Elastic Serverless Forwarder 配置选项
编辑Elastic Serverless Forwarder 配置选项
编辑了解有关 Elastic Serverless Forwarder 配置选项的更多信息,包括权限和策略的详细信息、AWS 服务日志的自动路由以及如何使用 AWS Secrets Manager 进行身份验证。
您可以转换或丰富来自 AWS 的数据,因为转发器会对其进行解析。这包括一些示例,例如使用标签和过滤器来组织数据并排除特定消息,自动发现和收集 JSON 内容以及有效地管理多行消息。
权限和策略
编辑Lambda 函数的执行角色是一个 AWS Identity and Access Management (IAM) 角色,它授予函数访问 AWS 服务和资源的权限。此角色在部署函数时自动创建,并且在调用函数时,Lambda 会承担此角色。
当您提供转发器将与其交互的 AWS 资源的 ARN 时,Cloudformation 模板将创建具有相应 IAM 策略的正确 IAM 角色。
您可以从 配置 > 权限 部分查看与您的 Lambda 函数关联的执行角色。默认情况下,此角色名称以 serverlessrepo- 开头。创建角色时,会添加自定义策略以授予 Lambda 最小权限,以便能够使用已配置的 SQS 队列、S3 存储桶、Kinesis 数据流、CloudWatch Logs 日志组、Secrets Manager(如果使用)和 SQS 重播队列。
转发器被授予以下 ManagedPolicyArns 权限,这些权限默认情况下会自动添加到 Events 配置(如果相关)。
arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole arn:aws:iam::aws:policy/service-role/AWSLambdaKinesisExecutionRole arn:aws:iam::aws:policy/service-role/AWSLambdaSQSQueueExecutionRole
除了这些基本权限外,函数的 Cloudformation 模板创建函数时还会添加以下权限:
- 对于在
SQS_CONTINUE_URL和SQS_REPLAY_URL环境变量中指定的 SQS 队列资源,允许执行以下操作:sqs:SendMessage - 对于在
S3_CONFIG_FILE环境变量中指定的 S3 存储桶资源,允许对 S3 存储桶的配置文件对象键执行以下操作:s3:GetObject - 对于每个向 SQS 队列发送通知的 S3 存储桶资源,允许对 S3 存储桶执行以下操作:
s3:ListBucket - 对于每个向 SQS 队列发送通知的 S3 存储桶资源,允许对 S3 存储桶的键执行以下操作:
s3:GetObject - 对于您要在
config.yaml文件中引用的每个 Secrets Manager 密钥,允许执行以下操作:secretsmanager:GetSecretValue - 除了用于使用您的 Secrets Manager 密钥进行加密的默认密钥外,还允许对每个解密密钥执行以下操作:
kms:Decrypt -
如果将任何 CloudWatch Logs 日志组设置为 Lambda 输入,则允许对资源执行以下操作:
-
arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:*:* -
logs:DescribeLogGroups
-
用于 CloudWatch Logs 订阅筛选器输入的 Lambda 基于资源的策略
编辑对于要用作转发器触发器的 CloudWatch Logs 订阅筛选器日志组资源,以下内容在单独的策略声明中被允许作为基于资源的策略:
* Principal: logs.%AWS_REGION%.amazonaws.com * Action: lambda:InvokeFunction * Source ARN: arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:*
使用 AWS Secrets Manager
编辑AWS Secrets Manager 使您能够使用对 Secrets Manager 的 API 调用以编程方式检索密钥来替换代码中硬编码的凭据(包括密码)。有关更多信息,请参阅 AWS Secrets Manager 文档。
可以使用两种类型的密钥:
- SecretString(纯文本或键/值对)
- SecretBinary
以下代码显示了对 AWS Secrets Manager 的 API 调用:
inputs: - type: "s3-sqs" id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" outputs: - type: "elasticsearch" args: elasticsearch_url: "arn:aws:secretsmanager:eu-central-1:123456789:secret:es_url" username: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:username" password: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:password" es_datastream_name: "logs-generic-default"
要使用 纯文本 或 二进制 密钥,请注意 ARN 的以下格式:
arn:aws:secretsmanager:AWS_REGION:AWS_ACCOUNT_ID:secret:SECRET_NAME
为了使用 键/值 对密钥,您需要在 arn 的末尾提供键,如下所示:
arn:aws:secretsmanager:AWS_REGION:AWS_ACCOUNT_ID:secret:SECRET_NAME:SECRET_KEY
- 支持不同区域的密钥,但目前仅检索密钥的
AWSCURRENT版本。 - 您不能对纯文本和键/值对使用相同的密钥。
- 密钥区分大小写。
config.yaml文件中的任何配置错误或错别字都将被忽略(或引发异常),并且不会检索密钥。- 密钥必须存在于 AWS Secrets Manager 中。
- 不允许给定键的空值。
路由 AWS 服务日志
编辑对于 S3 SQS 事件通知 输入,Elastic Serverless Forwarder 支持将多个 AWS 服务日志自动路由到相应的 集成数据流,以便在 Elasticsearch 集群中进一步处理和存储。
自动路由
编辑Elastic Serverless Forwarder 支持将以下日志自动路由到相应默认的集成数据流:
- AWS CloudTrail (
aws.cloudtrail) - Amazon CloudWatch (
aws.cloudwatch_logs) - Elastic Load Balancing (
aws.elb_logs) - AWS 网络防火墙 (
aws.firewall_logs) - Amazon VPC 流量 (
aws.vpcflow) - AWS Web 应用防火墙 (
aws.waf)
对于这些用例,在配置文件中设置 es_datastream_name 字段是可选的。
对于大多数其他用例,您需要在配置文件中设置 es_datastream_name 字段才能将数据路由到特定数据流或索引。在以下用例中应设置此值:
- 您想要将数据写入特定索引、别名或自定义数据流,而不是写入默认集成数据流。这可以帮助某些用户使用现有的 Elasticsearch 资源,例如索引模板、摄取管道或仪表板,这些资源已设置并连接到业务流程。
- 使用
Kinesis 数据流、CloudWatch Logs 订阅筛选器或直接 SQS 消息有效负载输入时。只有S3 SQS 事件通知输入方法支持将多个 AWS 服务日志自动路由到默认集成数据流。 - 使用
S3 SQS 事件通知,但日志类型不是 AWS CloudTrail (aws.cloudtrail)、Amazon CloudWatch Logs (aws.cloudwatch_logs)、Elastic Load Balancing (aws.elb_logs)、AWS 网络防火墙 (aws.firewall_logs)、Amazon VPC 流量 (aws.vpcflow) 和 AWS Web 应用防火墙 (aws.waf) 时。
如果未指定 es_datastream_name,并且日志无法与上述任何 AWS 服务匹配,则数据集将设置为 generic,命名空间设置为 default,指向数据流名称 logs-generic-default。
使用标签和过滤器
编辑您可以使用标签和过滤器根据正则表达式标记和筛选消息。
使用自定义标签
编辑您可以添加自定义标签来筛选和分类事件中的项目。
inputs: - type: "s3-sqs" id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" tags: - "tag1" - "tag2" - "tag3" outputs: - type: "elasticsearch" args: elasticsearch_url: "arn:aws:secretsmanager:eu-central-1:123456789:secret:es_url" username: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:username" password: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:password" es_datastream_name: "logs-generic-default"
使用上述示例配置,标签将按以下方式设置:
["forwarded", "generic", "tag1", "tag2", "tag3"]
forwarded 标签始终附加,此示例中的 generic 标签来自数据集。
- 必须在
config.yaml文件的inputs中定义标签。 - 每个标签必须是一个字符串并添加到列表中。
定义包含/排除过滤器
编辑您可以为输入定义多个过滤器,以包含或排除数据摄取中的事件。
inputs: - type: "s3-sqs" id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" include: - "[a-zA-Z]" exclude: - "skip this" - "skip also this" outputs: - type: "elasticsearch" args: elasticsearch_url: "arn:aws:secretsmanager:eu-central-1:123456789:secret:es_url" username: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:username" password: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:password" es_datastream_name: "logs-generic-default"
您可以在 inputs.[].include 中定义正则表达式列表。如果填充此列表,则只有匹配任何已定义正则表达式的消息才会转发到输出。
您可以在 inputs.[].exclude 中定义正则表达式列表。如果填充此列表,则只有不匹配任何已定义正则表达式的消息才会转发到输出,即除非消息匹配任何已定义的正则表达式,否则每条消息都会转发到输出。
这两个配置参数都是可选的,可以彼此独立设置。就规则优先级而言,首先应用排除过滤器,然后应用包含过滤器,因此如果同时指定两者,则排除优先。
所有正则表达式都区分大小写,应遵循 Python 3.9 正则表达式语法。
扫描消息以查找与已定义过滤器匹配的术语。使用 ^ (插入符) 特殊字符将正则表达式明确锚定到字符串第一个字符之前的位 置,并使用 $ 锚定到结尾。
编译正则表达式时不使用任何标志。有关多行、不区分大小写和其他匹配行为的替代选项,请参阅内联标志文档。
JSON 内容发现
编辑Elastic Serverless Forwarder 能够自动发现输入有效负载中的 JSON 内容,并收集有效负载中包含的 JSON 对象。
JSON 对象可以位于单行上,也可以跨多行。在第二种情况下,转发器期望跨多行的不同 JSON 对象以换行符分隔。
当 JSON 对象跨越多行时,会应用 1000 行的限制。任何跨越超过 1000 行的 JSON 对象都将不会被收集。组成整个 JSON 对象的每一行将单独转发。
如果您已知有效负载内容包含跨越超过 1000 行的单个 JSON 对象,或者您发现依赖于 JSON 内容的自动发现会对性能产生重大影响,则可以在输入中配置 JSON 内容类型来解决此问题。这将改变解析逻辑并提高性能,同时克服 1000 行的限制。
如果已知内容为纯文本,则可以通过完全禁用自动 JSON 内容发现来提高整体性能。
要更改此配置选项,请将inputs.[].json_content_type设置为以下值之一
- single:表示输入有效负载中单个项目的內容是一个单个 JSON 对象。内容可以位于单行上,也可以跨越多行。使用此设置,有效负载的整个内容将被视为一个 JSON 对象,对 JSON 对象跨越的行数没有限制。
- ndjson:表示输入有效负载中单个项目的內容是有效的 NDJSON 格式。应使用换行符分隔单行上格式化的多个单个 JSON 对象。使用此设置,每一行都将被视为一个 JSON 对象,从而提高解析性能。
- disabled:指示转发器不尝试任何自动 JSON 内容发现,而是将内容视为纯文本,从而提高解析性能。
JSON 内容仍以text字段类型存储在 Elasticsearch 中。转发器不执行任何自动 JSON 展开;这可以使用 Elasticsearch 中的JSON 处理器在摄取管道中实现。
当从 JSON 对象列表展开事件时,无需配置 JSON 内容类型,除非您有跨越超过 1000 行的单个 JSON 对象。
从 JSON 对象列表展开事件
编辑您可以从 JSON 文件中的特定字段提取要摄取的事件列表。
inputs: - type: "s3-sqs" id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" expand_event_list_from_field: "Records" # root_fields_to_add_to_expanded_event: "all" # root_fields_to_add_to_expanded_event: ["owner", "logGroup", "logStream"] outputs: - type: "elasticsearch" args: elasticsearch_url: "arn:aws:secretsmanager:eu-central-1:123456789:secret:es_url" username: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:username" password: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:password" es_datastream_name: "logs-generic-default"
您可以将inputs.[].expand_event_list_from_field定义为一个字符串,其值为 JSON 中包含必须作为事件发送的元素列表(而不是包含 JSON)的键。
要将 JSON 对象中的根字段注入展开的事件中,请定义inputs.[].root_fields_to_add_to_expanded_event。此配置采用以下值之一
- 文字字符串all,用于注入所有根字段(您正在展开事件的字段除外)。例如,
root_fields_to_add_to_expanded_event: "all" - 您要注入的根字段列表。例如,
root_fields_to_add_to_expanded_event: ["owner", "logGroup", "logStream"]
当路由服务日志时,将忽略为expand_event_list_from_field配置参数设置的任何值,因为 Elastic Serverless Forwarder 将自动处理此问题。
不使用root_fields_to_add_to_expanded_event的示例
编辑使用以下输入
{"Records":[{"key": "value #1"},{"key": "value #2"}]} {"Records":[{"key": "value #3"},{"key": "value #4"}]}
不设置expand_event_list_from_field,将转发两个事件
{"@timestamp": "2022-06-16T04:06:03.064Z", "message": "{\"Records\":[{\"key\": \"value #1\"},{\"key\": \"value #2\"}]}"} {"@timestamp": "2022-06-16T04:06:13.888Z", "message": "{\"Records\":[{\"key\": \"value #3\"},{\"key\": \"value #4\"}]}"}
如果expand_event_list_from_field设置为Records,将转发四个事件
{"@timestamp": "2022-06-16T04:06:21.105Z", "message": "{\"key\": \"value #1\"}"} {"@timestamp": "2022-06-16T04:06:27.204Z", "message": "{\"key\": \"value #2\"}"} {"@timestamp": "2022-06-16T04:06:31.154Z", "message": "{\"key\": \"value #3\"}"} {"@timestamp": "2022-06-16T04:06:36.189Z", "message": "{\"key\": \"value #4\"}"}
使用root_fields_to_add_to_expanded_event的示例
编辑使用以下输入
{"Records":[{"key": "value #1"},{"key": "value #2"}], "field1": "value 1a", "field2": "value 2a"} {"Records":[{"key": "value #3"},{"key": "value #4"}], "field1": "value 1b", "field2": "value 2b"}
如果expand_event_list_from_field设置为Records,并且root_fields_to_add_to_expanded_event设置为all,将转发四个事件
{"@timestamp": "2022-06-16T04:06:21.105Z", "message": "{\"key\": \"value #1\", \"field1\": \"value 1a\", \"field2\": \"value 2a\""} {"@timestamp": "2022-06-16T04:06:27.204Z", "message": "{\"key\": \"value #2\", \"field1\": \"value 1a\", \"field2\": \"value 2a\""} {"@timestamp": "2022-06-16T04:06:31.154Z", "message": "{\"key\": \"value #3\", \"field1\": \"value 1b\", \"field2\": \"value 2b\""} {"@timestamp": "2022-06-16T04:06:36.189Z", "message": "{\"key\": \"value #4\", \"field1\": \"value 1b\", \"field2\": \"value 2b\""}
如果expand_event_list_from_field设置为Records,并且root_fields_to_add_to_expanded_event设置为["field1"],将转发四个事件
{"@timestamp": "2022-06-16T04:06:21.105Z", "message": "{\"key\": \"value #1\", \"field1\": \"value 1a\""} {"@timestamp": "2022-06-16T04:06:27.204Z", "message": "{\"key\": \"value #2\", \"field1\": \"value 1a\""} {"@timestamp": "2022-06-16T04:06:31.154Z", "message": "{\"key\": \"value #3\", \"field1\": \"value 1b\""} {"@timestamp": "2022-06-16T04:06:36.189Z", "message": "{\"key\": \"value #4\", \"field1\": \"value 1b\""}
管理多行消息
编辑转发的內容可能包含跨越多行的消息。例如,包含 Java 堆栈跟踪的文件中常见的都是多行消息。为了正确处理这些多行事件,您需要为特定输入配置multiline设置,以指定哪些行属于单个事件。
配置选项
编辑您可以在config.yaml文件中为特定输入指定以下选项,以控制 Elastic Serverless Forwarder 如何处理跨越多行的消息。
inputs: - type: "s3-sqs" id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%" multiline: type: pattern pattern: '^\\[' negate: true match: after outputs: - type: "elasticsearch" args: elasticsearch_url: "arn:aws:secretsmanager:eu-central-1:123456789:secret:es_url" username: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:username" password: "arn:aws:secretsmanager:eu-west-1:123456789:secret:es_secrets:password" es_datastream_name: "logs-generic-default"
转发器获取所有不以[开头的行,并将它们与之前以[开头的行组合在一起。例如,您可以使用此配置将多行消息的以下行合并到单个事件中
[beat-logstash-some-name-832-2015.11.28] IndexNotFoundException[no such index] at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver$WildcardExpressionResolver.resolve(IndexNameExpressionResolver.java:566) at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:133) at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:77) at org.elasticsearch.action.admin.indices.delete.TransportDeleteIndexAction.checkBlock(TransportDeleteIndexAction.java:75)
请注意,您应该转义正则表达式中的左方括号([),因为它指定了一个字符类,即您希望匹配的一组字符。您还必须转义用于转义左方括号的反斜杠(\),因为未使用原始字符串。因此,^\\[将在编译时生成所需的正则表达式。
inputs.[].multiline.type定义要使用的聚合方法。默认值为pattern。其他选项包括count(允许您聚合固定数量的行)和while_pattern(允许根据模式聚合行,但不进行匹配选项)。
inputs.[].multiline.pattern与 Logstash 支持的模式不同。有关支持的正则表达式模式列表,请参阅Python 3.9 正则表达式语法。根据您如何配置其他多行选项,与指定正则表达式匹配的行被视为先前行的延续或新的多行事件的开始。
inputs.[].multiline.negate定义是否否定模式。默认值为false。此设置仅适用于pattern和while_pattern类型。
inputs.[].multiline.match根据以下模式更改多行的分组(仅适用于pattern类型)
|
|
结果 |
示例 |
|
|
与模式匹配的连续行将追加到之前不匹配的行。 |
|
|
|
与模式匹配的连续行将添加到下一行(不匹配的行)之前。 |
|
|
|
不与模式匹配的连续行将追加到之前与模式匹配的行。 |
|
|
|
不与模式匹配的连续行将添加到下一行(与模式匹配的行)之前。 |
|
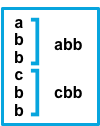
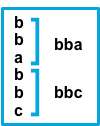
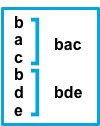
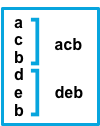
after设置等效于Logstash中的previous,而before等效于next。
inputs.[].multiline.flush_pattern指定一个正则表达式,在该表达式中,当前多行将从内存中刷新,结束多行消息。仅适用于pattern类型。
inputs.[].multiline.max_lines定义可以组合到一个事件中的最大行数。如果多行消息包含超过max_lines行,则任何附加行都将从事件中截断。默认值为500。
inputs.[].multiline.max_bytes定义可以组合到一个事件中的最大字节数。如果多行消息包含超过max_bytes字节,则任何附加内容都将从事件中截断。默认值为10485760。
inputs.[].multiline.count_lines定义要聚合到单个事件中的行数。仅适用于count类型。
inputs.[].multiline.skip_newline定义是否必须连接多行事件,同时去除行分隔符。如果设置为true,则将去除行分隔符。默认值为false。
多行配置示例
编辑本节中的示例涵盖以下用例
- 将 Java 堆栈跟踪组合到单个事件中
- 将 C 样式的行延续组合到单个事件中
- 组合来自带时间戳事件的多行
Java 堆栈跟踪
编辑Java 堆栈跟踪由多行组成,初始行后的每一行都以空格开头,例如:
Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book.java:16) at com.example.myproject.Author.getBookTitles(Author.java:25) at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
此配置合并任何以空格开头的行到前一行
multiline: type: pattern pattern: '^\s' negate: false match: after
这是一个稍微复杂的 Java 堆栈跟踪示例
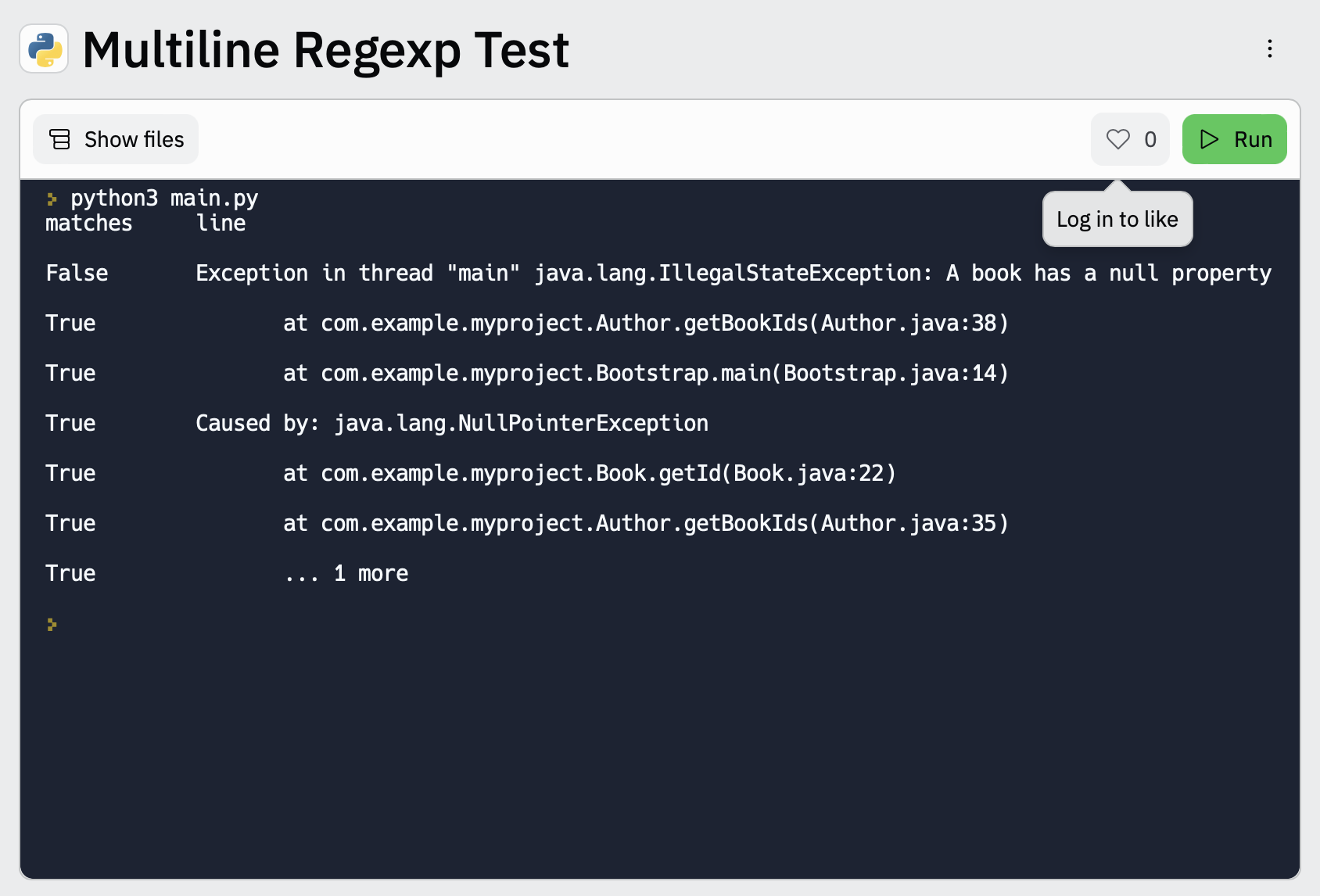
Exception in thread "main" java.lang.IllegalStateException: A book has a null property at com.example.myproject.Author.getBookIds(Author.java:38) at com.example.myproject.Bootstrap.main(Bootstrap.java:14) Caused by: java.lang.NullPointerException at com.example.myproject.Book.getId(Book.java:22) at com.example.myproject.Author.getBookIds(Author.java:35) ... 1 more
要将这些行合并到单个事件中,请使用以下多行配置
multiline: type: pattern pattern: '^\s+(at|.{3})\s+\\b|^Caused by:' negate: false match: after
在此示例中,模式匹配并合并以下行:- 以空格开头,后跟at或...的行 - 以Caused by:开头的行
在 Python 的字符串文字中,\b是退格符(ASCII 值 8)。由于未使用原始字符串,Python 会将\b转换为退格符。为了使我们的正则表达式按预期匹配,您需要将\b中的反斜杠\转义为\\b,这将在编译时生成正确的正则表达式。
行延续
编辑几种编程语言使用行尾的反斜杠(\)字符来表示行延续,例如:
printf ("%10.10ld \t %10.10ld \t %s\ %f", w, x, y, z );
要将这些行合并到单个事件中,请使用以下多行配置
multiline: type: pattern pattern: '\\\\$' negate: false match: after
此配置将任何以\字符结尾的行与下一行合并。
请注意,您应该在正则表达式中将开头的反斜杠(\)转义两次,因为未使用原始字符串。因此,\\\\$将在编译时生成所需的正则表达式。
时间戳
编辑Elasticsearch 等服务的活动日志通常以时间戳开头,后跟有关特定活动的信息,例如:
[2015-08-24 11:49:14,389][INFO ][env ] [Letha] using [1] data paths, mounts [[/ (/dev/disk1)]], net usable_space [34.5gb], net total_space [118.9gb], types [hfs]
要将这些行合并到单个事件中,请使用以下多行配置
multiline: type: pattern pattern: '^\\[[0-9]{4}-[0-9]{2}-[0-9]{2}' negate: true match: after
此配置使用negate: true和match: after设置来指定任何不匹配指定模式的行都属于前一行。
请注意,您应该转义正则表达式中的左方括号([),因为它指定了一个字符类,即您希望匹配的一组字符。您还必须转义用于转义左方括号的反斜杠(\),因为未使用原始字符串。因此,^\\[将在编译时生成所需的正则表达式。
应用程序事件
编辑有时您的应用程序日志包含以自定义标记开头和结尾的事件,例如以下示例
[2015-08-24 11:49:14,389] Start new event [2015-08-24 11:49:14,395] Content of processing something [2015-08-24 11:49:14,399] End event
要将这些行合并到单个事件中,请使用以下多行配置
multiline: type: pattern pattern: 'Start new event' negate: true match: after flush_pattern: 'End event'
flush_pattern选项指定一个正则表达式,在该表达式处将刷新当前多行。如果您认为pattern选项指定事件的开头,则flush_pattern选项将指定事件的结尾或最后一行。
如果起始/结束日志块与非多行日志混合,或者不同的起始/结束日志块彼此重叠,则此示例将无法正常工作。例如,在以下示例中,Some other log 日志行将合并为一个单行多行文档,因为它们既不匹配inputs.[].multiline.pattern也不匹配inputs.[].multiline.flush_pattern,并且inputs.[].multiline.negate设置为true。
[2015-08-24 11:49:14,389] Start new event [2015-08-24 11:49:14,395] Content of processing something [2015-08-24 11:49:14,399] End event [2015-08-24 11:50:14,389] Some other log [2015-08-24 11:50:14,395] Some other log [2015-08-24 11:50:14,399] Some other log [2015-08-24 11:51:14,389] Start new event [2015-08-24 11:51:14,395] Content of processing something [2015-08-24 11:51:14,399] End event
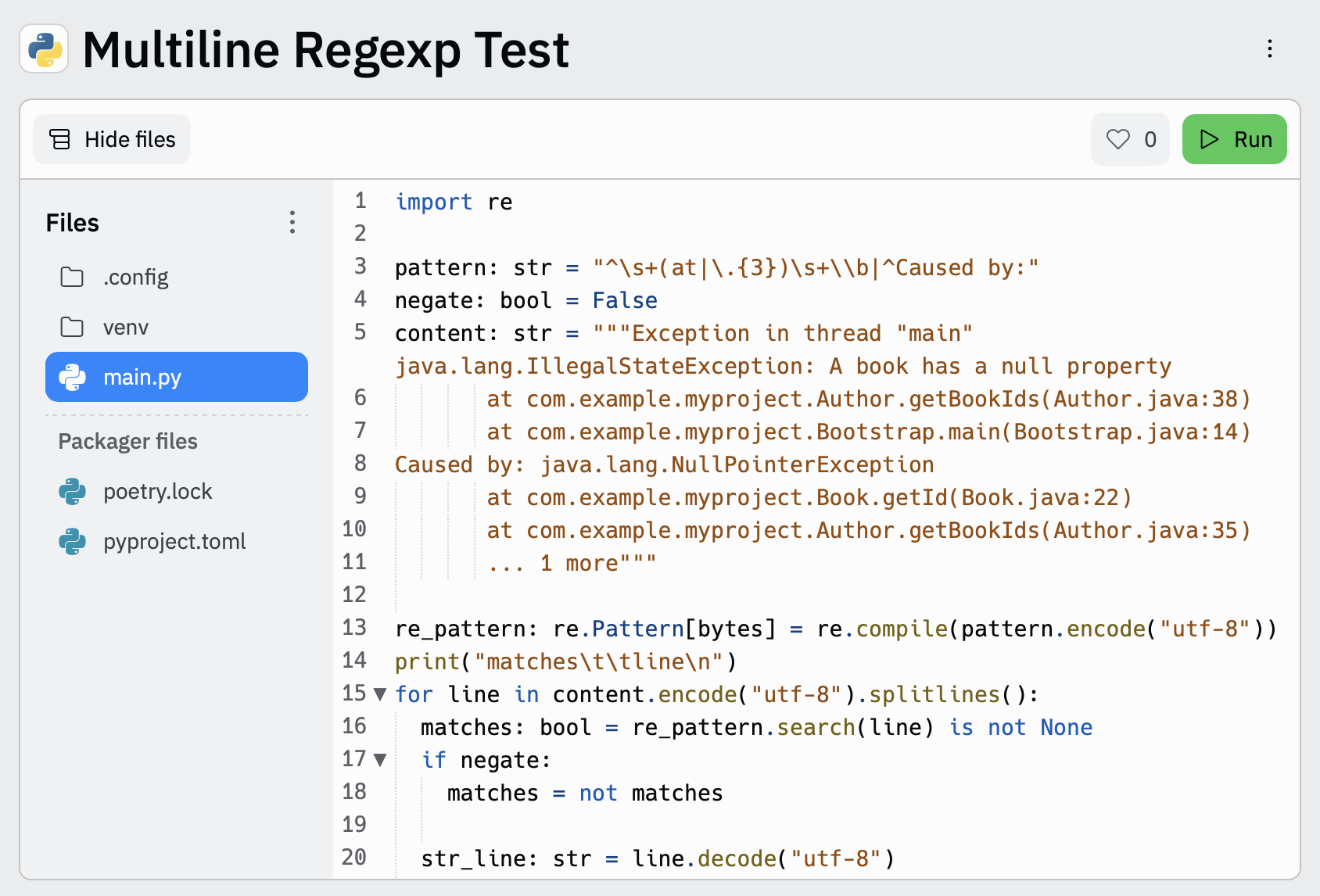
测试您的多行正则表达式模式
编辑为了方便您测试多行配置中的正则表达式模式,您可以使用此多行正则表达式测试工具
- 在第
3行填写正则表达式模式,并在第4行填写您计划使用的multiline.negate设置。 - 将示例消息粘贴到第
5行三个双引号分隔符(""" """)之间。 - 单击
Run以查看消息中哪些行与您指定的配置匹配。
管理自签名证书
编辑从 v1.5.0 版本开始,ESF 引入了 SSL 指纹选项,用于使用自签名证书访问 Elasticsearch 集群。
配置选项
编辑要设置ssl_assert_fingerprint选项,必须编辑存储在 S3 存储桶中的配置文件。
假设您在存储桶中有一个config.yml文件,其内容如下所示
inputs: - type: "s3-sqs" id: "arn:aws:sqs:eu-west-1:123456789:dev-access-logs" outputs: - type: "elasticsearch" args: api_key: "<REDACTED>" es_datastream_name: "logs-aws.s3access-default" batch_max_actions: 500 batch_max_bytes: 10485760 ssl_assert_fingerprint: ""
如果配置省略了ssl_assert_fingerprint,或者像此示例一样为空(默认选项),则 HTTP 客户端将验证 Elasticsearch 集群的证书。
获取 SSL 指纹
编辑下一步是获取 Elasticsearch 集群当前使用的 HTTPS 证书的指纹。
您可以使用 OpenSSL 获取证书的指纹。以下是一个使用托管在 Elastic Cloud 上的 Elasticsearch 集群的示例
$ openssl s_client \ -connect my-deployment.es.eastus2.azure.elastic-cloud.com:443 \ -showcerts </dev/null 2>/dev/null | openssl x509 -noout -fingerprint SHA1 Fingerprint=1C:46:32:75:AA:D6:F1:E2:8E:10:A3:64:44:B1:36:C9:7D:44:35:B4
您可以使用您的 DNS 名称、IP 地址和端口号替换上述示例中的my-deployment.es.eastus2.azure.elastic-cloud.com:443。
复制您的指纹值以进行下一步操作。
设置 SSL 指纹
编辑最后一步是编辑您的config.yml文件以使用 SSL 指纹。
inputs: - type: "s3-sqs" id: "arn:aws:sqs:eu-west-1:123456789:dev-access-logs" outputs: - type: "elasticsearch" args: api_key: "<REDACTED>" es_datastream_name: "logs-aws.s3access-default" batch_max_actions: 500 batch_max_bytes: 10485760 ssl_assert_fingerprint: "1C:46:32:75:AA:D6:F1:E2:8E:10:A3:64:44:B1:36:C9:7D:44:35:B4"