- Filebeat 参考其他版本
- Filebeat 概述
- 快速入门:安装和配置
- 设置和运行
- 升级
- Filebeat 的工作原理
- 配置
- 输入
- 模块
- 通用设置
- 项目路径
- 配置文件加载
- 输出
- Kerberos
- SSL
- 索引生命周期管理 (ILM)
- Elasticsearch 索引模板
- Kibana 端点
- Kibana 仪表板
- 处理器
- 定义处理器
- add_cloud_metadata
- add_cloudfoundry_metadata
- add_docker_metadata
- add_fields
- add_host_metadata
- add_id
- add_kubernetes_metadata
- add_labels
- add_locale
- add_network_direction
- add_nomad_metadata
- add_observer_metadata
- add_process_metadata
- add_tags
- append
- cache
- community_id
- convert
- copy_fields
- decode_base64_field
- decode_cef
- decode_csv_fields
- decode_duration
- decode_json_fields
- decode_xml
- decode_xml_wineventlog
- decompress_gzip_field
- detect_mime_type
- dissect
- dns
- drop_event
- drop_fields
- extract_array
- fingerprint
- include_fields
- move_fields
- parse_aws_vpc_flow_log
- rate_limit
- registered_domain
- rename
- replace
- script
- syslog
- timestamp
- translate_ldap_attribute
- translate_sid
- truncate_fields
- urldecode
- 自动发现
- 内部队列
- 日志记录
- HTTP 端点
- 正则表达式支持
- 检测
- 功能标志
- filebeat.reference.yml
- 操作指南
- 模块
- 模块概述
- ActiveMQ 模块
- Apache 模块
- Auditd 模块
- AWS 模块
- AWS Fargate 模块
- Azure 模块
- CEF 模块
- Check Point 模块
- Cisco 模块
- CoreDNS 模块
- CrowdStrike 模块
- Cyberark PAS 模块
- Elasticsearch 模块
- Envoyproxy 模块
- Fortinet 模块
- Google Cloud 模块
- Google Workspace 模块
- HAproxy 模块
- IBM MQ 模块
- Icinga 模块
- IIS 模块
- Iptables 模块
- Juniper 模块
- Kafka 模块
- Kibana 模块
- Logstash 模块
- Microsoft 模块
- MISP 模块
- MongoDB 模块
- MSSQL 模块
- MySQL 模块
- MySQL Enterprise 模块
- NATS 模块
- NetFlow 模块
- Nginx 模块
- Office 365 模块
- Okta 模块
- Oracle 模块
- Osquery 模块
- Palo Alto Networks 模块
- pensando 模块
- PostgreSQL 模块
- RabbitMQ 模块
- Redis 模块
- Salesforce 模块
- Santa 模块
- Snyk 模块
- Sophos 模块
- Suricata 模块
- System 模块
- Threat Intel 模块
- Traefik 模块
- Zeek (Bro) 模块
- ZooKeeper 模块
- Zoom 模块
- 导出的字段
- ActiveMQ 字段
- Apache 字段
- Auditd 字段
- AWS 字段
- AWS CloudWatch 字段
- AWS Fargate 字段
- Azure 字段
- Beat 字段
- 解码 CEF 处理器字段
- CEF 字段
- Checkpoint 字段
- Cisco 字段
- 云提供商元数据字段
- Coredns 字段
- Crowdstrike 字段
- CyberArk PAS 字段
- Docker 字段
- ECS 字段
- Elasticsearch 字段
- Envoyproxy 字段
- Fortinet 字段
- Google Cloud Platform (GCP) 字段
- google_workspace 字段
- HAProxy 字段
- 主机字段
- ibmmq 字段
- Icinga 字段
- IIS 字段
- iptables 字段
- Jolokia Discovery 自动发现提供程序字段
- Juniper JUNOS 字段
- Kafka 字段
- kibana 字段
- Kubernetes 字段
- 日志文件内容字段
- logstash 字段
- Lumberjack 字段
- Microsoft 字段
- MISP 字段
- mongodb 字段
- mssql 字段
- MySQL 字段
- MySQL Enterprise 字段
- NATS 字段
- NetFlow 字段
- Nginx 字段
- Office 365 字段
- Okta 字段
- Oracle 字段
- Osquery 字段
- panw 字段
- Pensando 字段
- PostgreSQL 字段
- 进程字段
- RabbitMQ 字段
- Redis 字段
- s3 字段
- Salesforce 字段
- Google Santa 字段
- Snyk 字段
- sophos 字段
- Suricata 字段
- System 字段
- threatintel 字段
- Traefik 字段
- Windows ETW 字段
- Zeek 字段
- ZooKeeper 字段
- Zoom 字段
- 监控
- 安全
- 故障排除
- 获取帮助
- 调试
- 了解记录的指标
- 常见问题
- 在使用 Kubernetes 元数据时提取容器 ID 时出错
- 无法从网络卷读取日志文件
- Filebeat 未从文件中收集行
- 打开的文件句柄过多
- 注册表文件太大
- Inode 重用导致 Filebeat 跳过行
- 日志轮换导致事件丢失或重复
- 打开的文件句柄导致 Windows 文件轮换出现问题
- Filebeat 占用过多 CPU
- Kibana 中的仪表板错误地分解数据字段
- 字段未在 Kibana 可视化中编制索引或可用
- Filebeat 未传输文件的最后一行
- Filebeat 长时间保持已删除文件的打开文件句柄
- Filebeat 使用过多带宽
- 加载配置文件时出错
- 发现意外或未知字符
- Logstash 连接不起作用
- 发布到 Logstash 失败,并显示“connection reset by peer”消息
- @metadata 在 Logstash 中丢失
- 不确定是使用 Logstash 还是 Beats
- SSL 客户端无法连接到 Logstash
- 监控 UI 显示的 Beats 比预期的少
- 仪表板无法定位索引模式
- 由于 MADV 设置导致高 RSS 内存使用率
- 为 Beats 做贡献
管理多行消息
编辑管理多行消息
编辑Filebeat 采集的文件可能包含跨越多行文本的消息。例如,多行消息在包含 Java 堆栈跟踪的文件中很常见。为了正确处理这些多行事件,您需要在 filebeat.yml 文件中配置 multiline 设置,以指定哪些行属于单个事件。
如果您正在将多行事件发送到 Logstash,请使用此处描述的选项来处理多行事件,然后再将事件数据发送到 Logstash。尝试在 Logstash 中实现多行事件处理(例如,使用 Logstash 多行编解码器)可能会导致流的混合和数据损坏。
另请阅读 避免 YAML 格式问题 和 正则表达式支持,以避免常见错误。
配置选项
编辑您可以在 filebeat.yml 配置文件的 filebeat.inputs 部分中指定以下选项,以控制 Filebeat 如何处理跨越多行的消息。
以下示例显示了如何在 Filebeat 中配置 filestream 输入以处理多行消息,其中消息的第一行以括号 ([) 开头。
请注意,以下示例仅适用于 filestream 输入,而不适用于 log 输入。
parsers: - multiline: type: pattern pattern: '^\[' negate: true match: after
如果您仍然使用已弃用的 log 输入,则无需使用 parsers。
multiline.type: pattern multiline.pattern: '^\[' multiline.negate: true multiline.match: after
Filebeat 会将所有不以 [ 开头的行与之前以 [ 开头的行组合在一起。例如,您可以使用此配置将多行消息的以下行合并为单个事件
[beat-logstash-some-name-832-2015.11.28] IndexNotFoundException[no such index] at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver$WildcardExpressionResolver.resolve(IndexNameExpressionResolver.java:566) at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:133) at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:77) at org.elasticsearch.action.admin.indices.delete.TransportDeleteIndexAction.checkBlock(TransportDeleteIndexAction.java:75)
-
multiline.type - 定义要使用的聚合方法。默认值为
pattern。其他选项是count,它允许您聚合固定数量的行,以及while_pattern,它通过模式聚合行,而无需匹配选项。 -
multiline.pattern - 指定要匹配的正则表达式模式。请注意,Filebeat 支持的正则表达式模式与 Logstash 支持的模式略有不同。有关支持的正则表达式模式的列表,请参阅 正则表达式支持。根据您如何配置其他多行选项,匹配指定正则表达式的行被视为前一行的延续或新多行事件的开始。您可以设置
negate选项来否定该模式。 -
multiline.negate - 定义是否否定该模式。默认值为
false。 -
multiline.match -
指定 Filebeat 如何将匹配的行组合成一个事件。设置值为
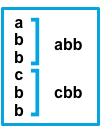
after或before。这些设置的行为取决于您为negate指定的值negate的设置match的设置结果 示例 pattern: ^bfalseafter与该模式匹配的连续行将附加到前一个不匹配的行。
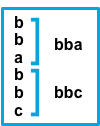
falsebefore与该模式匹配的连续行将附加到下一个不匹配的行的前面。
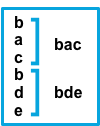
trueafter与该模式不匹配的连续行将附加到前一个匹配的行。
truebefore与该模式不匹配的连续行将附加到下一个匹配的行的前面。
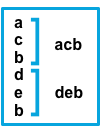
after设置等效于 Logstash 中的previous,而before等效于next。 -
multiline.flush_pattern - 指定一个正则表达式,其中当前多行将从内存中刷新,从而结束多行消息。仅适用于
pattern类型。 -
multiline.max_lines - 可以组合成一个事件的最大行数。如果多行消息包含的行数超过
max_lines,则会丢弃任何其他行。默认值为 500。 -
multiline.timeout - 在指定的超时时间之后,Filebeat 会发送多行事件,即使没有找到新模式来启动新事件。默认值为 5 秒。
-
multiline.count_lines - 要聚合到单个事件的行数。
-
multiline.skip_newline - 设置后,多行事件将不使用行分隔符进行连接。
多行配置示例
编辑本节中的示例涵盖以下用例
- 将 Java 堆栈跟踪合并为单个事件
- 将 C 风格的行延续合并为单个事件
- 合并来自带时间戳事件的多行
Java 堆栈跟踪
编辑Java 堆栈跟踪由多行组成,初始行之后的每一行都以空格开头,如本示例中所示
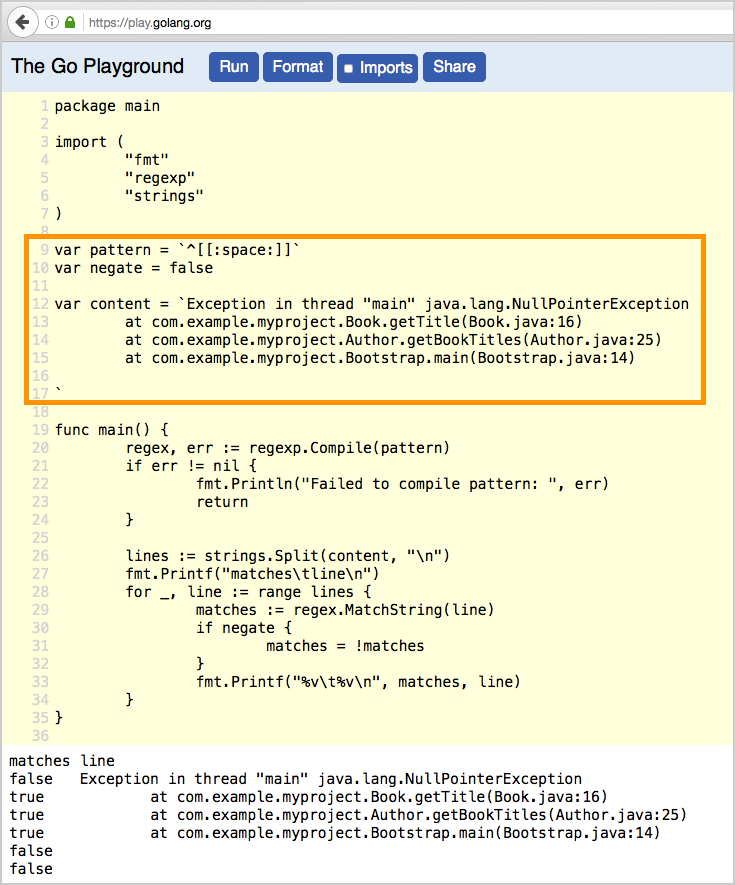
Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book.java:16) at com.example.myproject.Author.getBookTitles(Author.java:25) at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
要在 Filebeat 中将这些行整合到单个事件中,请将以下多行配置与 filestream 一起使用
parsers: - multiline: type: pattern pattern: '^[[:space:]]' negate: false match: after
使用 log 输入
multiline.type: pattern multiline.pattern: '^[[:space:]]' multiline.negate: false multiline.match: after
此配置将任何以空格开头的行合并到前一行。
这是一个 Java 堆栈跟踪,它提供了一个稍微复杂的示例
Exception in thread "main" java.lang.IllegalStateException: A book has a null property at com.example.myproject.Author.getBookIds(Author.java:38) at com.example.myproject.Bootstrap.main(Bootstrap.java:14) Caused by: java.lang.NullPointerException at com.example.myproject.Book.getId(Book.java:22) at com.example.myproject.Author.getBookIds(Author.java:35) ... 1 more
要在 Filebeat 中将这些行整合到单个事件中,请将以下多行配置与 filestream 一起使用
parsers: - multiline: type: pattern pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:' negate: false match: after
使用 log 输入
multiline.type: pattern multiline.pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:' multiline.negate: false multiline.match: after
在此示例中,该模式匹配以下行
- 以空格开头,后跟单词
at或...的行 - 以单词
Caused by:开头的行
行延续
编辑几种编程语言在行尾使用反斜杠 (\) 字符来表示该行继续,如本示例中所示
printf ("%10.10ld \t %10.10ld \t %s\ %f", w, x, y, z );
要在 Filebeat 中将这些行整合到单个事件中,请将以下多行配置与 filestream 一起使用
parsers: - multiline: type: pattern pattern: '\\$' negate: false match: before
使用 log 输入
multiline.type: pattern multiline.pattern: '\\$' multiline.negate: false multiline.match: before
此配置将任何以 \ 字符结尾的行与后面的行合并。
时间戳
编辑来自 Elasticsearch 等服务的活动日志通常以时间戳开头,后跟有关特定活动的信息,如本示例中所示
[2015-08-24 11:49:14,389][INFO ][env ] [Letha] using [1] data paths, mounts [[/ (/dev/disk1)]], net usable_space [34.5gb], net total_space [118.9gb], types [hfs]
要在 Filebeat 中将这些行整合到单个事件中,请将以下多行配置与 filestream 一起使用
parsers: - multiline: type: pattern pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}' negate: true match: after
使用 log 输入
multiline.type: pattern multiline.pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}' multiline.negate: true multiline.match: after
此配置使用 negate: true 和 match: after 设置来指定任何与指定模式不匹配的行都属于前一行。
应用程序事件
编辑有时,您的应用程序日志包含事件,这些事件以自定义标记开头和结尾,如以下示例所示
[2015-08-24 11:49:14,389] Start new event [2015-08-24 11:49:14,395] Content of processing something [2015-08-24 11:49:14,399] End event
要在 Filebeat 中将其整合为单个事件,请将以下多行配置与 filestream 一起使用
parsers: - multiline: type: pattern pattern: 'Start new event' negate: true match: after flush_pattern: 'End event'
使用 log 输入
multiline.type: pattern multiline.pattern: 'Start new event' multiline.negate: true multiline.match: after multiline.flush_pattern: 'End event'
flush_pattern 选项指定一个正则表达式,在该正则表达式处将刷新当前多行。如果您认为 pattern 选项指定事件的开头,则 flush_pattern 选项将指定事件的结尾或最后一行。
如果开始/结束日志块与非多行日志混合,或者不同的开始/结束日志块相互重叠,则此示例将无法正常工作。例如,以下示例中的 Some other log 日志行将被合并到单个多行文档中,因为它们既不匹配 multiline.pattern 也不匹配 multiline.flush_pattern,并且 multiline.negate 设置为 true。
[2015-08-24 11:49:14,389] Start new event [2015-08-24 11:49:14,395] Content of processing something [2015-08-24 11:49:14,399] End event [2015-08-24 11:50:14,389] Some other log [2015-08-24 11:50:14,395] Some other log [2015-08-24 11:50:14,399] Some other log [2015-08-24 11:51:14,389] Start new event [2015-08-24 11:51:14,395] Content of processing something [2015-08-24 11:51:14,399] End event
测试您的多行正则表达式模式
编辑为了方便您测试多行配置中的正则表达式模式,我们创建了一个 Go Playground。您只需插入正则表达式模式以及您计划使用的 multiline.negate 设置,并在内容反引号 (` `) 之间粘贴示例消息。然后单击“运行”,您将看到消息中的哪些行与您指定的配置匹配。例如