事务采样
编辑事务采样
编辑分布式追踪会生成大量数据。更多的数据可能意味着更高的成本和更多的噪声。采样的目的是减少摄取的数据量和分析数据所需的工作量,同时仍然可以轻松找到应用程序中的异常模式、检测中断、跟踪错误并缩短平均恢复时间 (MTTR)。
Elastic APM 支持两种类型的采样
基于头部的采样
编辑在基于头部的采样中,每个链路的采样决策是在链路启动时做出的。每个链路都有一个定义的、相同的被采样的概率。
例如,采样值 .2 表示事务采样率为 20%。这意味着只有 20% 的链路会发送并保留其所有相关信息。剩余的链路将丢弃上下文信息,以减少链路的传输和存储大小。
基于头部的采样设置起来快速而简单。它的缺点是它是完全随机的,有趣的数据可能纯粹由于偶然性而被丢弃。
请参阅配置基于头部的采样以开始使用。
分布式追踪
编辑在分布式链路中,采样决策仍然是在链路启动时做出的。每个后续服务都会尊重初始服务的采样决策,而无论其配置的采样率如何;结果是采样百分比与发起服务匹配。
在图 1 中的示例中,服务 A 启动了四个事务,采样率为 .5 (50%)。上游采样决策受到尊重,因此即使采样率在 服务 B 和 服务 C 中定义且为不同的值,所有服务的采样率都将为 .5 (50%)。
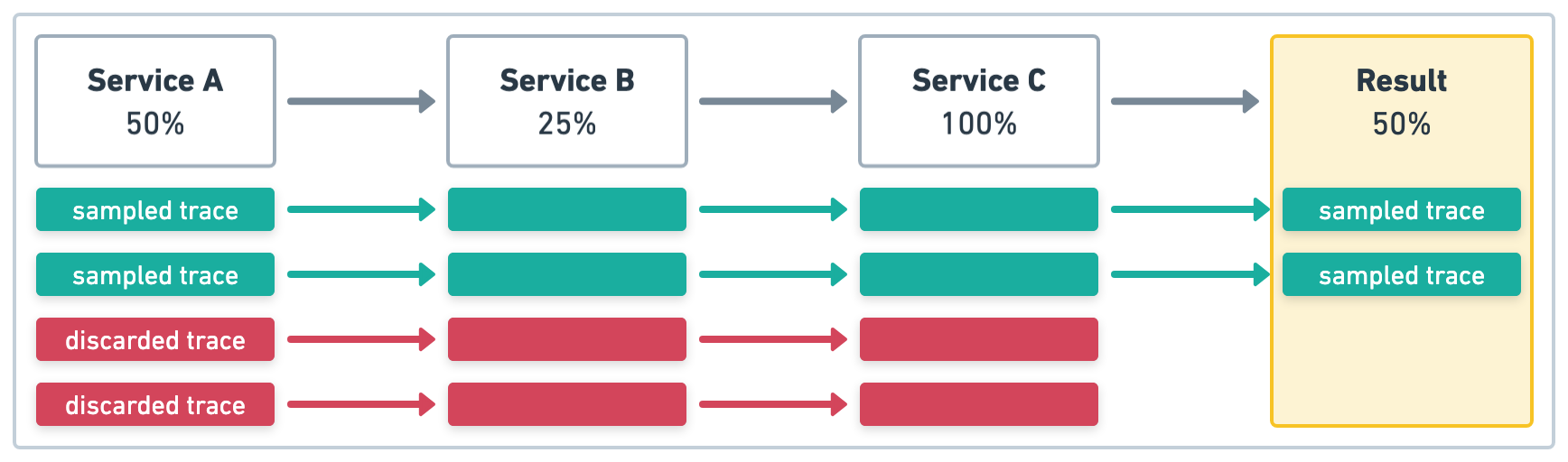
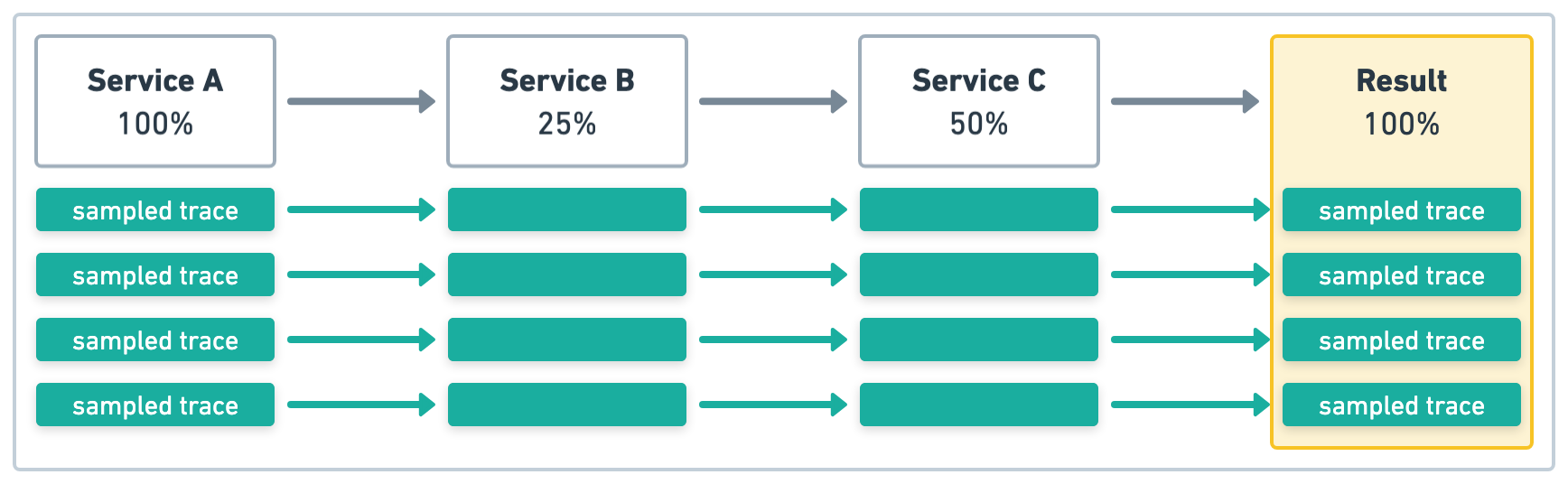
在图 2 中的示例中,服务 A 启动了四个事务,采样率为 1 (100%)。同样,上游采样决策受到尊重,因此所有服务的采样率都将为 1 (100%)。
分布式追踪的链路延续策略
编辑除了设置采样率外,您还可以指定要使用的链路延续策略。有三种链路延续策略:continue、restart 和 restart_external。
continue 链路延续策略是默认策略,其行为类似于分布式追踪部分中的示例。
如果之前的服务没有带有 es 供应商数据的 traceparent 标头,请在 Elastic 监控的服务上使用 restart_external 链路延续策略来启动新的链路。如果事务包含从非监控服务接收请求的 Elastic 监控的服务,这会很有用。
在图 3 的示例中,服务 A 是一个 Elastic 监控的服务,它以 .25 (25%) 的采样率启动四个事务。由于 服务 B 是非监控的,因此在 服务 A 中启动的链路将在此处结束。服务 C 是一个 Elastic 监控的服务,它启动四个事务,这些事务以新的 .5 (50%) 的采样率开始新的链路。由于 服务 D 也是 Elastic 监控的服务,因此会尊重 服务 C 中定义的上游采样决策。最终结果将是三个采样的链路。
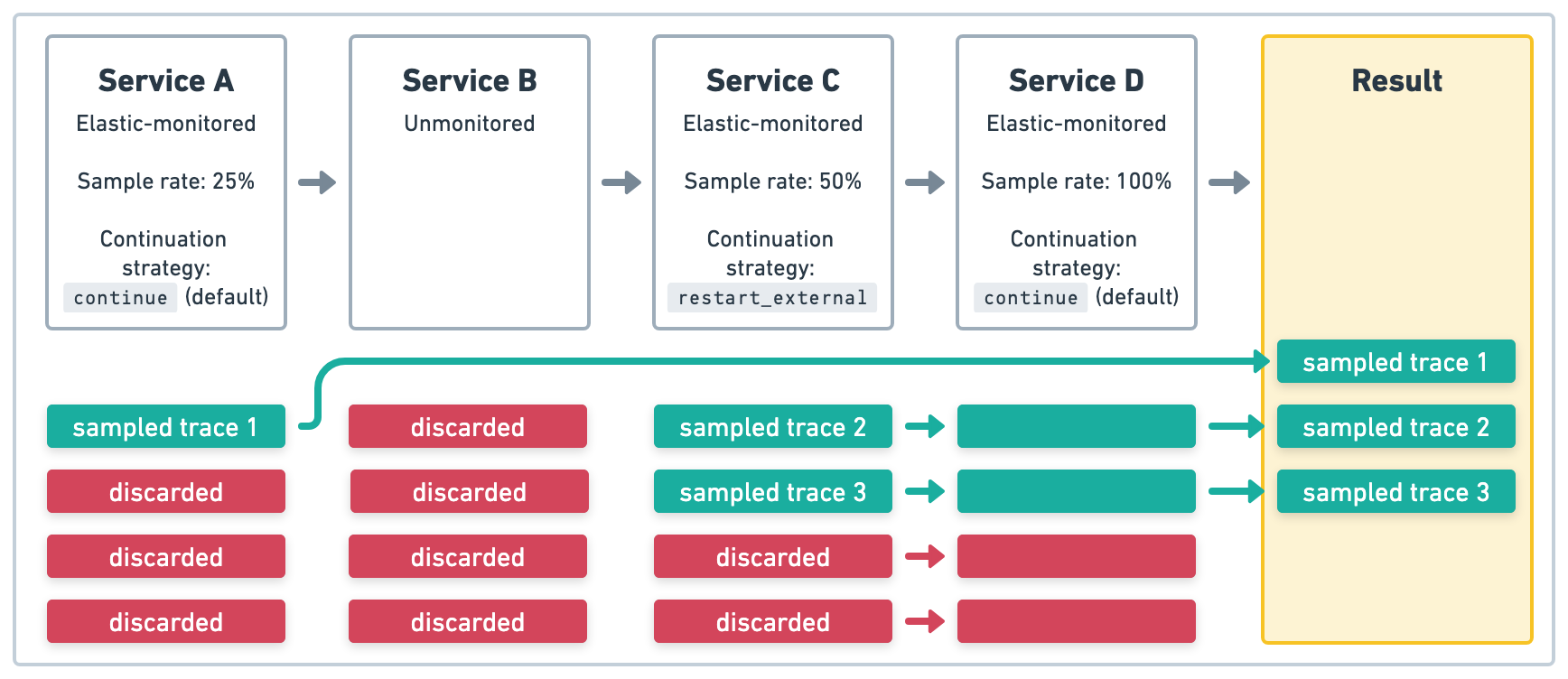
restart_external 链路延续策略无论之前的服务是否有 traceparent 标头,都请在 Elastic 监控的服务上使用 restart 链路延续策略来启动新的链路。如果 Elastic 监控的服务是公开的,并且您不希望用户请求可能伪造追踪数据,这会很有用。
在图 4 的示例中,服务 A 和 服务 B 是使用默认链路延续策略的 Elastic 监控的服务。服务 A 的采样率为 .25 (25%),并且 服务 B 中会尊重此采样决策。服务 C 是一个使用 restart 链路延续策略的 Elastic 监控的服务,并且采样率为 1 (100%)。由于它使用 restart,因此不会在 服务 C 中尊重上游采样率,并且所有四个链路都将在 服务 C 中作为新链路进行采样。最终结果将是五个采样的链路。
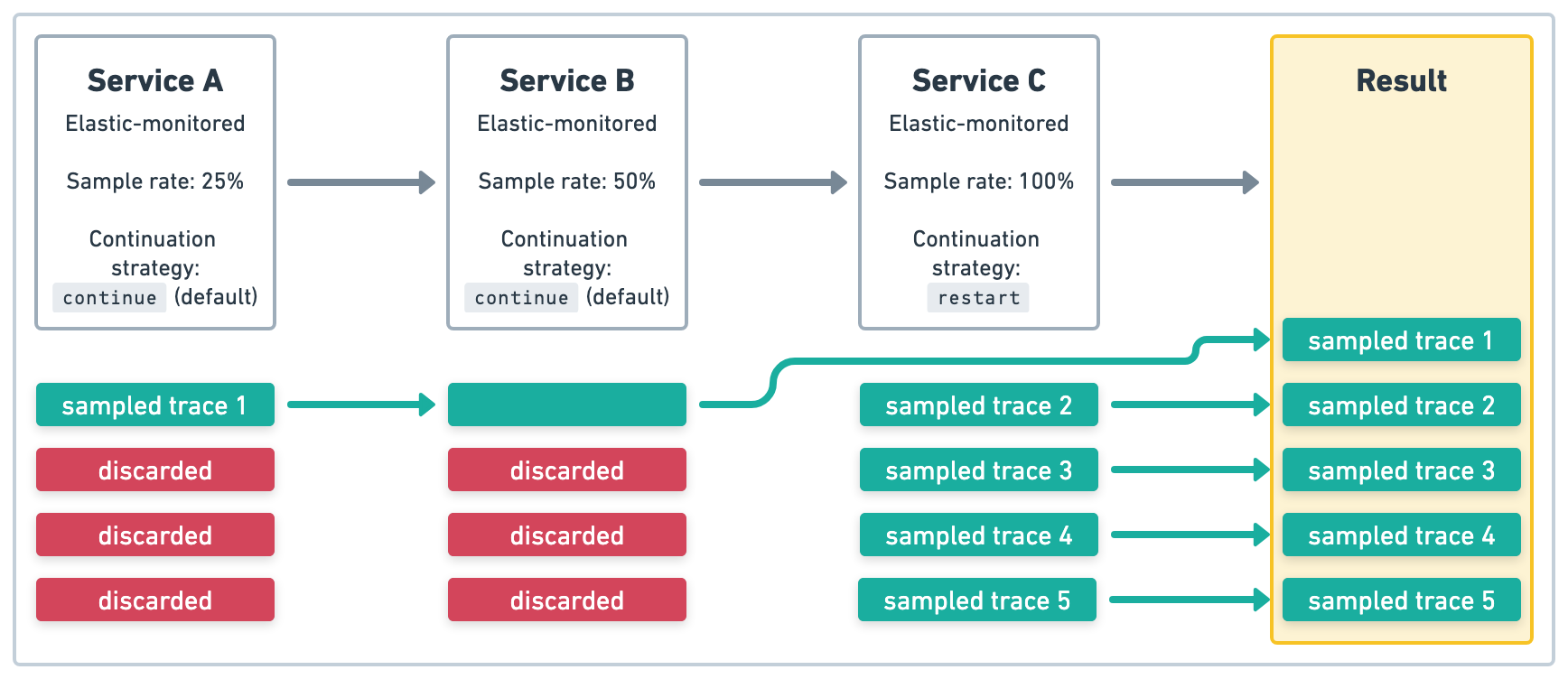
restart 链路延续策略OpenTelemetry
编辑基于头部的采样直接在 APM 代理和 SDK 中实现。必须在服务和托管摄取服务之间传播采样率,以便生成准确的指标。
OpenTelemetry 提供了多个采样器。但是,大多数采样器不会传播采样率。这会导致基于 span 的指标不准确,例如 APM 吞吐量、延迟和错误指标。
为了在使用 OpenTelemetry 进行基于头部的采样时获得准确的基于 span 的指标,您必须使用一致的概率采样器。这些采样器在服务和托管摄取服务之间传播采样率,从而生成准确的指标。
OpenTelemetry 并非在所有语言中都提供一致的概率采样器。OpenTelemetry 用户应考虑改用基于尾部的采样。
有关一致概率采样器的可用性的更多信息,请参阅您喜欢的 OpenTelemetry 代理或 SDK 的文档。
基于尾部的采样
编辑在基于尾部的采样中,每个链路的采样决策是在链路完成后做出的。这意味着将根据一组规则或策略分析所有链路,这些规则或策略将确定采样率。
与基于头部的采样不同,每个链路被采样的概率不相同。由于较慢的链路比快的链路更有趣,因此基于尾部的采样使用加权随机采样,因此具有较长根事务持续时间的链路比具有快速根事务持续时间的链路更有可能被采样。
基于尾部的采样的缺点是,它会导致更多数据从 APM 代理发送到 APM Server。因此,APM Server 将比使用基于头部的采样使用更多的 CPU、内存和磁盘。但是,由于基于尾部的采样决策发生在 APM Server 中,因此从 APM Server 到 Elasticsearch 传输的数据较少。因此,在您的检测服务附近运行 APM Server 可以减少基于尾部的采样带来的任何传输成本增加。
请参阅配置基于尾部的采样以开始使用。
基于尾部的采样的分布式追踪
编辑使用基于尾部的采样时,会观察所有链路,并且只有在链路完成后才会做出采样决策。
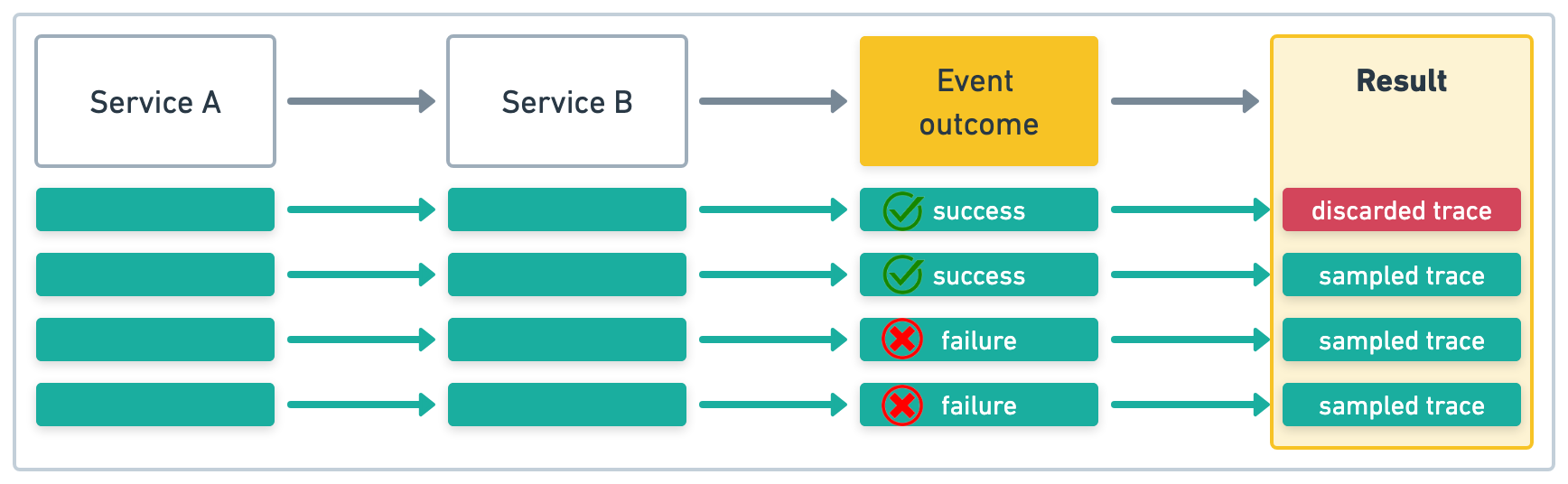
在此示例中,服务 A 启动四个事务。如果我们对于结果为 success 的链路的采样率为 .5 (50%),对于结果为 failure 的链路的采样率为 1 (100%),则采样的链路将如下所示
使用基于尾部的采样的 OpenTelemetry
编辑基于尾部的采样完全在 APM Server 中实现,并且可以与 Elastic APM 代理或 OpenTelemetry SDK 发送的链路一起使用。
由于在使用 tailsamplingprocessor 时存在OpenTelemetry 基于尾部的采样的限制,我们建议改用 APM Server 基于尾部的采样。
采样数据和可视化
编辑采样的链路会保留与其关联的所有数据。非采样的链路会丢弃所有span 和 事务数据1。无论采样决策如何,所有链路都会保留错误数据。
APM 应用程序中的某些可视化(如延迟)由聚合的事务和 span 指标提供支持。这些指标的计算方式取决于所用的采样方法
- 基于头部的采样:指标基于所有采样的事件计算。
- 基于尾部的采样:指标基于所有事件计算,无论最终是否采样。
- 基于头部和尾部的采样:当两种方法一起使用时,指标是基于头部采样策略所采样的所有事件计算的。
对于所有采样方法,指标会根据头部采样策略的逆采样率进行加权,以提供总体数量的估计值。例如,如果您的头部采样率为 5%,则每个采样的追踪会被计为 20。随着延迟的方差增加或头部采样率降低,这些计算中的误差水平可能会增加。
这些计算方法确保 APM 应用程序在给定使用的采样策略的情况下提供尽可能准确的指标,同时还会考虑头部采样率来估计追踪的完整数量。
1 真实用户监控 (RUM) 追踪是此规则的一个例外。利用 RUM 数据的 Kibana 应用程序依赖于事务事件,因此未采样的 RUM 追踪会保留事务数据 — 仅丢弃 span 数据。
采样率
编辑最佳采样率是多少?遗憾的是,没有统一的标准。采样取决于您的数据、应用程序的吞吐量、数据保留策略和其他因素。从 .1% 到 100% 的采样率都被认为是正常的。您可能会针对不同的场景决定采用唯一的采样率。以下是一些示例:
- 流量明显高于其他服务的服务可以安全地以较低的采样率进行采样
- 比其他路由更重要的路由可以以更高的采样率进行采样
- 生产服务环境可能比开发环境需要更高的采样率
- 失败的追踪结果可能比成功的追踪更有趣 — 因此需要更高的采样率
无论如何,注重成本的客户可能会对较低的采样率感到满意。
配置基于头部的采样
编辑有三种方法可以调整 APM 代理的基于头部的采样率
动态配置
编辑可以使用 Kibana 中的 APM 代理配置,在每个服务和每个环境的基础上动态更改事务采样率(无需重新部署)。
Kibana API 配置
编辑APM 代理配置公开了一个 API,可用于以编程方式更改代理的采样率。在代理配置 API 参考中提供了一个示例。
APM 代理配置
编辑每个代理都提供一个配置值,用于设置事务采样率。有关更多详细信息,请参阅相关代理的文档
- Go:
ELASTIC_APM_TRANSACTION_SAMPLE_RATE - Java:
transaction_sample_rate - .NET:
TransactionSampleRate - Node.js:
transactionSampleRate - PHP:
transaction_sample_rate - Python:
transaction_sample_rate - Ruby:
transaction_sample_rate
配置基于尾部的采样
编辑使用启用基于尾部的采样来启用基于尾部的采样。启用后,跟踪事件将映射到采样策略。每个采样策略都必须指定一个采样率,并且可以选择指定其他条件。要使跟踪事件匹配策略,所有策略条件都必须为真。
跟踪事件按照指定的顺序与策略匹配。每个策略列表都必须以默认策略结尾 — 即仅指定采样率的策略。此默认策略用于捕获与更严格的策略不匹配的剩余跟踪事件。要求此默认策略可确保仅有意丢弃跟踪。如果启用基于尾部的采样并发送与任何策略都不匹配的事务,则 APM Server 将拒绝该事务,并显示错误 no matching policy。
请注意,从 8.3.1 版本开始,APM Server 实现了 3GB 的默认存储限制,但是,由于限制的计算和强制方式,实际磁盘空间仍可能会略微超出限制。
配置示例
编辑此示例定义了三个基于尾部的采样策略
- sample_rate: 1 service.environment: production trace.name: "GET /very_important_route" - sample_rate: .01 service.environment: production trace.name: "GET /not_important_route" - sample_rate: .1
|
对 |
|
|
对 |
|
|
默认策略以 10% 的采样率对所有剩余的跟踪进行采样,例如,不同环境(如 |
配置参考
编辑顶级基于尾部的采样设置
编辑启用基于尾部的采样
编辑设置为 true 可启用基于尾部的采样。默认禁用。(bool)
APM Server 二进制文件 |
|
Fleet 管理 |
|
间隔
编辑多个 APM Server 的同步间隔。应在数十秒或几分钟的范围内。默认值:1m(1 分钟)。(duration)
APM Server 二进制文件 |
|
Fleet 管理 |
|
策略
编辑用于将根事务与采样率匹配的条件。
策略将跟踪事件映射到采样率。每个策略都必须指定一个采样率。跟踪事件按照指定的顺序与策略匹配。要使跟踪事件匹配,所有策略条件都必须为真。每个策略列表应以仅指定采样率的策略结尾。此最终策略用于捕获与更严格的策略不匹配的剩余跟踪事件。( []policy)
APM Server 二进制文件 |
|
Fleet 管理 |
|
存储限制
编辑为匹配尾部采样策略的跟踪事件分配的存储空间量。注意:将此限制设置高于允许的空间可能会导致 APM Server 运行不正常。
如果配置的存储限制不足,则会记录“配置的存储限制已达到”。当达到存储限制时,事件将绕过采样并将始终被索引。
默认值:3GB。(text)
APM Server 二进制文件 |
|
Fleet 管理 |
|
策略设置
编辑sample_rate
编辑要应用于与此策略匹配的跟踪事件的采样率。每个策略中都必须提供。
采样率必须大于或等于 0 且小于或等于 1。例如,sample_rate 为 0.01 表示将对与该策略匹配的 1% 的跟踪事件进行采样。 sample_rate 为 1 表示将对与该策略匹配的 100% 的跟踪事件进行采样。(int)
trace.name
编辑要匹配策略的事件的跟踪名称。当配置的 trace.name 与跟踪的根事务的 transaction.name 匹配时,会发生匹配。根事务是任何没有 parent.id 的事务。(string)
trace.outcome
编辑要匹配策略的事件的跟踪结果。当配置的 trace.outcome 与跟踪的 event.outcome 字段匹配时,会发生匹配。跟踪结果可以是 success、failure 或 unknown。(string)
service.name
编辑要匹配策略的事件的服务名称。(string)
service.environment
编辑要匹配策略的事件的服务环境。(string)