- 可观测性其他版本
- 开始
- 应用程序和服务
- CI/CD
- 云
- 基础设施和主机
- 日志
- 故障排除
- 事件管理
- 数据集质量
- 可观测性 AI 助手
- 参考
创建服务级别目标 (SLO)
编辑创建服务级别目标 (SLO)
编辑要创建 SLO,请在主菜单中找到SLO,或使用全局搜索字段。
- 如果您是第一次创建 SLO,您将看到一个介绍页面。单击创建 SLO按钮。
- 如果您之前创建过 SLO,请单击页面右上角的创建新 SLO按钮。
从这里开始,完成以下步骤
为了使 SLO 正常工作,集群必须包含一个或多个同时具有 ingest 和 transform 角色的节点。这些角色可以存在于同一个节点上,也可以分布在不同的节点上。在 ESS 部署 (Elastic Cloud) 上,这由热节点处理,热节点同时充当 ingest 和 transform 节点。
定义您的 SLI
编辑要使用的 SLI 类型取决于您的数据位置
- 自定义 KQL — 基于来自服务的原始日志创建 SLI。
- 自定义指标 — 创建 SLI 以定义索引中指标字段的自定义等式。
- 时间片指标 — 基于使用多个聚合的自定义等式创建 SLI。
- 直方图指标 — 基于直方图指标创建 SLI。
- APM 延迟和 APM 可用性 — 基于使用应用程序性能监控 (APM) 的服务创建 SLI。
- Synthetics 可用性 — 基于您的合成监控器的可用性创建 SLI。
自定义 KQL
编辑基于您的任何 Elasticsearch 索引或数据视图创建指标。您定义两个查询:一个查询从您的索引中产生良好事件,另一个查询从您的索引中产生总事件。
示例:您可以基于 service-logs 定义自定义 KQL 指标,其中良好查询定义为 nested.field.response.latency <= 100 and nested.field.env : “production”,并且总查询定义为 nested.field.env : “production”。
在定义自定义 KQL SLI 时,设置以下字段
-
索引 — 您要作为 SLI 基础的数据视图或索引模式。例如,
service-logs。 - 时间戳字段 — 索引使用的时间戳字段。
- 查询筛选器 — 用于指定筛选索引文档的相关标准的 KQL 筛选器。
-
良好查询 — 产生被认为良好或成功的事件的查询。例如,
nested.field.response.latency <= 100 and nested.field.env : “production” -
总查询 — 产生用于计算 SLI 的所有事件的查询。例如,
nested.field.env : “production”。 -
分组依据 — 用于基于特定字段的值对数据进行分组的字段。例如,您可以按
url.domain字段进行分组,这将为所选字段的每个值创建单独的 SLO。
自定义指标
编辑创建指标以定义索引中指标字段的自定义等式。
示例:您可以将良好事件定义为字段 processor.processed 的总和,筛选器为 "processor.outcome: \"success\"",并将总事件定义为 processor.processed 的总和,筛选器为 "processor.outcome: *"。
在定义自定义指标 SLI 时,设置以下字段
-
源
-
索引 — 您要作为 SLI 基础的数据视图或索引模式。例如,
my-service-*。 - 时间戳字段 — 索引使用的时间戳字段。
-
查询筛选器 — 用于指定筛选索引文档的相关标准的 KQL 筛选器。例如,
'field.environment : "production" and service.name : "my-service"'。
-
索引 — 您要作为 SLI 基础的数据视图或索引模式。例如,
-
良好事件
-
指标 [A-Z] — 使用
sum聚合的良好事件的字段。例如,processor.processed。 -
筛选器 [A-Z] — 应用于良好事件的指标的筛选器。例如,
"processor.outcome: \"success\""。 -
等式 — 计算良好指标的等式。例如,
A。
-
指标 [A-Z] — 使用
-
总事件
-
指标 [A-Z] — 使用
sum聚合的总事件的字段。例如,processor.processed -
筛选器 [A-Z] — 应用于总事件的指标的筛选器。例如,
"processor.outcome: *" -
等式 — 计算总指标的等式。例如,
A。
-
指标 [A-Z] — 使用
-
分组依据 — 用于基于特定字段的值对数据进行分组的字段。例如,您可以按
url.domain字段进行分组,这将为所选字段的每个值创建单独的 SLO。
时间片指标
编辑基于使用统计聚合和阈值来确定切片是好还是坏的自定义等式创建指标。支持的聚合包括 Average、Max、Min、Sum、Cardinality、Last value、Std. deviation、Doc count 和 Percentile。该等式支持基本的数学和逻辑。
此指标要求您使用 Timeslices 预算方法。
示例:您可以定义一个指标来确定 Kubernetes StatefulSet 是否健康。首先,将查询筛选器设置为 orchestrator.cluster.name: "elastic-k8s" AND kubernetes.namespace: "my-ns" AND data_stream.dataset: "kubernetes.state_statefulset"。然后,您定义一个比较就绪(健康)副本数和观察到的副本数的等式:A == B ? 1 : 0,其中 A 检索 kubernetes.statefulset.replicas.ready 的最后一个值,而 B 检索 kubernetes.statefulset.replicas.observed 的最后一个值。如果条件 A == B 为真(表示副本数相同),则等式返回 1,否则返回 0。如果该值小于 1,则可以确定 Kubernetes StatefulSet 不健康。
在定义时间片指标 SLI 时,设置以下字段
-
源
-
索引 — 您要作为 SLI 基础的数据视图或索引模式。例如,
metrics-*:metrics-*。 - 时间戳字段 — 索引使用的时间戳字段。
-
查询筛选器 — 用于指定筛选索引文档的相关标准的 KQL 筛选器。例如,
orchestrator.cluster.name: "elastic-k8s" AND kubernetes.namespace: "my-ns" AND data_stream.dataset: "kubernetes.state_statefulset"。
-
索引 — 您要作为 SLI 基础的数据视图或索引模式。例如,
-
指标定义
- 聚合 [A-Z] — 要使用的聚合类型。
-
字段 [A-Z] — 要在聚合中使用的字段。例如,
kubernetes.statefulset.replicas.ready。 - 筛选器 [A-Z] — 要应用于指标的筛选器。
-
等式 — 计算总指标的等式。例如,
A == B ? 1 : 0。 - 比较器 - 要执行的比较类型。
- 阈值 - 要与比较器一起使用以确定切片是好还是坏的值。
直方图指标
编辑直方图以压缩格式记录数据,并且可以记录延迟和延迟指标。您可以使用 range 聚合或 value_count 聚合为良好事件和总事件创建基于直方图指标的 SLI。两种事件类型都支持使用 KQL 查询进行筛选。
当使用 range 聚合时,范围的 from 和 to 阈值都是必需的,并且事件是该范围内的事件总数。范围包括 from 值,但不包括 to 值。
示例:您可以使用 processor.latency 字段定义良好事件,筛选器为 "processor.outcome: \"success\"",并使用 processor.latency 字段定义总事件,筛选器为 "processor.outcome: *"。
在定义直方图指标 SLI 时,设置以下字段
-
源
-
索引 — 您要作为 SLI 基础的数据视图或索引模式。例如,
my-service-*。 - 时间戳字段 — 索引使用的时间戳字段。
-
查询筛选器 — 用于指定筛选索引文档的相关标准的 KQL 筛选器。例如,
field.environment : "production" and service.name : "my-service"。
-
索引 — 您要作为 SLI 基础的数据视图或索引模式。例如,
-
良好事件
- 聚合 — 要用于良好事件的聚合类型,可以是值计数或范围。
-
字段 — 用于聚合被认为良好或成功的事件的字段。例如,
processor.latency。 -
自 —(仅限
range聚合)良好事件范围的起始值。例如,0。 -
至 —(仅限
range聚合)良好事件范围的结束值。例如,100。 -
KQL 筛选器 — 良好事件的筛选器。例如,
"processor.outcome: \"success\""。
-
总事件
- 聚合 — 用于聚合总事件的类型,可以是 值计数 或 范围。
-
字段 — 用于聚合总事件的字段。例如,
processor.latency。 -
从 —(仅限
range聚合)总事件范围的起始值。例如,0。 -
到 —(仅限
range聚合)总事件范围的结束值。例如,100。 -
KQL 过滤器 — 用于总事件的过滤器。例如,
"processor.outcome : *"。
-
分组依据 — 用于基于特定字段的值对数据进行分组的字段。例如,您可以按
url.domain字段进行分组,这将为所选字段的每个值创建单独的 SLO。
APM 延迟和 APM 可用性
编辑APM 延迟
编辑根据从已检测服务接收到的延迟数据和延迟阈值创建指标。
示例: 您可以为名为 banking-service 的 APM 服务定义一个指标,针对 production 环境,事务名称为 POST /deposit,延迟阈值为 300 毫秒。
APM 可用性
编辑根据已检测服务的可用性创建指标。可用性是通过计算成功事务 (event.outcome : "success") 占成功和失败事务总数的百分比来确定的 - 不包括未知结果。
示例: 您可以为名为 search-service 的 APM 服务定义一个指标,针对 production 环境,事务名称为 POST /search。
在定义 APM 延迟或 APM 可用性 SLI 时,请设置以下字段
- 服务名称 — APM 服务名称。
-
服务环境 —
all或特定环境。 -
事务类型 —
all或特定事务类型。 -
事务名称 —
all或特定事务名称。 - 阈值(仅限 APM 延迟) — 将请求视为良好的延迟阈值(以毫秒为单位)。
- 查询过滤器 — APM 数据上的可选查询过滤器。
Synthetics 可用性
编辑根据您的 synthetic 监视器的可用性创建指标。可用性是通过计算成功检查 (monitor.status : "up") 占检查总数的百分比来确定的。
示例:您可以定义一个指标,该指标基于 HTTP 监视器至少 99% 的时间处于“启动”状态。
在定义 Synthetics 可用性 SLI 时,请设置以下字段
- 监视器名称 — 一个或多个 synthetic 监视器的名称。
- 项目 — 包含 synthetic 监视器的一个或多个 项目的 ID。
- 标签 — 分配给 synthetic 监视器的一个或多个 标签。
- 查询过滤器 — 一个可选的 KQL 查询,用于根据某些相关条件筛选 Synthetics 检查。
Synthetics 可用性 SLI 会自动按监视器和位置分组。
设置您的目标
编辑在定义 SLI 后,您需要设置您的目标。要设置您的目标,请完成以下操作
选择您的预算方法
编辑您可以选择 发生次数 或 时间片 预算方法
发生次数 |
使用良好事件的数量和总事件的数量来计算 SLO。 示例: 您有一个 30 天滚动 SLO,目标为 95%,并且在过去 30 天内,总共有 1,355,700 个事件。错误预算为 如果同一时期内您有 1,300,000 个良好事件,则观察到的值为 |
时间片 |
将整个时间窗口划分为较小的、定义时长的片段,并使用良好片段的数量除以片段总数来计算 SLO。 时间片目标 (%) - 单个时间片的目标,用于确定片段是好还是坏。时间片窗口(分钟) - 时间片窗口的大小。 示例: 一个定义为五分钟片段的 30 天滚动 SLO 共有 |
设置您的时间窗口
编辑选择您要计算 SLO 的持续时间。时间窗口使用定义的滚动周期的数据。例如,最近 30 天。
设置您的目标/SLO (%)
编辑SLO 目标百分比。
描述您的 SLO
编辑设置目标后,请给您的 SLO 一个名称、一个简短的描述,并添加任何相关的标签。
创建 SLO 燃耗率警报规则
编辑当您使用 UI 创建 SLO 时,会自动创建一个默认的 SLO 燃耗率警报规则。燃耗率规则将使用默认配置,并且没有连接器。如果要接收 SLO 违规的警报,则必须配置一个连接器。
有关配置规则的更多信息,请参阅 创建 SLO 燃耗率规则。
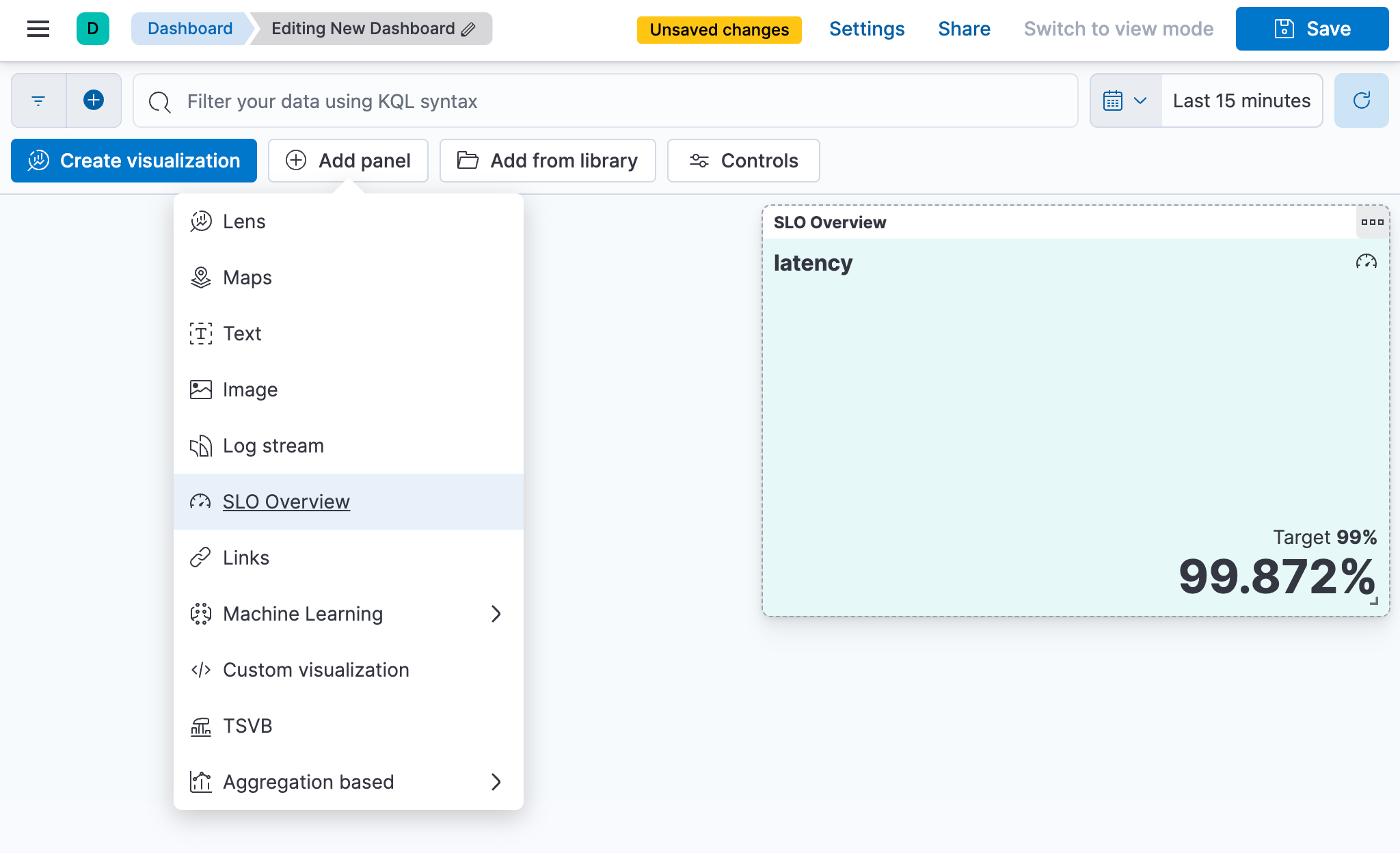
将 SLO 概览面板添加到自定义仪表板
编辑创建 SLO 后,您可以在 Observability 中的SLO页面中对其进行监控,但也可以将SLO 概览面板添加到自定义仪表板。有关仪表板的更多信息,请参阅 仪表板和可视化。
On this page