

什么是向量数据库?
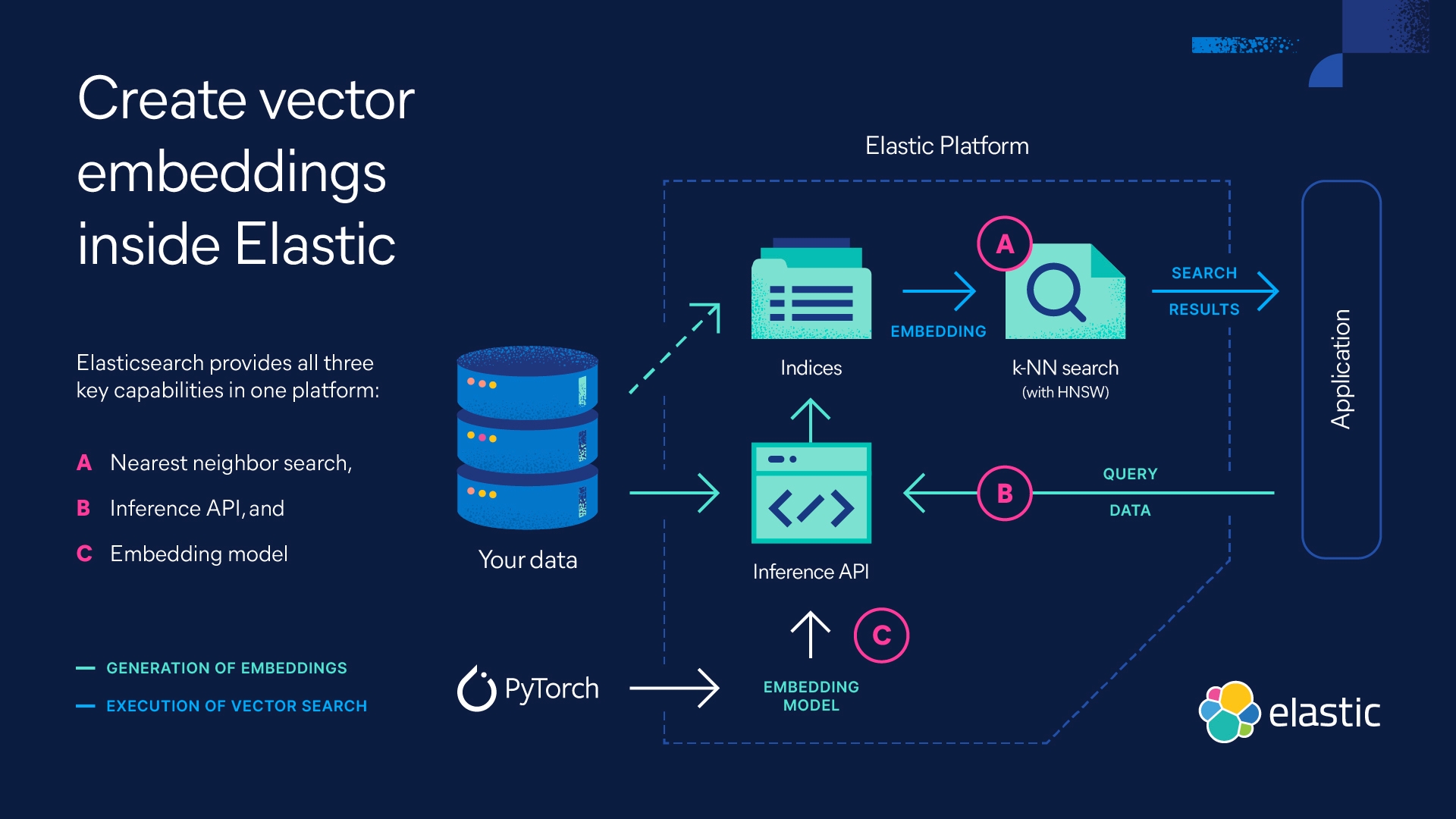
向量数据库如何工作?
向量数据库通过使用算法来索引和查询向量嵌入来工作。这些算法可以通过哈希、量化或基于图的搜索来实现近似最近邻 (ANN) 搜索。
为了检索信息,ANN 搜索会找到查询的最近向量邻居。近似最近邻搜索的计算量比kNN 搜索(已知最近邻,或真正的 k 最近邻算法)少,而且精度也较低。但是,它可以为高维向量的大型数据集高效且大规模地工作。
向量数据库管道如下所示
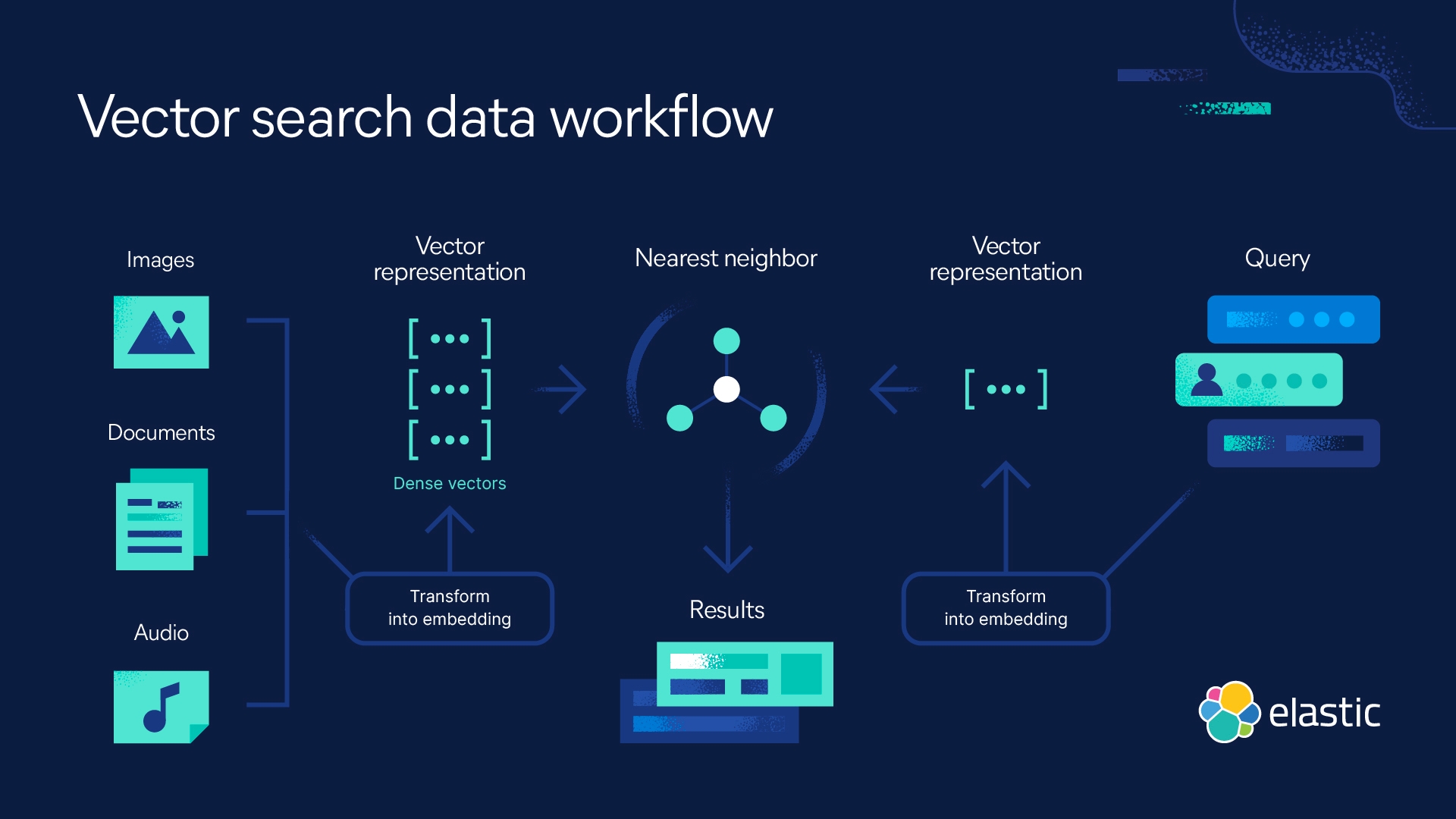
索引:使用哈希、量化或基于图的技术,向量数据库通过将向量映射到给定的数据结构来对其进行索引。这可以加快搜索速度。
- 哈希:哈希算法(例如局部敏感哈希 (LSH) 算法)最适合近似最近邻搜索,因为它能够快速得出结果并生成近似结果。LSH 使用哈希表(可以想象成数独谜题)来映射最近邻。查询将被哈希到表中,然后与同一表中的一组向量进行比较以确定相似性。
- 量化:量化技术(例如乘积量化 (PQ))会将向量分解成更小的部分,并用代码表示这些部分,然后将这些部分重新组合在一起。结果是向量及其组件的代码表示。这些代码的集合称为代码簿。在查询时,使用量化的向量数据库会将查询分解为代码,然后将其与代码簿进行匹配,以找到最相似的代码来生成结果。
- 基于图:图算法(例如分层可导航小世界 (HNSW) 算法)使用节点来表示向量。它对节点进行聚类并在相似节点之间绘制线条或边,从而创建分层图。当启动查询时,算法将导航图层次结构,以查找包含与查询向量最相似的向量的节点。
向量数据库还会索引数据对象的元数据。因此,向量数据库将包含两个索引:向量索引和元数据索引。
查询: 当向量数据库收到查询时,它会将索引的向量与查询向量进行比较,以确定最接近的向量邻居。为了确定最接近的邻居,向量数据库依赖于称为相似性度量的数学方法。存在不同类型的相似性度量
- 余弦相似度 建立在 -1 到 1 范围内的相似度。通过测量向量空间中两个向量之间的角度的余弦值,它可以确定方向完全相反的向量(用 -1 表示)、正交向量(用 0 表示)或相同向量(用 1 表示)。
- 欧几里得距离 通过测量向量之间的直线距离,确定 0 到无穷大范围内的相似度。相同的向量用 0 表示,而较大的值表示向量之间更大的差异。
- 点积 相似性度量在负无穷大到无穷大的范围内确定向量相似度。通过测量两个向量的模的乘积以及它们之间角度的余弦值,点积将负值分配给指向彼此相反方向的向量,0 分配给正交向量,将正值分配给指向同一方向的向量。
后处理: 向量数据库管道中的最后一步有时是后处理或后过滤,在此期间,向量数据库将使用不同的相似性度量来重新对最接近的邻居进行排名。在此阶段,数据库将根据元数据过滤搜索中识别出的查询的最接近邻居。
某些向量数据库可能会在运行向量搜索之前应用过滤器。在这种情况下,它被称为预处理或预过滤。
向量数据库的核心组件
向量数据库可能具有以下核心组件
- 性能和容错: 分片和复制过程确保向量数据库具有高性能和容错能力。分片涉及跨多个节点划分数据,而复制涉及在不同节点上制作多个数据副本。如果某个节点发生故障,这将实现容错并保持持续的性能。
- 监控功能: 为了确保性能和容错,向量数据库需要监控资源使用情况、查询性能和整体系统运行状况。
- 访问控制功能: 向量数据库还需要数据安全管理。访问控制规则确保合规性、责任制以及审核数据库使用情况的能力。这也意味着数据受到保护:只有具有权限的人才能访问,并且会保留用户活动记录。
- 可伸缩性和可调性: 良好的访问控制功能会影响向量数据库的可伸缩性和可调性。随着存储的数据量增加,水平扩展的能力变得必不可少。不同的插入和查询速率以及底层硬件的差异会影响应用程序的需求。
- 多个用户和数据隔离: 与可伸缩性和访问控制功能相结合,向量数据库应容纳多个用户或多租户。与此同时,向量数据库应启用数据隔离,以便任何用户活动(例如插入、删除或查询)对其他用户保持私密性,除非另有要求。
- 备份: 向量数据库创建定期数据备份。这是向量数据库的关键组件,以应对系统故障的情况——如果发生数据丢失或数据损坏,备份可以帮助将数据库恢复到以前的状态。这最大限度地减少了停机时间。
- API 和 SDK: 向量数据库使用 API 来实现用户友好的界面。API 是应用程序编程接口,或一种软件,使应用程序能够通过请求和响应彼此“对话”。API 层简化了向量搜索体验。SDK 或软件开发工具包通常会包装 API。它们是数据库用来通信和管理的编程语言。SDK 有助于开发者友好地使用向量数据库,因为他们在开发特定用例(语义搜索、推荐系统等)时不必担心底层结构。
向量数据库的应用
向量数据库用于人工智能、机器学习 (ML)、自然语言处理 (NLP) 和图像识别应用。
- 人工智能/机器学习应用: 向量数据库可以通过语义信息检索和长期记忆来提高人工智能能力。
- 自然语言处理应用:向量相似性搜索是向量数据库的一个关键组成部分,对于自然语言处理应用非常有用。向量数据库可以处理文本嵌入,这使得计算机能够“理解”人类语言或自然语言。
- 图像识别和检索应用: 向量数据库将图像转换为图像嵌入。通过相似性搜索,它们能够检索相似的图像或识别匹配的图像。
向量数据库还可以用于异常检测和人脸检测应用。
了解向量数据库如何为人工智能搜索提供支持。观看我们的网络研讨会,了解如何为您的项目构建现代搜索体验。
Elasticsearch 的向量数据库
Elasticsearch 包含一个用于向量搜索的向量数据库。Elastic 使开发人员能够使用 Elasticsearch Relevance Engine (ESRE)构建自己的向量搜索引擎。
借助 Elasticsearch 工具,您可以构建一个向量搜索引擎,它可以搜索非结构化和结构化数据,应用过滤器和分面,对文本和向量数据应用混合搜索,并利用文档和字段级安全性,同时在本地、云端或混合环境中运行。Elasticsearch 的向量数据库和搜索人工智能平台为开发人员提供全面的混合搜索功能,并访问来自顶级 LLM 提供商的创新成果。借助 Elastic 的低代码游乐场,开发人员可以在几分钟内使用自己的私有数据快速测试 LLM。
脚注
1 Gu, Huaping. "释放向量的力量:嵌入和向量数据库 - Linkedin." LinkedIn, 2023 年 4 月 2 日, www.linkedin.com/pulse/unleashing-power-vectors-embeddings-vector-databases-huaping-gu