- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
特征重要性
编辑特征重要性
编辑特征重要性值指示哪些字段对分类或回归分析生成的每个预测的影响最大。每个特征重要性值都有一个大小和一个方向(正或负),这表示每个字段(或数据点的特征)如何影响特定预测。
特征重要性的目的是帮助您确定预测是否合理。因变量和重要特征之间的关系是否得到您的领域知识的支持?您了解到的有关特定特征重要性的经验也可能会影响您在未来迭代的训练模型中是否包含这些特征的决定。
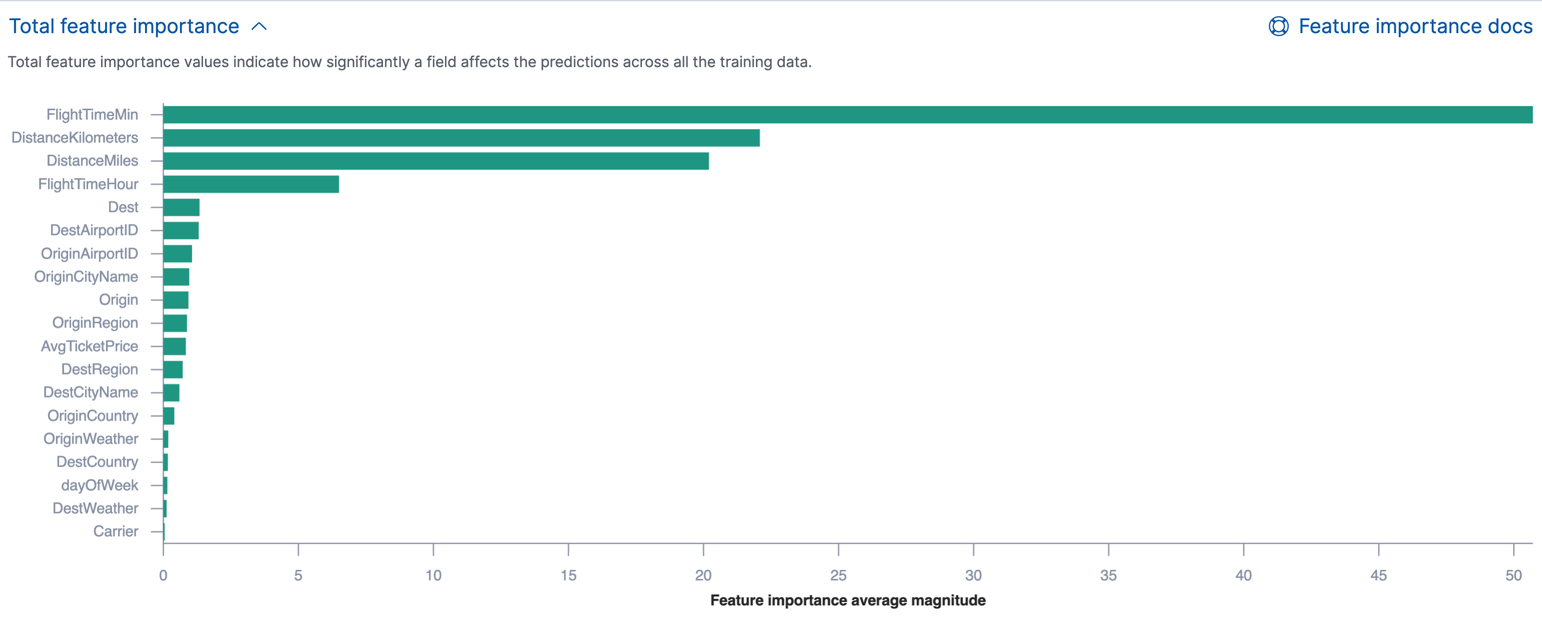
您可以在 Kibana 中或通过使用get trained model API查看所有训练数据中每个字段的特征重要性值的平均大小。例如,Kibana 在回归或二元分类分析结果中显示每个字段的总特征重要性,如下所示
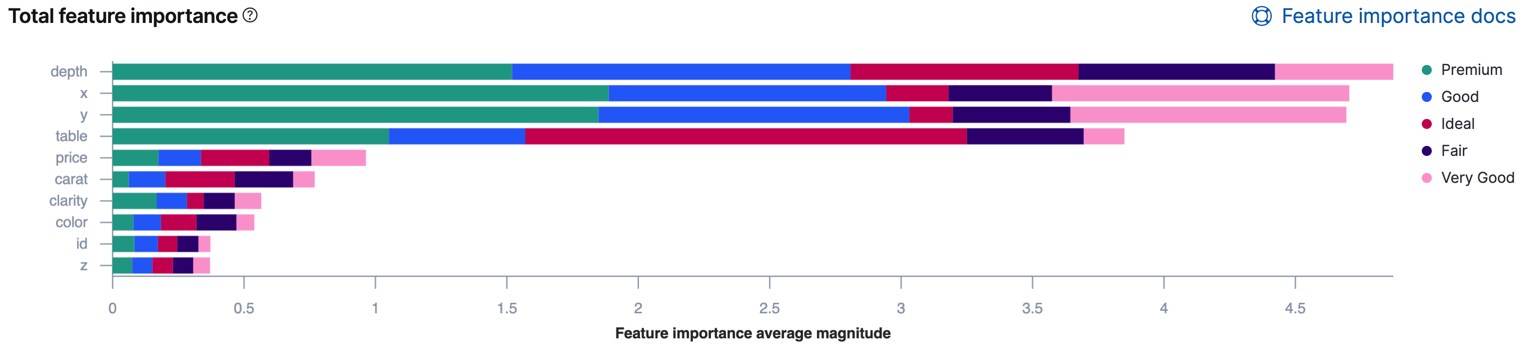
如果分类分析涉及两个以上的类,则 Kibana 使用颜色来显示每个字段的影响如何因类而异。例如
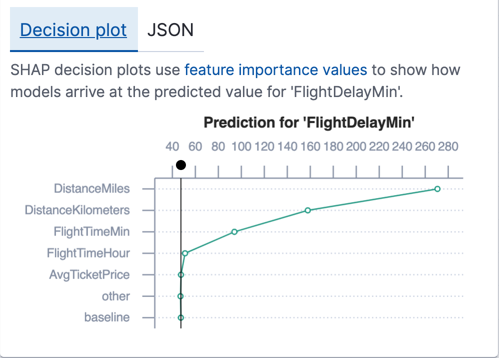
您还可以检查每个单独预测的特征重要性值。在 Kibana 中,您可以在 JSON 对象或决策图中查看这些值。对于回归分析,每个决策图都从一个共享基线开始,该基线是训练数据集中所有数据点的预测值的平均值。当您将特定数据点的所有特征重要性值添加到该基线时,您将得到数值预测值。如果特征重要性值为负,则它会降低预测值。如果特征重要性值为正,则它会增加预测值。例如
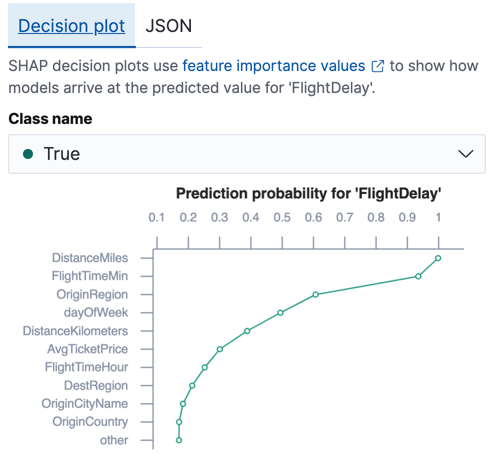
对于分类分析,特征重要性值的总和近似于每个数据点的预测对数几率。理解分类分析中特征重要性的最简单方法是查看 Kibana 中的决策图。对于每个数据点,都有一个图表显示每个特征对该类预测概率的相对影响。此信息可帮助您了解哪些特征会降低或增加预测概率。例如
默认情况下,不会计算特征重要性值。要生成此信息,在创建数据帧分析作业时,必须指定 num_top_feature_importance_values 属性。例如,请参阅在示例航班数据集中执行回归分析和在示例航班数据集中执行分类分析。
特征重要性值存储在目标索引中每个文档的机器学习结果字段中。每个文档的特征重要性值数量可能小于 num_top_feature_importance_values 属性值。例如,它仅返回对预测产生正面或负面影响的特征。
进一步阅读
编辑- Elastic Stack 中的特征重要性是使用 SHAP(SHapley Additive exPlanations)方法计算的,如 Lundberg, S. M., & Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In NeurIPS 2017 中所述。
- 使用 Elastic 机器学习进行数据帧分析的特征重要性.
- 数据帧分析的特征重要性(Jupyter 笔记本).
On this page