- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
处理延迟数据
编辑处理延迟数据
编辑延迟数据是指索引较晚的文档。也就是说,它是与您的数据源已处理过的时间相关的数据,因此不会被您的异常检测任务分析。
创建数据源时,您可以指定 query_delay 设置。此设置使数据源可以等待一段时间,超过实时时间,这意味着在此期间的任何“延迟”数据都会在数据源尝试收集之前完全索引。但是,如果该设置设置得太低,数据源可能会在数据被索引之前查询数据,从而错过该文档。相反,如果设置得太高,分析会离实时时间更远。达成的平衡取决于每个用例和集群的环境因素。
如果出现错误,提示 Datafeed missed XXXX documents due to ingest latency,请考虑增加 ‘query_delay’ 的值。如果这没有帮助,请调查摄取延迟及其原因。您可以通过比较事件和摄取时间戳来做到这一点。高延迟通常是由大量摄取的文档、摄取管道配置错误或系统时钟不一致引起的。
为什么担心延迟数据?
编辑如果数据是随机延迟的(因此在分析中丢失),则某些类型函数的结果不会受到太大影响。在这些情况下,由于延迟数据是随机分布的,所以最终结果是正常的。一个例子是大型数据集合中某个字段的 mean 指标。在这种情况下,检查延迟数据可能不会带来太多好处。但是,如果数据持续延迟,则使用 low_count 函数的异常检测任务可能会提供误报。在这种情况下,查看是否在记录异常之后有数据传入会很有用,以便您可以确定下一步的行动方案。
我们如何检测延迟数据?
编辑除了 query_delay 字段之外,还有一个延迟数据检查配置,使您可以配置数据源以在过去查找延迟数据。每 15 分钟或每 check_window (以较小者为准),数据源会在配置的索引上触发文档搜索。此搜索会在一个时间跨度内查找,该时间跨度的长度为 check_window,以最新完成的存储桶结束。该时间跨度被划分为多个存储桶,其长度等于相关异常检测任务的存储桶跨度。然后将这些存储桶的 doc_count 与任务的完成分析存储桶进行比较,以查看自分析以来是否有任何数据到达。如果确实由于摄取延迟而缺少数据,则会通知最终用户。例如,您可以在 Kibana 中看到这些延迟发生时段的注释
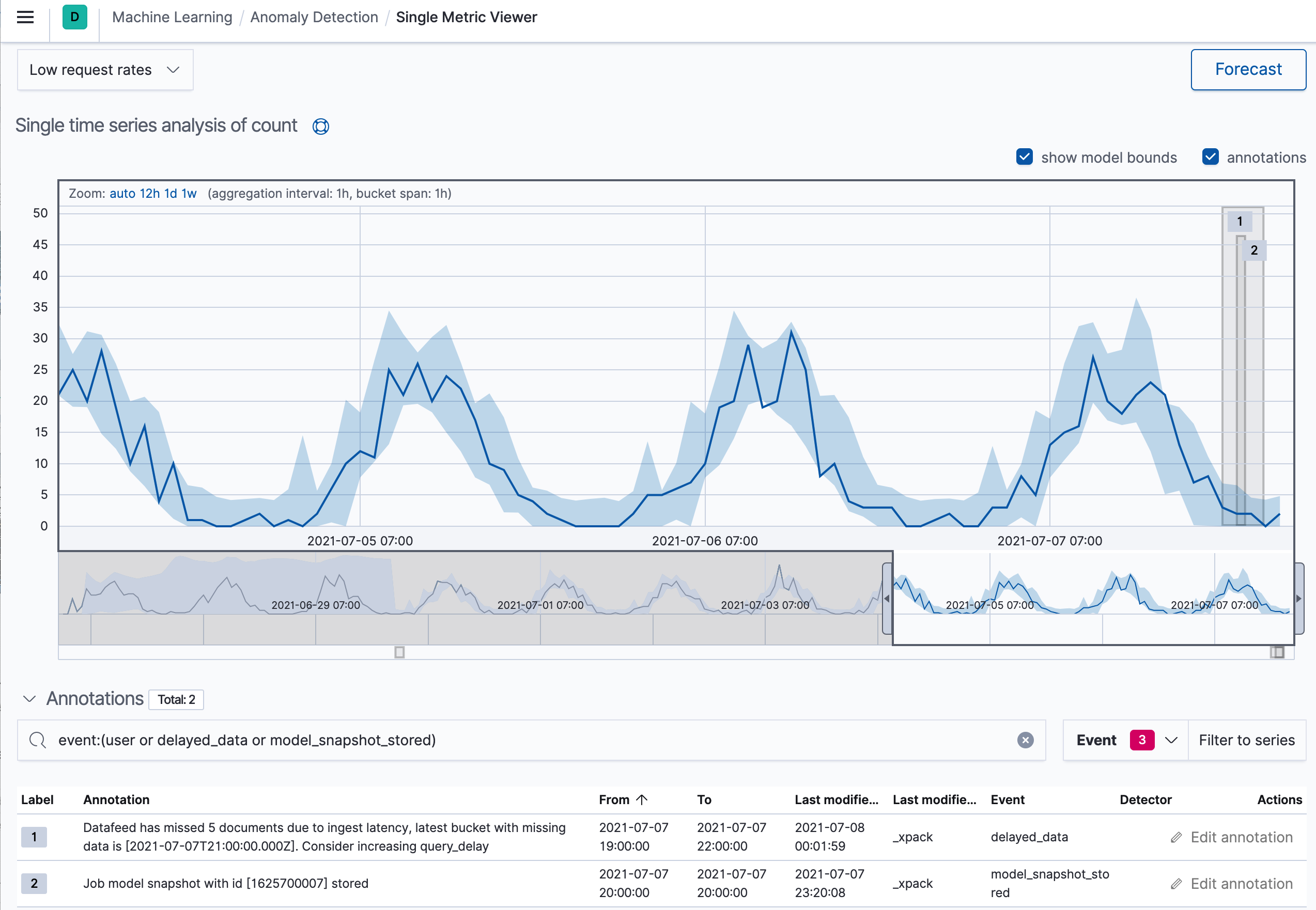
在以下情况下,延迟数据检查将无法正常工作:
- 如果数据源使用过滤数据的聚合,
- 如果数据源使用聚合,并且任务的
analysis_config没有将其summary_count_field_name设置为doc_count, - 如果数据源不使用聚合,并且
summary_count_field_name设置为任何值。
如果数据源使用聚合,请将任务的 summary_count_field_name 设置为 doc_count。如果 summary_count_field_name 设置为 doc_count 以外的任何值,则必须禁用数据源的延迟数据检查。
在异常检测任务管理页面的注释选项卡中,还有另一个用于可视化延迟数据的工具
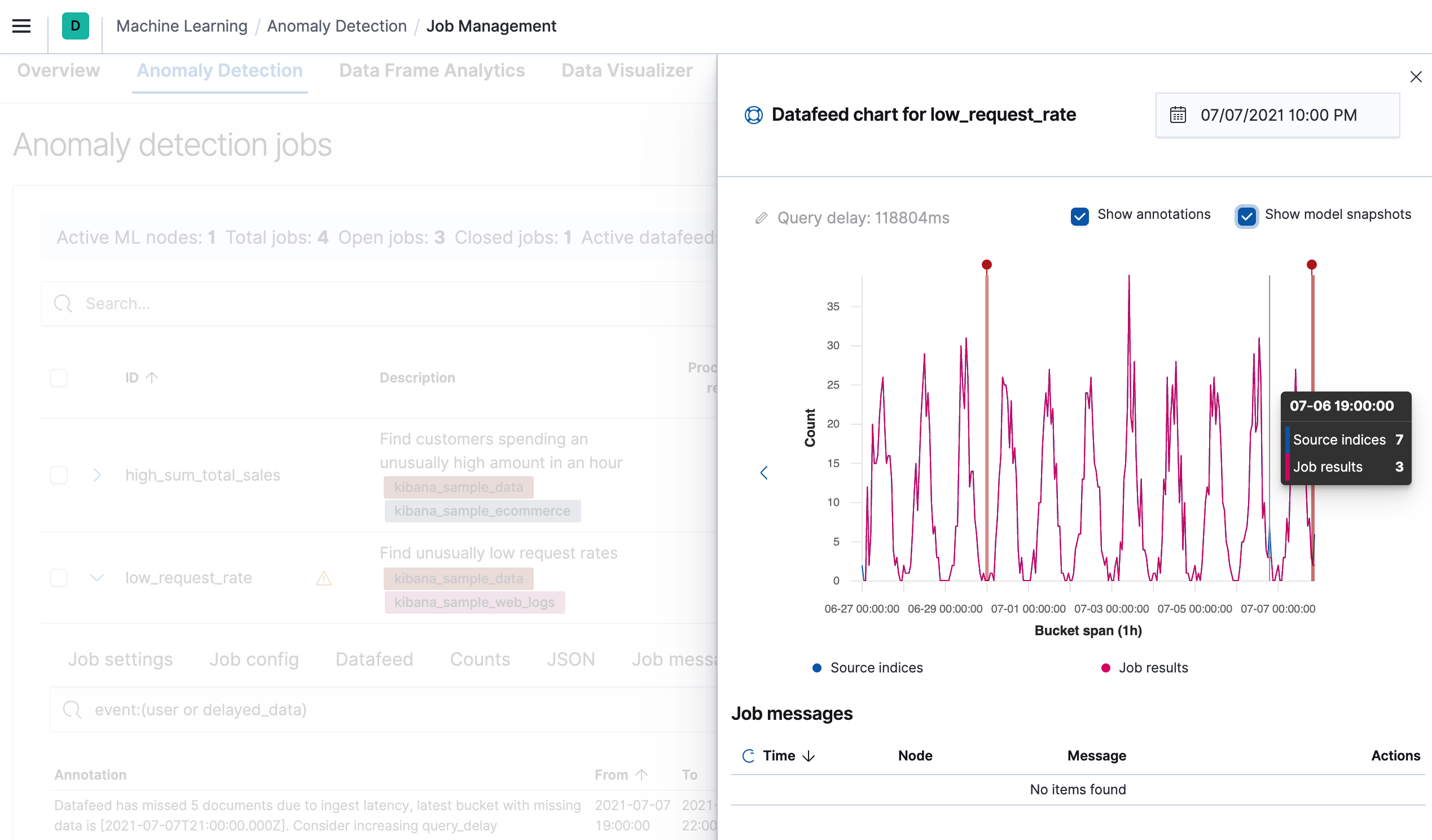
如何处理延迟数据?
编辑最常见的做法是直接不做任何处理。对于许多函数和情况,忽略数据是可以接受的。但是,如果延迟数据的量太大或情况需要,则接下来要考虑的操作是增加数据源的 query_delay。这种增加的延迟允许更多时间来索引数据。但是,如果您有实时约束,则增加延迟可能不是理想的。在这种情况下,您必须调整以获得更好的索引速度。
On this page