- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
E5 – 来自双向编码器表征的嵌入
编辑E5 – 来自双向编码器表征的嵌入
编辑来自双向编码器表征的嵌入 - 或 E5 - 是一种自然语言处理模型,使您能够通过使用密集向量表示执行多语言语义搜索。建议将此模型用于非英语语言的文档和查询。如果您想对英语文档执行语义搜索,请使用 ELSER 模型。
语义搜索 基于上下文含义和用户意图,而不是精确的关键词匹配,为您提供搜索结果。
E5 有两个版本:一个跨平台版本,可在任何硬件上运行,以及一个针对 Intel® 芯片优化的版本。“模型管理” > “已训练模型”页面会根据您的集群硬件显示建议部署的 E5 版本。但是,推荐使用 E5 的方法是通过 推理 API 作为服务,这样可以更轻松地下载和部署模型,并且您无需从不同版本中选择。
请参阅 HuggingFace 上 multilingual-e5-small 和 multilingual-e5-small-optimized 模型的模型卡,以获取包括许可在内的更多信息。
要求
编辑要使用 E5,您必须拥有 适用于语义搜索的相应订阅级别或已激活的试用期。
建议为您的 E5 部署启用已训练模型自动缩放。请参阅 已训练模型自动缩放 了解更多信息。
下载和部署 E5
编辑下载和部署 E5 最简单且推荐的方法是使用 推理 API。
- 在 Kibana 中,导航到“Dev Console”。
-
通过运行以下 API 请求,使用
elasticsearch服务创建一个推理端点PUT _inference/text_embedding/my-e5-model { "service": "elasticsearch", "service_settings": { "num_allocations": 1, "num_threads": 1, "model_id": ".multilingual-e5-small" } }
API 请求会自动启动模型下载,然后部署模型。
请参阅 elasticsearch 推理服务文档,以了解有关可用设置的更多信息。
创建 E5 推理端点后,即可将其用于语义搜索。在 Elastic Stack 中执行语义搜索的最简单方法是 遵循 semantic_text 工作流。
下载和部署 E5 的替代方法
编辑您还可以从“机器学习” > “已训练模型”、“搜索” > “索引”或通过 Dev Console 中的已训练模型 API 下载和部署 E5 模型。
在大多数情况下,首选版本是“Intel 和 Linux 优化”模型,建议下载和部署该版本。
使用“已训练模型”页面
使用“已训练模型”页面
编辑- 在 Kibana 中,导航到“机器学习” > “已训练模型”。E5 可以在已训练模型列表中找到。有两个可用版本:一个可在任何硬件上运行的可移植版本和一个针对 Intel® 芯片优化的版本。您可以根据硬件配置查看建议使用的模型。
-
点击“添加已训练模型”按钮。在打开的模态窗口中,选择要使用的 E5 模型版本。根据您的硬件配置推荐给您的模型会被突出显示。点击“下载”。您可以在“通知”页面上查看下载状态。
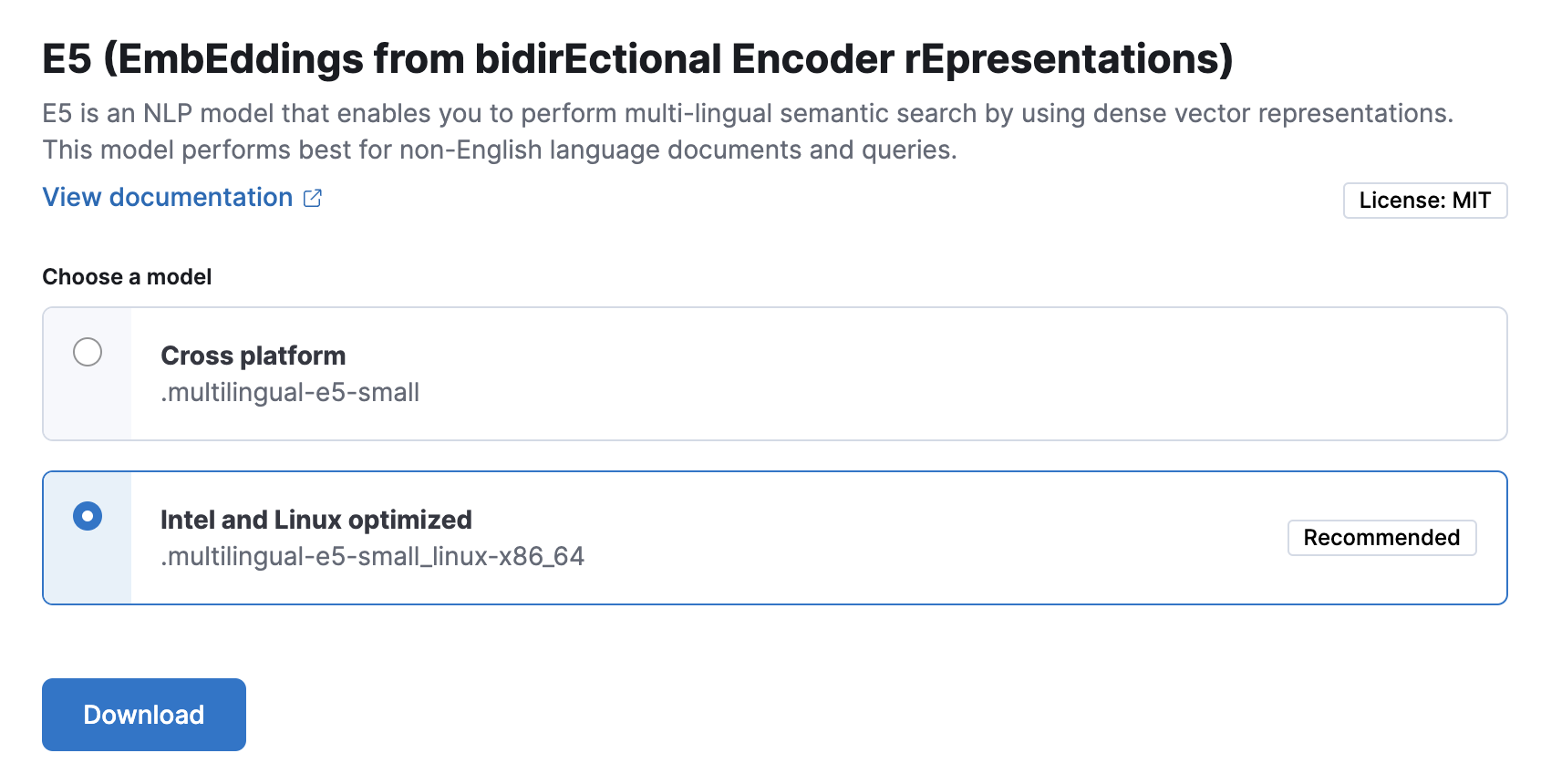
或者,点击已训练模型列表的“操作”下的“下载模型”按钮。
- 下载完成后,点击“开始部署”按钮开始部署。
-
提供部署 ID,选择优先级,并设置每次分配的分配数和线程数的值。
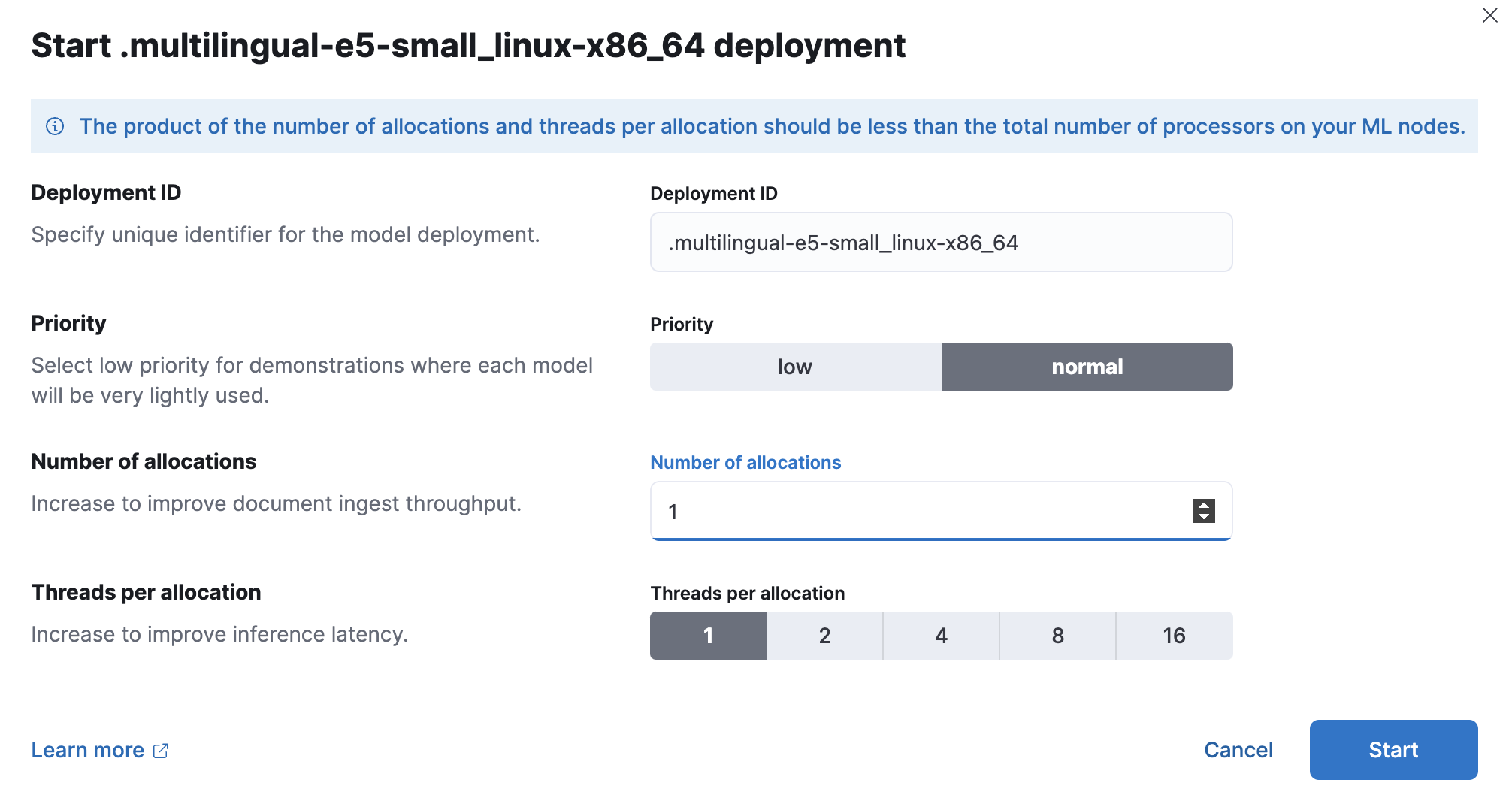
- 点击“开始”。
使用搜索索引 UI
使用搜索索引 UI
编辑或者,您可以使用搜索索引 UI 下载 E5 模型并将其部署到推理管道。
- 在 Kibana 中,导航到“搜索” > “索引”。
- 从列表中选择要在其中使用 E5 的推理管道所在的索引。
- 导航到“管道”选项卡。
-
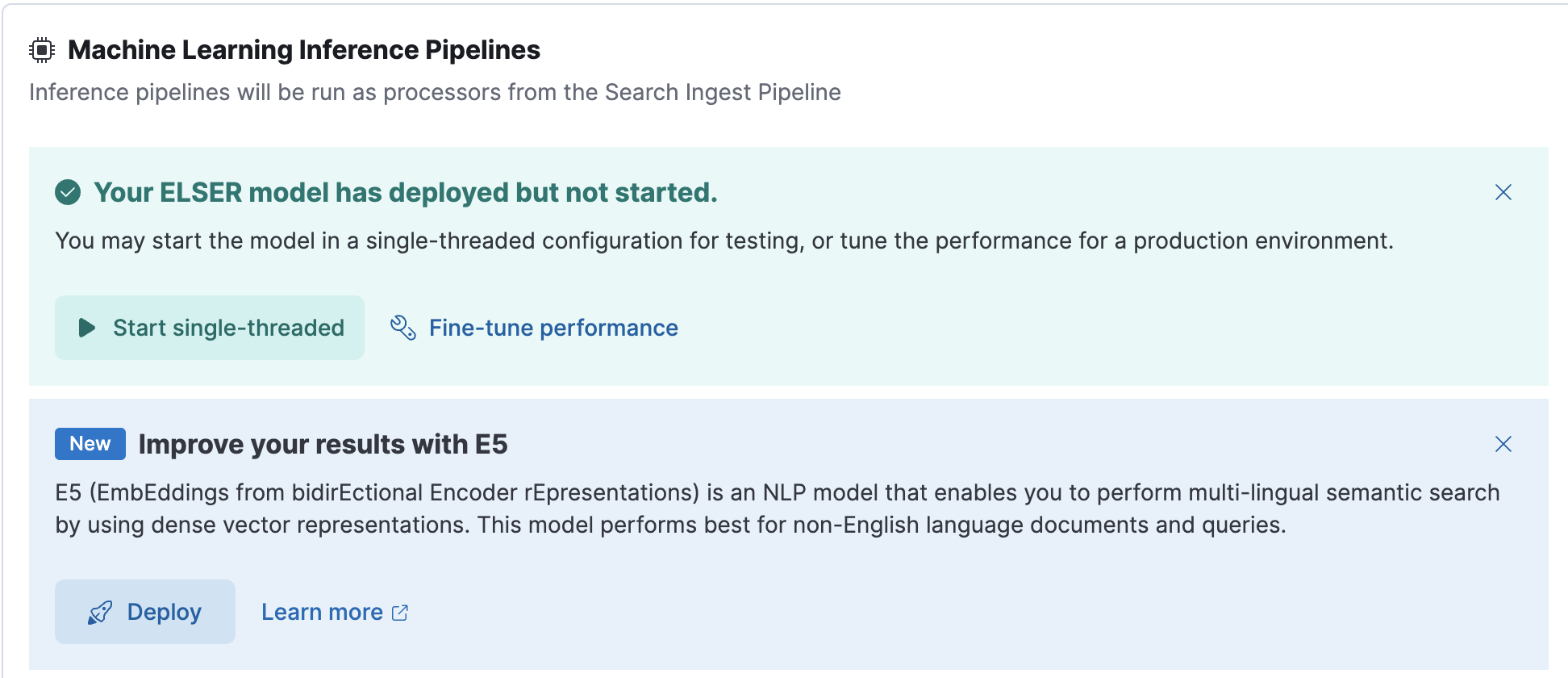
在“机器学习推理管道”下,点击“使用 E5 改进结果”部分中的“部署”按钮,开始下载 E5 模型。这可能需要几分钟,具体取决于您的网络。
-
下载模型后,点击“启动单线程”按钮以使用基本配置启动模型,或选择“微调性能”选项以导航到“已训练模型”页面,您可以在其中配置模型部署。

部署并启动 E5 模型后,即可在管道中使用它。
在 Dev Console 中使用已训练模型 API
在 Dev Console 中使用已训练模型 API
编辑- 在 Kibana 中,导航到“Dev Console”。
-
通过运行以下 API 调用创建 E5 模型配置
PUT _ml/trained_models/.multilingual-e5-small { "input": { "field_names": ["text_field"] } }
如果模型尚未下载,API 调用会自动启动模型下载。
-
使用 启动已训练模型部署 API 和部署 ID 来部署模型
POST _ml/trained_models/.multilingual-e5-small/deployment/_start?deployment_id=for_search
在气隙环境中部署 E5 模型
编辑如果您想在气隙环境中安装 E5,您有以下选项:* 将模型工件放入所有符合主节点条件的节点的配置目录内的目录中(对于 multilingual-e5-small 和 multilingual-e5-small-linux-x86-64)* 通过使用 HuggingFace 安装模型(仅适用于 multilingual-e5-small 模型)。
模型工件文件
编辑对于 multilingual-e5-small 模型,您的系统中需要以下文件
https://ml-models.elastic.co/multilingual-e5-small.metadata.json https://ml-models.elastic.co/multilingual-e5-small.pt https://ml-models.elastic.co/multilingual-e5-small.vocab.json
对于优化版本,您的系统中需要以下文件
https://ml-models.elastic.co/multilingual-e5-small_linux-x86_64.metadata.json https://ml-models.elastic.co/multilingual-e5-small_linux-x86_64.pt https://ml-models.elastic.co/multilingual-e5-small_linux-x86_64.vocab.json
使用基于文件的访问
编辑对于基于文件的访问,请按照以下步骤操作
- 下载 模型工件文件。
- 将文件放入 Elasticsearch 部署的
config目录内的models子目录中。 -
通过将以下行添加到
config/elasticsearch.yml文件,将 Elasticsearch 部署指向模型目录xpack.ml.model_repository: file://${path.home}/config/models/` - 在所有符合主节点条件的节点上重复步骤 2 和步骤 3。
- 重启符合主节点条件的节点,一次一个。
- 导航到 Kibana 中的“已训练模型”页面,E5 可以在已训练模型列表中找到。
- 点击“添加已训练模型”按钮,选择您在步骤 1 中下载并要部署的 E5 模型版本,然后点击“下载”。选定的模型将从您在步骤 2 中放入的模型目录中下载。
- 下载完成后,点击“开始部署”按钮开始部署。
- 提供部署 ID,选择优先级,并设置每次分配的分配数和线程数的值。
- 点击“开始”。
使用 HuggingFace 存储库
编辑您可以通过将 eland_import_hub_model 脚本指向模型的本地文件,在受限或封闭网络中安装 multilingual-e5-small 模型。
对于离线安装,首先需要在本地克隆模型,您的系统中需要安装 Git 和 Git Large File Storage。
-
使用模型 URL 从 Hugging Face 克隆 E5 模型。
git clone https://hugging-face.cn/elastic/multilingual-e5-small
该命令会在
multilingual-e5-small目录中生成模型的本地副本。 -
使用
eland_import_hub_model脚本,并将--hub-model-id设置为克隆模型的目录以进行安装eland_import_hub_model \ --url 'XXXX' \ --hub-model-id /PATH/TO/MODEL \ --task-type text_embedding \ --es-username elastic --es-password XXX \ --es-model-id multilingual-e5-small
如果您使用 Docker 映像运行
eland_import_hub_model,则必须绑定挂载模型目录,以便容器可以读取文件。docker run --mount type=bind,source=/PATH/TO/MODELS,destination=/models,readonly -it --rm docker.elastic.co/eland/eland \ eland_import_hub_model \ --url 'XXXX' \ --hub-model-id /models/multilingual-e5-small \ --task-type text_embedding \ --es-username elastic --es-password XXX \ --es-model-id multilingual-e5-small
上传到 Elasticsearch 后,模型的 ID 将由
--es-model-id指定。如果未设置,则模型 ID 从--hub-model-id派生;空格和路径分隔符会转换为双下划线__。
免责声明
编辑客户可能会添加第三方已训练模型以便在 Elastic 中进行管理。这些模型不归 Elastic 所有。虽然 Elastic 将根据文档支持这些模型在性能方面的集成,但您理解并同意 Elastic 对第三方模型或其可能使用的底层训练数据没有控制权或责任。
此 e5 模型,按照定义,托管、集成并与我们的其他 Elastic 软件结合使用时,均受我们的标准保修条款保护。
On this page