部署 Elastic Serverless Forwarder
编辑部署 Elastic Serverless Forwarder
编辑要部署 Elastic Serverless Forwarder,您需要:
先决条件
编辑本文档假定您已熟悉 AWS 服务,并且已正确创建和配置必要的 AWS 对象。
此页面描述了部署 AWS Elastic Serverless Forwarder 的基本步骤—有关权限和自动路由以及数据解析和丰富等配置主题的更多信息,请参阅 配置选项。
直接部署(无需 SAR)
编辑如果通过 Serverless Application Repository (SAR) 部署时提供的自定义选项不足,则从 1.6.0 版本及更高版本开始,您可以 直接将 Elastic Serverless Forwarder 部署 到您的 AWS 账户,无需使用 SAR。这使您可以逐个自定义输入(即触发器)的事件源设置。
在 Kibana 中安装 AWS 集成资源
编辑- 在 Kibana 中转到 集成 并搜索 AWS(或选择 AWS 类别以过滤列表)。
- 单击 AWS 集成,选择 设置,然后单击 安装 AWS 资源 并确认以安装所有 AWS 集成资源。
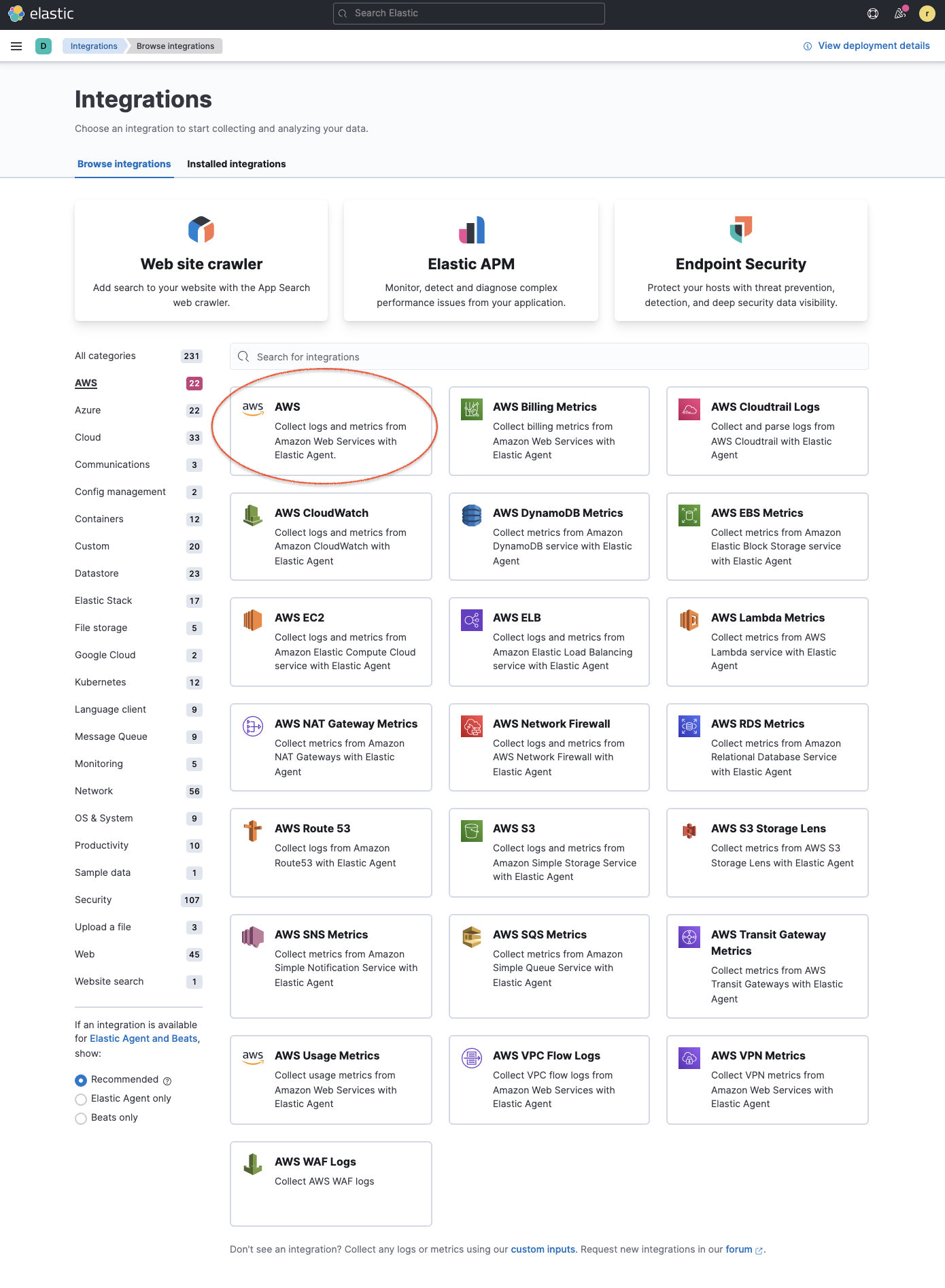
从 Kibana 添加集成可提供适当的预构建仪表板、摄取节点配置和其他资源,以帮助您充分利用摄取的数据。这些集成使用具有特定 命名约定 的 数据流,为您提供更精细的控制和灵活性来管理数据摄取。
我们建议使用集成资源入门,但转发器支持写入任何索引、别名或自定义数据流。这使现有的 Elasticsearch 用户能够重复使用已创建并连接到现有流程或系统的索引模板、摄取管道或仪表板。如果您已经拥有打算将数据发送到的现有索引或数据流,则可以跳过此部署步骤。
创建并上传 config.yaml 到 S3 存储桶
编辑Elastic Serverless Forwarder 需要将 config.yaml 文件上传到 S3 存储桶,并由 S3_CONFIG_FILE 环境变量引用。
将以下 YAML 内容保存为 config.yaml,并在上传到 S3 存储桶之前根据需要进行编辑。您应该删除任何未使用输入或参数,并确保已根据内联注释输入正确的 URL 和凭据。
inputs: - type: "s3-sqs" id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" outputs: - type: "elasticsearch" args: # either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included elasticsearch_url: "http(s)://domain.tld:port" cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA==" # either api_key or username/password, username/password takes precedence if both are included api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo=" username: "username" password: "password" es_datastream_name: "logs-generic-default" es_dead_letter_index: "esf-dead-letter-index" # optional batch_max_actions: 500 # optional: default value is 500 batch_max_bytes: 10485760 # optional: default value is 10485760 - type: "logstash" args: logstash_url: "http(s)://host:port" username: "username" #optional password: "password" #optional max_batch_size: 500 #optional compression_level: 1 #optional ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional - type: "sqs" id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" outputs: - type: "elasticsearch" args: # either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included elasticsearch_url: "http(s)://domain.tld:port" cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA==" # either api_key or username/password, username/password takes precedence if both are included api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo=" username: "username" password: "password" es_datastream_name: "logs-generic-default" es_dead_letter_index: "esf-dead-letter-index" # optional batch_max_actions: 500 # optional: default value is 500 batch_max_bytes: 10485760 # optional: default value is 10485760 - type: "logstash" args: logstash_url: "http(s)://host:port" username: "username" #optional password: "password" #optional max_batch_size: 500 #optional compression_level: 1 #optional ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional - type: "kinesis-data-stream" id: "arn:aws:kinesis:%REGION%:%ACCOUNT%:stream/%STREAMNAME%" outputs: - type: "elasticsearch" args: # either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included elasticsearch_url: "http(s)://domain.tld:port" cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA==" # either api_key or username/password, username/password takes precedence if both are included api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo=" username: "username" password: "password" es_datastream_name: "logs-generic-default" es_dead_letter_index: "esf-dead-letter-index" # optional batch_max_actions: 500 # optional: default value is 500 batch_max_bytes: 10485760 # optional: default value is 10485760 - type: "logstash" args: logstash_url: "http(s)://host:port" username: "username" #optional password: "password" #optional max_batch_size: 500 #optional compression_level: 1 #optional ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional - type: "cloudwatch-logs" id: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:*" outputs: - type: "elasticsearch" args: # either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included elasticsearch_url: "http(s)://domain.tld:port" cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA==" # either api_key or username/password, username/password takes precedence if both are included api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo=" username: "username" password: "password" es_datastream_name: "logs-generic-default" es_dead_letter_index: "esf-dead-letter-index" # optional batch_max_actions: 500 # optional: default value is 500 batch_max_bytes: 10485760 # optional: default value is 10485760 - type: "logstash" args: logstash_url: "http(s)://host:port" username: "username" #optional password: "password" #optional max_batch_size: 500 #optional compression_level: 1 #optional ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional - type: "cloudwatch-logs" id: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:log-stream:%LOG_STREAM_NAME%" outputs: - type: "elasticsearch" args: # either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included elasticsearch_url: "http(s)://domain.tld:port" cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA==" # either api_key or username/password, username/password takes precedence if both are included api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo=" username: "username" password: "password" es_datastream_name: "logs-generic-default" es_dead_letter_index: "esf-dead-letter-index" # optional batch_max_actions: 500 # optional: default value is 500 batch_max_bytes: 10485760 # optional: default value is 10485760 - type: "logstash" args: logstash_url: "http(s)://host:port" username: "username" #optional password: "password" #optional max_batch_size: 500 #optional compression_level: 1 #optional ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional
所有 1.14.0(含)之前的版本每个类型只允许一个输出。因此,如果用户选择的 output.type 为 elasticsearch,则用户只能为此配置一个输出。
字段
编辑inputs.[]:
Elastic Serverless Forwarder Lambda 函数的输入(即触发器)列表。
inputs.[].type:
触发器输入的类型(目前支持 cloudwatch-logs、kinesis-data-stream、sqs 和 s3-sqs)。
inputs.[].id:
根据类型的触发器输入的 ARN。多个输入条目可以具有不同类型的唯一 ID。类型为 cloudwatch-logs 的输入同时接受 CloudWatch Logs 日志组和 CloudWatch Logs 日志流 ARN。
inputs.[].outputs:
Elastic Serverless Forwarder Lambda 函数的输出(即转发目标)列表。您可以为一个输入设置多个输出,但每个类型只能定义一个输出。
inputs.[].outputs.[].type:
转发目标输出的类型。目前仅支持以下输出:
-
elasticsearch -
[预览] 此功能处于技术预览阶段,可能在将来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 的约束。
logstash
每个类型最多只能用于一个输出(直至 1.14.0 版本)。如果选择 Logstash 作为输出,则 Elastic Serverless Forwarder 预期已安装、启用并正确配置 elastic_serverless_forwarder Logstash 输入。有关安装 Logstash 插件的更多信息,请参阅 Logstash 文档。
inputs.[].outputs.[].args:指定转发目标输出的自定义初始化参数。
对于 elasticsearch,支持以下参数:
-
args.elasticsearch_url:elasticsearch 端点的 URL,格式为http(s)://domain.tld:port。当未提供args.cloud_id时,此参数为必填项。如果同时定义了这两个参数,则此参数优先于args.cloud_id。 -
args.cloud_id:elasticsearch 端点的云 ID。当未提供args.elasticsearch_url时,此参数为必填项。如果定义了args.elasticsearch_url,则此参数将被忽略。 -
args.username:要连接到的 elasticsearch 实例的用户名。当未提供args.api_key时,此参数为必填项。如果同时定义了这两个参数,则此参数优先于args.api_key。 -
args.password:要连接到的 elasticsearch 实例的密码。当未提供args.api_key时,此参数为必填项。如果同时定义了这两个参数,则此参数优先于args.api_key。 -
args.api_key:elasticsearch 端点的 API 密钥,格式为base64encode(api_key_id:api_key_secret)。当未提供args.username和args.password时,此参数为必填项。如果定义了args.username/args.password,则此参数将被忽略。 -
args.es_datastream_name:应将日志转发到的数据流或索引的名称。Lambda 支持将各种 AWS 服务日志自动路由到相应的数据流,以便在 Elasticsearch 集群中进行进一步处理和存储。它支持aws.cloudtrail、aws.cloudwatch_logs、aws.elb_logs、aws.firewall_logs、aws.vpcflow和aws.waf日志的自动路由。对于其他日志类型,如果使用数据流,您可以根据数据流的命名约定和可用的集成在配置文件中选择性地设置其值。如果未指定es_datastream_name且无法与任何上述 AWS 服务匹配,则该值将设置为logs-generic-default。在 v0.29.1 及更低版本中,此配置参数名为es_index_or_datastream_name。将config.yaml文件中 S3 存储桶中的配置参数重命名为es_datastream_name以便在将来的版本中继续使用它。从 v0.30.0 版本开始,旧名称es_index_or_datastream_name已弃用。相关的向后兼容代码已从 v1.0.0 版本中删除。 -
args.es_dead_letter_index:如果索引到args.es_datastream_name返回错误,则应将日志重定向到的数据流或索引的名称。elasticsearch 输出不会将可重试错误(连接故障、HTTP 状态代码 429)转发到死信索引。 -
args.batch_max_actions:(可选)在单个批量请求中发送的最大操作数。默认值:500。 -
args.batch_max_bytes:(可选)在单个批量请求中发送的最大大小(字节)。默认值:10485760(10MB)。 -
args.ssl_assert_fingerprint:(可选)HTTPS 传输中自签名 SSL 证书的 SSL 指纹。默认值为一个空字符串,这意味着 HTTP 客户端需要一个有效的证书。-
以下是死信索引中索引的示例错误:
{ "@timestamp": "2024-10-07T05:57:59.448925Z", "message": "{\"hey\":{\"message\":\"hey there\"},\"_id\":\"e6542822-4583-438d-9b4d-1a3023b5eeb9\",\"_op_type\":\"create\",\"_index\":\"logs-succeed.pr793-default\"}", "error": { "message": "[1:30] failed to parse field [hey] of type [keyword] in document with id 'e6542822-4583-438d-9b4d-1a3023b5eeb9'. Preview of field's value: '{message=hey there}'", "type": "document_parsing_exception" }, "http": { "response": { "status_code": 400 } } }
-
对于 logstash,支持以下参数:
-
args.logstash_url:Logstash 端点的 URL,格式为http(s)://host:port -
args.username:(可选)要连接到的 Logstash 实例的用户名。如果在 Logstash 中启用了 HTTP 基本身份验证,则此参数为必填项。 -
args.password:(可选)要连接到的 Logstash 实例的密码。如果在 Logstash 中启用了 HTTP 基本身份验证,则此参数为必填项。 -
args.max_batch_size:(可选)在单个 HTTP(s) 请求中发送的事件的最大数量。默认值:500 -
args.compression_level:(可选)对 Logstash 的 HTTP(s) 请求的 GZIP 压缩级别。它可以是 1(最小压缩,最佳性能,发送的字节数最多)到 9(最大压缩,最差性能,发送的字节数最少)之间的任何整数值。默认值:1 -
args.ssl_assert_fingerprint:(可选)HTTPS 传输中自签名 SSL 证书的 SSL 指纹。默认值为一个空字符串,这意味着 HTTP 客户端需要一个有效的证书。
定义部署参数
编辑无论您选择哪种 SAR 部署方法,都必须为您的设置正确定义以下参数。本节解释参数的类型,并提供有关如何设置参数以匹配您的部署的指导。
常规配置
编辑这些参数定义转发器的常规配置和行为。
-
ElasticServerlessForwarderS3ConfigFile:将此值设置为S3 URL格式的config.yaml位置:s3://bucket-name/config-file-name。这将填充转发器的S3_CONFIG_FILE环境变量。 -
ElasticServerlessForwarderSSMSecrets:添加在config.yml中使用的AWS SSM Secrets ARN的逗号分隔列表(如有)。 -
ElasticServerlessForwarderKMSKeys:添加用于解密AWS SSM Secrets、Kinesis Data Streams、SQS队列或S3存储桶(如有)的AWS KMS Keys ARN的逗号分隔列表。
确保包含用于加密数据的全部KMS密钥。例如,S3存储桶通常是加密的,因此Lambda函数需要访问该密钥才能获取对象。
输入
编辑这些参数定义您特定的输入或事件触发器。
-
ElasticServerlessForwarderSQSEvents:添加直接SQS队列ARN的逗号分隔列表,将其设置为转发器的事件触发器(如有)。 -
ElasticServerlessForwarderSQSEvents2:添加直接SQS队列ARN的逗号分隔列表,将其设置为转发器的事件触发器(如果ElasticServerlessForwarderSQSEvents达到限制)。 -
ElasticServerlessForwarderS3SQSEvents:添加S3 SQS事件通知ARN的逗号分隔列表,将其设置为转发器的事件触发器(如有)。 -
ElasticServerlessForwarderS3SQSEvents2:添加S3 SQS事件通知ARN的逗号分隔列表,将其设置为转发器的事件触发器(如果ElasticServerlessForwarderS3SQSEvents达到限制)。 -
ElasticServerlessForwarderKinesisEvents:添加Kinesis Data Stream ARN的逗号分隔列表,将其设置为转发器的事件触发器(如有)。 -
ElasticServerlessForwarderKinesisEvents2:添加Kinesis Data Stream ARN的逗号分隔列表,将其设置为转发器的事件触发器(如果ElasticServerlessForwarderKinesisEvents达到限制)。 -
ElasticServerlessForwarderCloudWatchLogsEvents:添加Cloudwatch Logs日志组ARN的逗号分隔列表,以在转发器上设置订阅筛选器(如有)。 -
ElasticServerlessForwarderCloudWatchLogsEvents2:添加Cloudwatch Logs日志组ARN的逗号分隔列表,以在转发器上设置订阅筛选器(如果ElasticServerlessForwarderCloudWatchLogsEvents达到限制)。
确保引用config.yaml中指定的ARN,并将任何未使用的输入设置留空。
S3存储桶权限
编辑这些参数定义访问关联的S3存储桶所需的权限。
-
ElasticServerlessForwarderS3Buckets:添加作为S3 SQS事件通知源的S3存储桶ARN的逗号分隔列表(如有)。
网络
编辑要将Elastic Serverless Forwarder附加到特定的AWS VPC,请指定属于AWS VPC的安全组ID和子网ID。此要求与CloudFormation VPCConfig属性相关。
这些是参数
-
ElasticServerlessForwarderSecurityGroups:添加要附加到转发器的安全组ID的逗号分隔列表。 -
ElasticServerlessForwarderSubnets:添加转发器的子网ID的逗号分隔列表。
要将Elastic Serverless Forwarder附加到特定的AWS VPC,这两个参数都是必需的。如果您不希望转发器属于任何特定的AWS VPC,请将这两个参数留空。
如果Elastic Serverless Forwarder附加到VPC,则需要为S3和SQS,以及为转发器定义的每个服务创建VPC端点。无论使用输入,都需要S3和SQS VPC端点来读取上传到S3的config.yaml和管理持续队列和重放队列。如果您使用Amazon CloudWatch Logs订阅筛选器,则还需要为EC2创建VPC端点。
请参阅AWS PrivateLink流量筛选器文档,查找您的VPC端点ID和要在config.yml中使用的主机名,以便通过PrivateLink访问您的Elasticsearch集群。
从Terraform部署Elastic Serverless Forwarder
编辑部署ESF的terraform文件可在esf-terraform存储库中找到。部署这些文件有两个要求:curl和terraform。请参阅README文件以了解如何使用它。
从SAR部署Elastic Serverless Forwarder
编辑通过AWS Serverless Application Repository (SAR)提供几种部署方法
要直接部署转发器而不使用SAR,请参阅直接部署Elastic Serverless Forwarder
使用AWS控制台部署
编辑直接使用AWS控制台时,每个区域只允许一次部署。
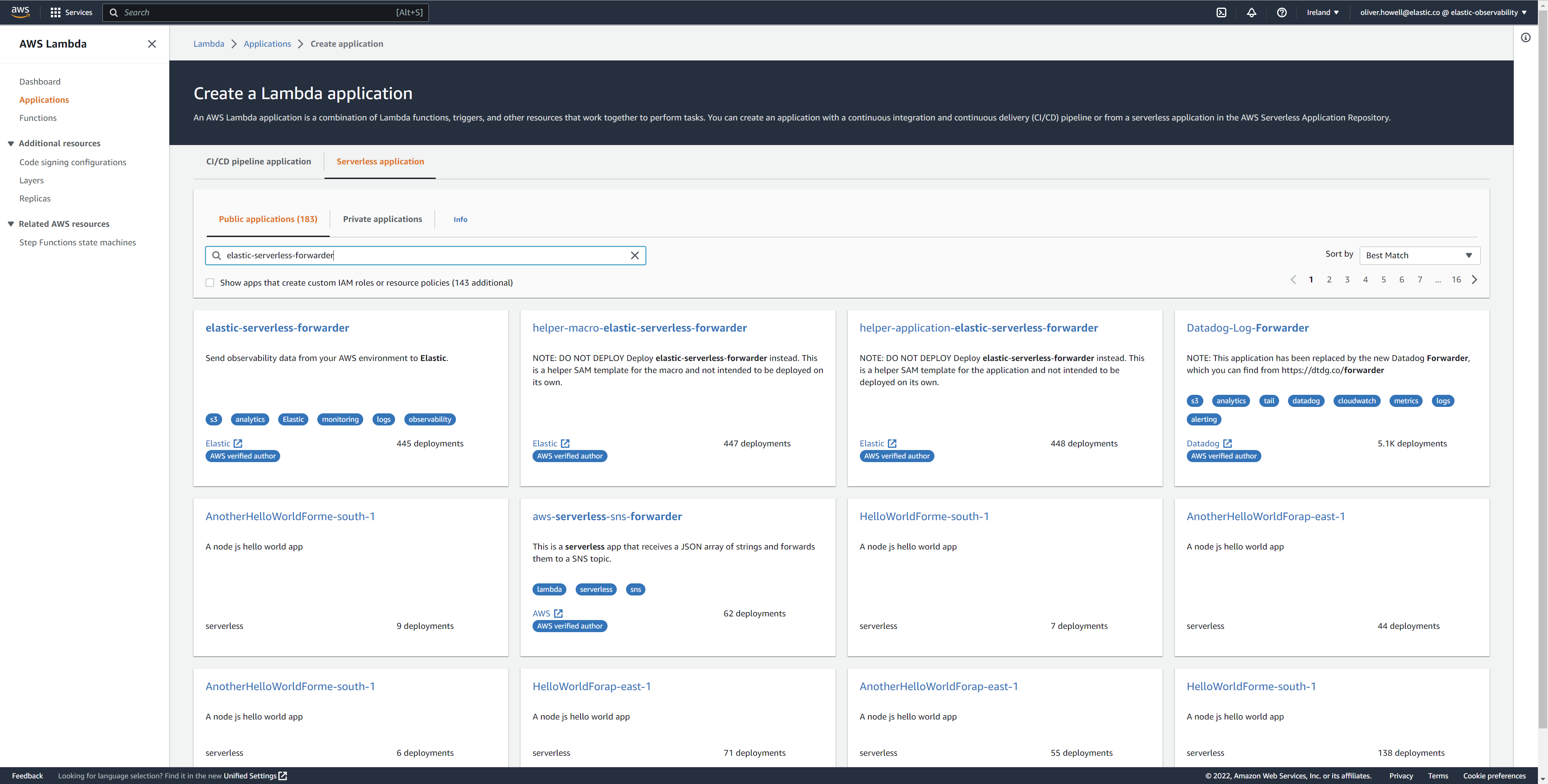
- 登录到AWS控制台并打开Lambda。
- 单击应用程序,然后单击创建应用程序。
- 单击无服务器应用程序并搜索elastic-serverless-forwarder。
-
从搜索结果中选择elastic-serverless-forwarder(忽略任何以helper-开头的应用程序)。
- 根据定义部署参数完成应用程序设置。即使这些参数已存在于
config.yaml文件中,也必须指定它们。根据输入类型,至少应定义一个参数ElasticServerlessForwarderSQSEvents、ElasticServerlessForwarderS3SQSEvents、ElasticServerlessForwarderKinesisEvents、ElasticServerlessForwarderCloudWatchLogsEvents。 - 添加设置后,单击部署。
- 在serverlessrepo-elastic-serverless-forwarder的应用程序页面上,单击部署。
- 刷新部署历史记录,直到看到
创建完成状态更新。部署大约需要5分钟——如果部署由于任何原因失败,创建事件将回滚,您将能够看到哪个事件失败的说明。 -
(可选) 为您的新部署启用Elastic APM检测
- 在AWS控制台中转到Lambda > 函数,找到并选择带有serverlessrepo-的函数。
- 转到配置选项卡并选择环境变量
-
添加以下环境变量
| Key | Value | |---------------------------|--------| |`ELASTIC_APM_ACTIVE` | `true` | |`ELASTIC_APM_SECRET_TOKEN` | token | |`ELASTIC_APM_SERVER_URL` | url |
如果您已经成功部署了转发器,但想要更新应用程序(例如,如果发布了Lambda函数的新版本),则应再次执行此部署步骤并使用相同的应用程序名称。这将确保函数更新而不是重复或重新创建。
使用Cloudformation部署
编辑-
使用以下代码获取最新应用程序的语义版本
aws serverlessrepo list-application-versions --application-id arn:aws:serverlessrepo:eu-central-1:267093732750:applications/elastic-serverless-forwarder
-
将以下YAML内容保存为
sar-application.yaml,并根据定义部署参数填写正确的参数Transform: AWS::Serverless-2016-10-31 Resources: SarCloudformationDeployment: Type: AWS::Serverless::Application Properties: Location: ApplicationId: 'arn:aws:serverlessrepo:eu-central-1:267093732750:applications/elastic-serverless-forwarder' SemanticVersion: '%SEMANTICVERSION%' ## SET TO CORRECT SEMANTIC VERSION (MUST BE GREATER THAN 1.6.0) Parameters: ElasticServerlessForwarderS3ConfigFile: "" ElasticServerlessForwarderSSMSecrets: "" ElasticServerlessForwarderKMSKeys: "" ElasticServerlessForwarderSQSEvents: "" ElasticServerlessForwarderSQSEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderS3SQSEvents: "" ElasticServerlessForwarderS3SQSEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderKinesisEvents: "" ElasticServerlessForwarderKinesisEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderCloudWatchLogsEvents: "" ElasticServerlessForwarderCloudWatchLogsEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderS3Buckets: "" ElasticServerlessForwarderSecurityGroups: "" ElasticServerlessForwarderSubnets: ""
-
通过运行以下命令从SAR部署Lambda函数
aws cloudformation deploy --template-file sar-application.yaml --stack-name esf-cloudformation-deployment --capabilities CAPABILITY_IAM CAPABILITY_AUTO_EXPAND
从v1.4.0开始,如果您想更新转发器的事件设置,则无需在应用新设置之前手动删除现有设置。
使用Terraform从SAR部署
编辑-
将以下yaml内容保存为
sar-application.tf,并根据定义部署参数填写正确的参数provider "aws" { region = "" ## FILL WITH THE AWS REGION WHERE YOU WANT TO DEPLOY THE ELASTIC SERVERLESS FORWARDER } data "aws_serverlessapplicationrepository_application" "esf_sar" { application_id = "arn:aws:serverlessrepo:eu-central-1:267093732750:applications/elastic-serverless-forwarder" } resource "aws_serverlessapplicationrepository_cloudformation_stack" "esf_cf_stak" { name = "terraform-elastic-serverless-forwarder" application_id = data.aws_serverlessapplicationrepository_application.esf_sar.application_id semantic_version = data.aws_serverlessapplicationrepository_application.esf_sar.semantic_version capabilities = data.aws_serverlessapplicationrepository_application.esf_sar.required_capabilities parameters = { ElasticServerlessForwarderS3ConfigFile = "" ElasticServerlessForwarderSSMSecrets = "" ElasticServerlessForwarderKMSKeys = "" ElasticServerlessForwarderSQSEvents = "" ElasticServerlessForwarderS3SQSEvents = "" ElasticServerlessForwarderKinesisEvents = "" ElasticServerlessForwarderCloudWatchLogsEvents = "" ElasticServerlessForwarderS3Buckets = "" ElasticServerlessForwarderSecurityGroups = "" ElasticServerlessForwarderSubnets = "" } }
-
通过运行以下命令从SAR部署函数
terraform init terraform apply
从v1.4.0及以上版本开始,如果您想更新部署的事件设置,则无需在应用新设置之前手动删除现有设置。
由于与aws_serverlessapplicationrepository_application相关的Terraform错误,如果您想删除现有的事件参数,则必须将相关的aws_serverlessapplicationrepository_cloudformation_stack.parameters设置为空格值(" ")而不是空字符串("")。
直接部署Elastic Serverless Forwarder
编辑为了在部署期间获得更多自定义选项,从版本1.6.0及以上版本,您可以直接将Elastic Serverless Forwarder部署到您的AWS账户,无需使用SAR。这使您可以逐一自定义输入(即触发器)的事件源设置。
要直接部署转发器,您必须
为发布脚本创建publish-config.yaml
编辑要直接部署转发器,您需要定义一个publish-config.yaml文件,并将其作为发布脚本中的参数传递。
将以下YAML内容保存为publish-config.yaml,并在运行发布脚本之前根据需要进行编辑。您应该删除任何不使用的输入或参数。
kinesis-data-stream: - arn: "arn:aws:kinesis:%REGION%:%ACCOUNT%:stream/%STREAMNAME%" batch_size: 10 batching_window_in_second: 0 starting_position: TRIM_HORIZON starting_position_timestamp: 0 parallelization_factor: 1 sqs: - arn: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" batch_size: 10 batching_window_in_second: 0 s3-sqs: - arn: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" batch_size: 10 batching_window_in_second: 0 cloudwatch-logs: - arn: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:*" - arn: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:log-stream:%LOG_STREAM_NAME%" ssm-secrets: - "arn:aws:secretsmanager:%AWS_REGION%:%AWS_ACCOUNT_ID%:secret:%SECRET_NAME%" kms-keys: - "arn:aws:kms:%AWS_REGION%:%AWS_ACCOUNT_ID%:key/%KMS_KEY_UUID%" s3-buckets: - "arn:aws:s3:::%BUCKET_NAME%" subnets: - "%SUBNET_ID%" security-groups: - "%SECURITY_ID%" s3-config-file: "s3://%S3_CONFIG_BUCKET_NAME%/%S3_CONFIG_OBJECT_KEY%" continuing-queue: batch_size: 10 batching_window_in_second: 0
字段
编辑
|
转发器用于 Amazon Kinesis 数据流(即触发器)的列表,与您在 创建并上传 |
|
AWS Kinesis 数据流的 ARN。 |
|
如果您在输出中遇到摄取延迟 并且 Amazon Kinesis 数据流 的 |
|
如果您在输出中遇到摄取延迟 并且 Amazon Kinesis 数据流 的 |
|
如果您想更改转发器为 Amazon Kinesis 数据流 处理的记录的起始位置,请将此值从默认值 ( |
|
如果您将 |
|
定义每个分片可以并发运行的转发器函数的数量(默认为 |
|
转发器用于 Amazon SQS 消息有效负载(即触发器)的列表,与您在 创建并上传 |
|
AWS SQS 队列触发器输入的 ARN。 |
|
如果您在输出中遇到摄取延迟 并且 Amazon SQS 消息有效负载 的 |
|
如果您在输出中遇到摄取延迟 并且 Amazon SQS 消息有效负载 的 |
|
转发器用于 Amazon S3(通过 SQS 事件通知)(即触发器)的列表,与您在 创建并上传 |
|
接收 S3 通知作为触发器输入的 AWS SQS 队列的 ARN。 |
|
如果您在输出中遇到摄取延迟 并且 Amazon S3(通过 SQS 事件通知) 的 |
|
如果您在输出中遇到摄取延迟 并且 Amazon S3(通过 SQS 事件通知) 的 |
|
转发器用于 Amazon CloudWatch Logs 订阅过滤器(即触发器)的列表,与您在 创建并上传 |
|
AWS CloudWatch Logs 触发器输入的 ARN(接受 CloudWatch Logs 日志组和 CloudWatch Logs 日志流 ARN)。 |
|
您在 |
|
用于解密 AWS SSM Secrets、Kinesis 数据流或 SQS 队列的 AWS KMS 密钥 ARN 列表(如有)。 |
|
作为 S3 SQS 事件通知源的 S3 存储桶 ARN 列表(如有)。 |
|
转发器的子网 ID 列表。与 |
|
要附加到转发器的安全组 ID 列表。与 |
|
将此值设置为 S3 URL 格式中转发器配置文件的位置: |
|
如果您在输出中遇到摄取延迟 并且 持续队列的 |
|
如果您在输出中遇到摄取延迟 并且 持续队列的 |
运行发布脚本
编辑可在 Elastic Serverless Forwarder 代码库 中找到一个用于将 Elastic Serverless Forwarder 直接发布到您的 AWS 帐户的 bash 脚本。
下载 publish_lambda.sh 脚本 并按照以下说明操作。
脚本参数
编辑$ ./publish_lambda.sh AWS CLI (https://aws.amazon.com/cli/), SAM (https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/install-sam-cli.html) and Python3.9 with pip3 required Please, before launching the tool execute "$ pip3 install ruamel.yaml" Usage: ./publish_lambda.sh config-path lambda-name forwarder-tag bucket-name region [custom-role-prefix] Arguments: config-path: full path to the publish configuration lambda-name: name of the lambda to be published in the account forwarder-tag: tag of the elastic serverless forwarder to publish bucket-name: bucket name where to store the zip artifact for the lambda (it will be created if it doesn't exists, otherwise you need already to have proper access to it) region: region where to publish in custom-role-prefix: role/policy prefix to add in case customization is needed (optional) (please note that the prefix will be added to both role/policy naming)
先决条件
编辑- 运行脚本需要 Python3.9 和 pip3
- 还必须安装AWS CLI、SAM CLI和ruamel.yaml 包
$ pip3 install awscli aws-sam-cli ruamel.yaml
运行脚本
编辑假设publish-config.yaml保存于您打算运行publish_lambda.sh的同一目录中,以下是一个示例
$ ./publish_lambda.sh publish-config.yaml forwarder-lambda lambda-v1.6.0 s3-lambda-artifact-bucket-name eu-central-1
通过脚本更新到新版本
编辑您可以通过再次运行发布脚本并传递一个新的forwarder-tag来更新已发布的 Elastic Serverless Forwarder 的版本,而无需更改其配置。
$ ./publish_lambda.sh publish-config.yaml forwarder-lambda lambda-v1.7.0 s3-lambda-artifact-bucket-name eu-central-1
以上示例显示将 forwarder 从lambda-v1.6.0更新到lambda-v1.7.0。
通过脚本更改配置
编辑如果您想更改已发布的 Elastic Serverless Forwarder 的配置而无需更改其版本,您可以更新publish-config.yaml并使用相同的forwarder-tag再次运行脚本。
$ ./publish_lambda.sh publish-config.yaml forwarder-lambda lambda-v1.6.0 s3-lambda-artifact-bucket-name eu-central-1
以上示例显示更新现有lambda-v1.6.0配置而无需更改版本。
将脚本用于多个部署
编辑如果您想使用发布脚本部署具有不同配置的 forwarder,请创建两个具有唯一名称的不同publish-config.yaml文件,并使用正确的config-path和lambda-name引用两次运行发布脚本。
$ ./publish_lambda.sh publish-config-for-first-lambda.yaml first-lambda lambda-v1.6.0 s3-lambda-artifact-bucket-name eu-central-1 $ ./publish_lambda.sh publish-config-for-second-lambda.yaml second-lambda lambda-v1.6.0 ss3-lambda-artifact-bucket-name eu-central-1
以上示例发布了两个版本的 forwarder,每个版本都有不同的配置,即publish-config-for-first-lambda.yaml和first-lambda与publish-config-for-second-lambda.yaml和second-lambda。