数据集或复杂模型时。预训练的嵌入也可能需要大量的存储空间,这对于资源有限的应用来说可能是一个问题。词嵌入是在有限的词汇表上训练的,这意味着它们可能无法表示该词汇表中不存在的词语。这对于词汇量大的语言或特定于应用程序的术语来说可能是一个问题。
如果词嵌入的数据输入包含偏差,则词嵌入可能会反映这些偏差。例如,词嵌入可以编码性别、种族或其他刻板印象中的偏差,这可能会对其在实际应用中的使用产生影响。
词嵌入通常被认为是黑匣子,因为它们的基础模型(如 GloVe 或 Word2Vec 的神经网络)复杂且难以解释。
词嵌入的质量仅与其训练数据一样好。重要的是要确保数据足以让词嵌入在实践中使用。虽然词嵌入掌握了词语之间的一般关系,但它们可能会错过某些人类的细微差别,例如讽刺,这些细微之处更难识别。
因为词嵌入为每个词分配一个向量,所以它可能会与同形异义词作斗争,同形异义词是指拼写相同但含义不同的词。(例如,“park”这个词,可以指户外空间或停车。)