- 可观测性其他版本
- 开始
- 应用程序和服务
- CI/CD
- 云
- 基础设施和主机
- 日志
- 故障排除
- 事件管理
- 数据集质量
- 可观测性 AI 助手
- 参考
教程:监控 Java 应用程序
编辑教程:监控 Java 应用程序
编辑在本指南中,您将学习如何使用 Elastic 可观察性来监控 Java 应用程序:日志、基础设施指标、APM 和正常运行时间。
您将学到什么
编辑您将学习如何
- 创建示例 Java 应用程序。
- 使用 Filebeat 采集日志并在 Kibana 中查看日志。
- 使用 Metricbeat Prometheus 模块采集指标并在 Kibana 中查看指标。
- 使用 Elastic APM Java 代理检测您的应用程序。
- 使用 Heartbeat 监控您的服务并在 Kibana 中查看您的正常运行时间数据。
开始之前
编辑使用我们在 Elastic Cloud 上的托管 Elasticsearch 服务创建部署。该部署包括一个用于存储和搜索数据的 Elasticsearch 集群、用于可视化和管理数据的 Kibana 以及一个 APM 服务器。如果您不想按照此处列出的所有步骤操作并查看最终的 java 代码,请查看 observability-contrib GitHub 存储库中的示例应用程序。
步骤 1:创建 Java 应用程序
编辑要创建 Java 应用程序,您需要 OpenJDK 14(或更高版本)和 Javalin Web 框架。该应用程序将包括主端点、一个人为长时间运行的端点以及一个需要轮询另一个数据源的端点。还将运行一个后台作业。
-
设置一个 Gradle 项目并创建以下
build.gradle文件。plugins { id 'java' id 'application' } repositories { jcenter() } dependencies { implementation 'io.javalin:javalin:3.10.1' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2' } application { mainClassName = 'de.spinscale.javalin.App' } test { useJUnitPlatform() }
-
运行以下命令。
echo "rootProject.name = 'javalin-app'" >> settings.gradle mkdir -p src/main/java/de/spinscale/javalin mkdir -p src/test/java/de/spinscale/javalin
- 安装 Gradle 包装器。安装 Gradle 的一种简单方法是使用 sdkman 并运行
sdk install gradle 6.5.1。接下来,在当前目录中运行gradle wrapper以安装 Gradle 包装器。 - 运行
./gradlew clean check。您应该看到一个成功的构建,但尚未构建或编译任何内容。 -
要创建 Javalin 服务器及其第一个端点(主端点),请创建
src/main/java/de/spinscale/javalin/App.java文件。package de.spinscale.javalin; import io.javalin.Javalin; public class App { public static void main(String[] args) { Javalin app = Javalin.create().start(7000); app.get("/", ctx -> ctx.result("Appsolutely perfect")); } }
-
运行
./gradlew assemble此命令在
build目录中编译了App.class文件。但是,没有办法启动服务器。让我们创建一个包含我们编译的类以及所有必需依赖项的 jar。 -
在
build.gradle文件中,编辑plugins,如下所示。plugins { id 'com.github.johnrengelman.shadow' version '6.0.0' id 'application' id 'java' }
-
运行
./gradlew shadowJar。此命令创建一个build/libs/javalin-app-all.jar文件。shadowJar插件需要有关其主类的信息。 -
将以下代码段添加到
build.gradle文件。jar { manifest { attributes 'Main-Class': 'de.spinscale.javalin.App' } }
-
重新构建项目并启动服务器。
java -jar build/libs/javalin-app-all.jar
打开另一个终端并运行
curl localhost:7000以显示 HTTP 响应。 -
测试代码。将所有内容放入
main()方法中会使测试代码变得困难。但是,一个专用的处理程序可以解决这个问题。重构
App类。package de.spinscale.javalin; import io.javalin.Javalin; import io.javalin.http.Handler; public class App { public static void main(String[] args) { Javalin app = Javalin.create().start(7000); app.get("/", mainHandler()); } static Handler mainHandler() { return ctx -> ctx.result("Appsolutely perfect"); } }
将 Mockito 和 Assertj 依赖项添加到
build.gradle文件中。dependencies { implementation 'io.javalin:javalin:3.10.1' testImplementation 'org.mockito:mockito-core:3.5.10' testImplementation 'org.assertj:assertj-core:3.17.2' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2' }
在
src/test/java/de/spinscale/javalin中创建一个AppTests.java类文件。package de.spinscale.javalin; import io.javalin.http.Context; import org.junit.jupiter.api.Test; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.IOException; import java.nio.charset.StandardCharsets; import java.util.HashMap; import static de.spinscale.javalin.App.mainHandler; import static org.assertj.core.api.Assertions.assertThat; import static org.mockito.Mockito.mock; public class AppTests { final HttpServletRequest req = mock(HttpServletRequest.class); final HttpServletResponse res = mock(HttpServletResponse.class); final Context ctx = new Context(req, res, new HashMap<>()); @Test public void testMainHandler() throws Exception { mainHandler().handle(ctx); String response = resultStreamToString(ctx); assertThat(response).isEqualTo("Appsolutely perfect"); } private String resultStreamToString(Context ctx) throws IOException { final byte[] bytes = ctx.resultStream().readAllBytes(); return new String(bytes, StandardCharsets.UTF_8); } }
-
测试通过后,构建并打包应用程序。
./gradlew clean check shadowJar
步骤 2:采集日志
编辑日志可以是诸如结帐、异常或 HTTP 请求之类的事件。对于本教程,让我们使用 log4j2 作为我们的日志记录实现。
添加日志记录实现
编辑-
将依赖项添加到
build.gradle文件中。dependencies { implementation 'io.javalin:javalin:3.10.1' implementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.13.3' ... }
-
要开始记录日志,请编辑
App.java文件并更改处理程序。记录器调用必须在 lambda 中。否则,日志消息仅在启动期间记录。
package de.spinscale.javalin; import io.javalin.Javalin; import io.javalin.http.Handler; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class App { private static final Logger logger = LoggerFactory.getLogger(App.class); public static void main(String[] args) { Javalin app = Javalin.create(); app.get("/", mainHandler()); app.start(7000); } static Handler mainHandler() { return ctx -> { logger.info("This is an informative logging message, user agent [{}]", ctx.userAgent()); ctx.result("Appsolutely perfect"); }; } }
-
在
src/main/resources/log4j2.xml文件中创建 log4j2 配置。您可能需要先创建该目录。<?xml version="1.0" encoding="UTF-8"?> <Configuration> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%-5level] %logger{36} %msg%n"/> </Console> </Appenders> <Loggers> <Logger name="de.spinscale.javalin.App" level="INFO"/> <Root level="ERROR"> <AppenderRef ref="Console" /> </Root> </Loggers> </Configuration>
默认情况下,此日志记录在
ERROR级别。对于App类,还有一个额外的配置,以便也记录所有INFO日志。重新打包并重新启动后,日志消息会显示在终端中。17:17:40.019 [INFO ] de.spinscale.javalin.App - This is an informative logging message, user agent [curl/7.64.1]
记录请求
编辑根据应用程序流量以及它是否发生在应用程序外部,在应用程序级别记录每个请求是有意义的。
-
在
App.java文件中,编辑App类。public class App { private static final Logger logger = LoggerFactory.getLogger(App.class); public static void main(String[] args) { Javalin app = Javalin.create(config -> { config.requestLogger((ctx, executionTimeMs) -> { logger.info("{} {} {} {} \"{}\" {}", ctx.method(), ctx.url(), ctx.req.getRemoteHost(), ctx.res.getStatus(), ctx.userAgent(), executionTimeMs.longValue()); }); }); app.get("/", mainHandler()); app.start(7000); } static Handler mainHandler() { return ctx -> { logger.info("This is an informative logging message, user agent [{}]", ctx.userAgent()); ctx.result("Appsolutely perfect"); }; } }
-
重新构建并重新启动应用程序。将为每个请求记录日志消息。
10:43:50.066 [INFO ] de.spinscale.javalin.App - GET / 200 0:0:0:0:0:0:0:1 "curl/7.64.1" 7
创建 ISO8601 时间戳
编辑在将日志采集到 Elasticsearch 服务之前,通过编辑 log4j2.xml 文件来创建 ISO8601 时间戳。
创建 ISO8601 时间戳消除了在采集日志时对时间戳进行任何计算的需要,因为这是时间上的唯一点,包括时区。一旦您跨数据中心运行并尝试跟踪数据流,拥有时区就变得更加重要。
<PatternLayout pattern="%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n"/>
采集的日志条目包含如下时间戳。
2020-07-03T14:25:40,378+02:00 [INFO ] de.spinscale.javalin.App GET / 200 0:0:0:0:0:0:0:1 "curl/7.64.1" 0
记录到文件和标准输出
编辑-
要读取日志输出,让我们将数据写入文件和标准输出。这是一个新的
log4j2.xml文件。<?xml version="1.0" encoding="UTF-8"?> <Configuration> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%highlight{%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n}"/> </Console> <File name="JavalinAppLog" fileName="/tmp/javalin/app.log"> <PatternLayout pattern="%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n"/> </File> </Appenders> <Loggers> <Logger name="de.spinscale.javalin.App" level="INFO"/> <Root level="ERROR"> <AppenderRef ref="Console" /> <AppenderRef ref="JavalinAppLog" /> </Root> </Loggers> </Configuration>
- 重新启动应用程序并发送请求。日志将发送到
/tmp/javalin/app.log。
安装和配置 Filebeat
编辑要读取日志文件并将其发送到 Elasticsearch,需要 Filebeat。要下载并安装 Filebeat,请使用适用于您系统的命令
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.17.0-amd64.deb sudo dpkg -i filebeat-8.17.0-amd64.deb
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.17.0-x86_64.rpm sudo rpm -vi filebeat-8.17.0-x86_64.rpm
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.17.0-darwin-x86_64.tar.gz tar xzvf filebeat-8.17.0-darwin-x86_64.tar.gz
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.17.0-linux-x86_64.tar.gz tar xzvf filebeat-8.17.0-linux-x86_64.tar.gz
- 从 下载页面下载 Filebeat Windows zip 文件。
- 将 zip 文件的内容解压缩到
C:\Program Files。 - 将
filebeat-<version>-windows目录重命名为Filebeat。 - 以管理员身份打开 PowerShell 提示符(右键单击 PowerShell 图标并选择 以管理员身份运行)。
-
在 PowerShell 提示符下,运行以下命令以将 Filebeat 安装为 Windows 服务
PS > cd 'C:\Program Files\Filebeat' PS C:\Program Files\Filebeat> .\install-service-filebeat.ps1
如果您的系统上禁用了脚本执行,则需要为当前会话设置执行策略,以允许脚本运行。例如:PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-filebeat.ps1。
-
使用 Filebeat 密钥库存储 安全设置。让我们将云 ID 存储在密钥库中。
在以下命令中替换您部署的云 ID。要查找您的云 ID,请单击 https://cloud.elastic.co/deployments 中的部署。
./filebeat keystore create echo -n "<Your Cloud ID>" | ./filebeat keystore add CLOUD_ID --stdin
要以最小权限将日志存储在 Elasticsearch 中,请创建一个 API 密钥,以将数据从 Filebeat 发送到 Elasticsearch 服务。
-
登录 Kibana 用户(您可以通过 Cloud Console 执行此操作,而无需键入任何权限),然后选择 管理 → 开发工具。发送以下请求
POST /_security/api_key { "name": "filebeat_javalin-app", "role_descriptors": { "filebeat_writer": { "cluster": ["monitor", "read_ilm"], "index": [ { "names": ["filebeat-*"], "privileges": ["view_index_metadata", "create_doc"] } ] } } }
响应包含
api_key和id字段,可以按照以下格式存储在 Filebeat 密钥库中:id:api_key。echo -n "IhrJJHMB4JmIUAPLuM35:1GbfxhkMT8COBB4JWY3pvQ" | ./filebeat keystore add ES_API_KEY --stdin
确保指定
-n参数;否则,由于在 API 密钥末尾添加了换行符,您将遇到痛苦的调试会话。要查看是否已存储两个设置,请运行
./filebeat keystore list。 -
要加载 Filebeat 仪表板,请使用
elastic超级用户。./filebeat setup -e -E 'cloud.id=${CLOUD_ID}' -E 'cloud.auth=elastic:YOUR_SUPER_SECRET_PASS'
如果您不想将凭据存储在 shell 的
.history文件中,请在该行开头添加一个空格。根据 shell 配置,这些命令不会添加到历史记录中。 -
配置 Filebeat,使其知道从哪里读取数据以及将数据发送到哪里。创建
filebeat.yml文件。name: javalin-app-shipper filebeat.inputs: - type: log paths: - /tmp/javalin/*.log cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY}
将数据发送到 Elasticsearch
编辑要将数据发送到 Elasticsearch,请启动 Filebeat。
sudo service filebeat start
如果您使用 init.d 脚本启动 Filebeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前台启动 Filebeat。
另请参阅 Filebeat 和 systemd。
sudo service filebeat start
如果您使用 init.d 脚本启动 Filebeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前台启动 Filebeat。
另请参阅 Filebeat 和 systemd。
./filebeat -e
./filebeat -e
PS C:\Program Files\filebeat> Start-Service filebeat
默认情况下,Windows 日志文件存储在 C:\ProgramData\filebeat\Logs 中。
在日志输出中,您应该看到以下行。
2020-07-03T15:41:56.532+0200 INFO log/harvester.go:297 Harvester started for file: /tmp/javalin/app.log
让我们为应用程序创建一些日志条目。您可以使用诸如 wrk 之类的工具,并运行以下命令向应用程序发送请求。
wrk -t1 -c 100 -d10s https://127.0.0.1:7000
此命令导致每秒大约 8,000 个请求,并且还写入了等效数量的日志行。
步骤 3:在 Kibana 中查看日志
编辑-
登录 Kibana 并选择 Discover 应用程序。
顶部有一个文档摘要,但让我们看看单个文档。
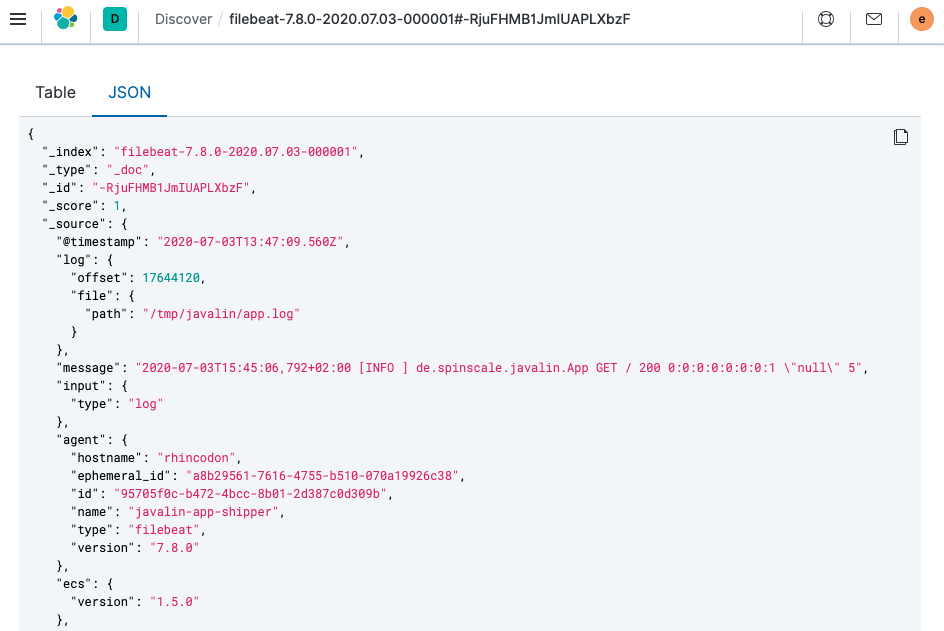
您可以看到索引的数据远不止事件。有关于文件中偏移量的信息、有关发送日志的组件的信息、输出中发送方名称的信息,以及包含日志行内容的
message字段。您可以看到请求日志记录中存在一个缺陷。如果用户代理是
null,则会返回除null之外的其他内容。读取我们的日志至关重要;但是,仅仅索引它们对我们没有任何帮助。为了解决这个问题,这里有一个新的请求记录器。Javalin app = Javalin.create(config -> { config.requestLogger((ctx, executionTimeMs) -> { String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-"; logger.info("{} {} {} {} \"{}\" {}", ctx.method(), ctx.req.getPathInfo(), ctx.res.getStatus(), ctx.req.getRemoteHost(), userAgent, executionTimeMs.longValue()); }); });
您可能还希望在主处理程序中的日志消息中修复此问题。
static Handler mainHandler() { return ctx -> { String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-"; logger.info("This is an informative logging message, user agent [{}]", userAgent); ctx.result("Appsolutely perfect"); }; }
-
现在让我们看一下 Kibana 中的 Logs 应用程序。选择 可观测性 → 日志。
如果您想查看流式传输功能的工作原理,请在休眠时循环运行以下 curl 请求。
while $(sleep 0.7) ; do curl localhost:7000 ; done
-
要查看日志消息的连续流,请单击 实时流。您还可以突出显示特定术语,如此处所示。
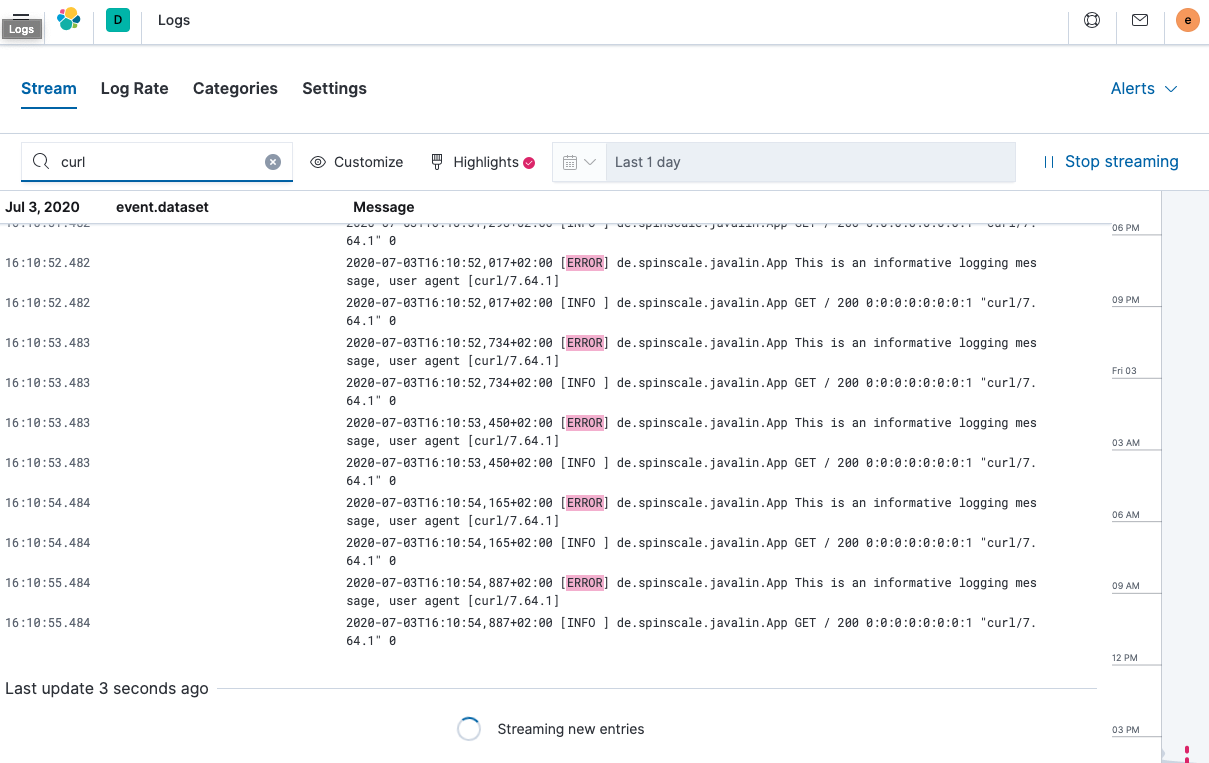
查看正在索引的文档之一,您可以看到日志消息包含在单个字段中。通过查看其中一个文档来验证这一点。
GET filebeat-*/_search { "size": 1 }
需要注意的事项
- 当您将
@timestamp字段与日志消息的时间戳进行比较时,您会注意到它们有所不同。这意味着当基于@timestamp字段进行过滤时,您不会获得预期的结果。当前的@timestamp字段反映的是事件在 Filebeat 中创建时的时间戳,而不是日志事件在应用程序中发生时的时间戳。 - 无法过滤特定字段,例如 HTTP 动词、HTTP 状态代码、日志级别或生成日志消息的类
- 当您将
步骤 4:处理您的日志
编辑结构化日志
编辑要从单个日志行中提取更多数据到多个字段,需要对日志进行额外的结构化。
让我们再次看一下我们的应用程序生成的日志消息。
2020-07-03T15:45:01,479+02:00 [INFO ] de.spinscale.javalin.App This is an informative logging message
此消息包含四个部分:时间戳、日志级别、类和 消息。拆分规则也很明显,因为它们中的大多数都涉及空格。
好消息是,所有 Beats 都可以在将日志行发送到 Elasticsearch 之前使用 处理器 来处理日志行。如果这些处理器的功能不够,您可以始终让 Elasticsearch 通过使用 摄取节点 来完成繁重的工作。这就是 Filebeat 中许多模块所做的事情。Filebeat 中的模块是一种解析特定软件的特定日志文件格式的方法。
让我们尝试使用几个处理器和仅 Filebeat 配置来实现此目的。
processors: - add_host_metadata: ~ - dissect: tokenizer: '%{timestamp} [%{log.level}] %{log.logger} %{message_content}' field: "message" target_prefix: "" - timestamp: field: "timestamp" layouts: - '2006-01-02T15:04:05.999Z0700' test: - '2020-07-18T04:59:51.123+0200' - drop_fields: fields: [ "message", "timestamp" ] - rename: fields: - from: "message_content" - to: "message"
dissect 处理器将日志消息拆分为四个部分。如果您希望 message 字段中包含原始消息的最后一部分,则需要先删除旧的 message 字段,然后重命名字段。使用 dissect 过滤器没有就地替换。
还有一个专用的时间戳解析,以便 @timestamp 字段包含解析值。删除重复的字段,但确保原始消息的一部分仍然在 message 字段中可用。
删除原始消息的部分内容是有争议的。保留原始消息对我来说很有意义。通过上面的示例,如果解析时间戳未按预期工作,则调试可能会出现问题。
时间戳的解析也略有不同,因为 go 时间解析器仅接受点作为秒和毫秒之间的分隔符。尽管如此,我们的 log4j2 的默认输出还是使用逗号。
可以修复日志输出中的时间戳,使其看起来像 Filebeat 预期的那样。这将产生以下模式布局。
<PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%-5level] %logger{36} %msg%n"/>
修复时间戳解析是另一种方法,因为您并不总是可以完全控制您的日志并更改其格式。想象一下使用某些第三方软件。现在,这已经足够好了。
更改后重新启动 Filebeat,并通过运行此搜索(并索引另一个日志消息)查看索引的 JSON 文档中发生了什么变化。
GET filebeat-*/_search?filter_path=**._source { "size": 1, "_source": { "excludes": [ "host.ip", "host.mac" ] }, "sort": [ { "@timestamp": { "order": "desc" } } ] }
这将返回如下文档。
{ "hits" : { "hits" : [ { "_source" : { "input" : { "type" : "log" }, "agent" : { "hostname" : "rhincodon", "name" : "javalin-app-shipper", "id" : "95705f0c-b472-4bcc-8b01-2d387c0d309b", "type" : "filebeat", "ephemeral_id" : "e4df883f-6073-4a90-a4c4-9e116704f871", "version" : "7.9.0" }, "@timestamp" : "2020-07-03T15:11:51.925Z", "ecs" : { "version" : "1.5.0" }, "log" : { "file" : { "path" : "/tmp/javalin/app.log" }, "offset" : 1440, "level" : "ERROR", "logger" : "de.spinscale.javalin.App" }, "host" : { "hostname" : "rhincodon", "os" : { "build" : "19F101", "kernel" : "19.5.0", "name" : "Mac OS X", "family" : "darwin", "version" : "10.15.5", "platform" : "darwin" }, "name" : "javalin-app-shipper", "id" : "C28736BF-0EB3-5A04-BE85-C27A62C99316", "architecture" : "x86_64" }, "message" : "This is an informative logging message, user agent [curl/7.64.1]" } } ] } }
您可以看到 message 字段仅包含我们日志消息的最后一部分。此外,还有一个 log.level 和 log.logger 字段。
当日志级别为 INFO 时,会在末尾记录额外的空格。您可以使用 脚本处理器 并调用 trim()。但是,修复我们的日志配置以使其始终不发出 5 个字符可能会更容易,而不管日志级别长度如何。您在写入标准输出时仍然可以保留此设置。
<File name="JavalinAppLog" fileName="/tmp/javalin/app.log"> <PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%level] %logger{36} %msg%n"/> </File>
解析异常
编辑在日志记录的情况下,异常是一种特殊处理。它们跨越多行,因此每行一条消息的旧规则在异常中不存在。
在 App.java 中添加一个首先触发异常的端点,并确保使用异常映射器记录该异常。
app.get("/exception", ctx -> { throw new IllegalArgumentException("not yet implemented"); }); app.exception(Exception.class, (e, ctx) -> { logger.error("Exception found", e); ctx.status(500).result(e.getMessage()); });
调用 /exception 会向客户端返回 HTTP 500 错误,但会在日志中留下如下所示的堆栈跟踪。
2020-07-06T11:27:29,491+02:00 [ERROR] de.spinscale.javalin.App Exception found java.lang.IllegalArgumentException: not yet implemented at de.spinscale.javalin.App.lambda$main$2(App.java:24) ~[classes/:?] at io.javalin.core.security.SecurityUtil.noopAccessManager(SecurityUtil.kt:23) ~[javalin-3.10.1.jar:?] at io.javalin.http.JavalinServlet$addHandler$protectedHandler$1.handle(JavalinServlet.kt:119) ~[javalin-3.10.1.jar:?] at io.javalin.http.JavalinServlet$service$2$1.invoke(JavalinServlet.kt:45) ~[javalin-3.10.1.jar:?] at io.javalin.http.JavalinServlet$service$2$1.invoke(JavalinServlet.kt:24) ~[javalin-3.10.1.jar:?] ... goes on and on and on and own ...
有一个属性有助于解析此堆栈跟踪。它与常规日志消息相比似乎有所不同。每个新行都以空格开头,因此与以日期开头的日志消息不同。让我们将此逻辑添加到我们的 Beats 配置中。
- type: log enabled: true paths: - /tmp/javalin/*.log multiline.pattern: ^20 multiline.negate: true multiline.match: after
因此,上述设置的逐字翻译是,将所有内容都视为现有消息的一部分,该消息不是以行中的 20 开头的。20 类似于时间戳的起始年份。一些用户喜欢将日期包装在 [] 中,以使其更容易理解。
这会将状态引入到您的日志记录中。您现在无法在多个处理器之间拆分日志文件,因为每个日志行仍然可能属于当前事件。这不是一件坏事,但同样需要注意。
重新启动 Filebeat 和 Javalin 应用程序后,触发异常,您将在日志的 message 字段中看到一个很长的堆栈跟踪。
配置日志轮换
编辑为确保日志不会无限增长,让我们向日志配置添加一些日志轮换。
<?xml version="1.0" encoding="UTF-8"?> <Configuration> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%highlight{%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n}"/> </Console> <RollingFile name="JavalinAppLogRolling" fileName="/tmp/javalin/app.log" filePattern="/tmp/javalin/%d{yyyy-MM-dd}-%i.log.gz"> <PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%level] %logger{36} %msg%n"/> <Policies> <TimeBasedTriggeringPolicy /> <SizeBasedTriggeringPolicy size="50 MB"/> </Policies> <DefaultRolloverStrategy max="20"/> </RollingFile> </Appenders> <Loggers> <Logger name="de.spinscale.javalin.App" level="INFO"/> <Root level="ERROR"> <AppenderRef ref="Console" /> <AppenderRef ref="JavalinAppLogRolling" /> </Root> </Loggers> </Configuration>
示例在我们的配置中添加了一个 JavalinAppLogRolling appender,它使用与之前相同的日志记录模式,但如果新的一天开始或日志文件达到 50 兆字节,则会滚动。
如果创建新的日志文件,则旧的日志文件也会进行 gzip 压缩,以减少磁盘上的空间。50 兆字节的大小是指未打包的文件大小,因此磁盘上潜在的 20 个文件每个都会小得多。
摄取节点
编辑内置模块几乎完全使用 Elasticsearch 的 摄取节点 功能,而不是 Beats 处理器。
摄取管道最有用的部分之一是能够使用 模拟管道 API 进行调试。
-
让我们使用 Kibana 中的 Dev Tools 面板编写一个类似于我们的 Filebeat 处理器的管道,运行以下命令
# Store the pipeline in Elasticsearch PUT _ingest/pipeline/javalin_pipeline { "processors": [ { "dissect": { "field": "message", "pattern": "%{@timestamp} [%{log.level}] %{log.logger} %{message}" } }, { "trim": { "field": "log.level" } }, { "date": { "field": "@timestamp", "formats": [ "ISO8601" ] } } ] } # Test the pipeline POST _ingest/pipeline/javalin_pipeline/_simulate { "docs": [ { "_source": { "message": "2020-07-06T13:39:51,737+02:00 [INFO ] de.spinscale.javalin.App This is an informative logging message" } } ] }
您可以在输出中看到管道创建的字段,现在看起来像早期的 Filebeat 处理器。由于摄取管道在文档级别工作,因此您仍然需要检查生成日志的异常,并让 Filebeat 从中创建一个消息。您甚至可以使用单个处理器来实现日志级别修剪,并且日期解析也很容易,因为 Elasticsearch ISO8601 解析器在拆分秒和毫秒时可以正确识别逗号而不是点。
-
现在,让我们来看一下 Filebeat 配置。首先,让我们删除除 add_host_metadata 处理器 之外的所有处理器,以添加一些主机信息,例如主机名和操作系统。
processors: - add_host_metadata: ~
-
编辑 Elasticsearch 输出,以确保从 Filebeat 索引文档时将引用该管道。
cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} pipeline: javalin_pipeline
- 重新启动 Filebeat 并查看日志是否按预期流动。
将日志写为 JSON
编辑您现在已经了解了如何在 Beats 或 Elasticsearch 中解析日志。如果我们不需要考虑解析日志并手动提取数据,该怎么办?
将日志写为纯文本可行,并且易于人类阅读。但是,首先将它们写为纯文本,使用 dissect 处理器解析它们,然后再创建一个 JSON,这听起来很繁琐并且会消耗不必要的 CPU 周期。
虽然 log4j2 有一个 JSONLayout,但您可以更进一步并使用名为 ecs-logging-java 的库。ECS 日志记录的优势在于它使用 Elastic Common Schema。ECS 定义了一组用于在 Elasticsearch 中存储事件数据(如日志和指标)的标准字段。
-
不要编写我们的日志记录标准,而是使用现有的标准。让我们将日志记录依赖项添加到我们的 Javalin 应用程序。
dependencies { implementation 'io.javalin:javalin:3.10.1' implementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.13.3' implementation 'co.elastic.logging:log4j2-ecs-layout:0.5.0' testImplementation 'org.mockito:mockito-core:3.5.10' testImplementation 'org.assertj:assertj-core:3.17.2' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2' } // this is needed to ensure JSON logging works as expected when building // a shadow jar shadowJar { transform(com.github.jengelman.gradle.plugins.shadow.transformers.Log4j2PluginsCacheFileTransformer) }
log4j2-ecs-layout附带一个自定义的<EcsLayout>,该自定义的<EcsLayout>可用于滚动文件 appender 的日志记录设置中<RollingFile name="JavalinAppLogRolling" fileName="/tmp/javalin/app.log" filePattern="/tmp/javalin/%d{yyyy-MM-dd}-%i.log.gz"> <EcsLayout serviceName="my-javalin-app"/> <Policies> <TimeBasedTriggeringPolicy /> <SizeBasedTriggeringPolicy size="50 MB"/> </Policies> <DefaultRolloverStrategy max="20"/> </RollingFile>
当您重新启动应用程序时,您将看到纯 JSON 写入您的日志文件。当您触发异常时,您将看到堆栈跟踪已在您的单个文档中。这意味着 Filebeat 配置可以变为无状态,甚至更轻量。此外,还可以再次删除 Elasticsearch 端的摄取管道。
-
您可以为
EcsLayout配置一些 更多参数,但默认值已明智地选择。让我们修复 Filebeat 配置,并删除多行设置以及管道filebeat.inputs: - type: log enabled: true paths: - /tmp/javalin/*.log json.keys_under_root: true name: javalin-app-shipper cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} # ================================= Processors ================================= processors: - add_host_metadata: ~
如您所见,仅仅通过将日志写为 JSON,我们的整个日志记录设置就变得容易得多,因此,只要有可能,请尝试直接将日志写为 JSON。
步骤 5:摄取指标
编辑指标被认为是随时可能变化的时间点值。当前请求的数量可能在任何毫秒内发生变化。您可能会出现 1000 个请求的峰值,然后一切恢复为一个请求。这也意味着这些类型的指标可能不准确,并且您还需要提取最小值/最大值以获得更多指示。此外,这意味着您还需要考虑这些指标的持续时间。您是否需要每分钟一次或每 10 秒一次?
为了获得应用程序的不同角度视图,让我们摄取一些指标。在此示例中,我们将使用 Metricbeat Prometheus 模块 将数据发送到 Elasticsearch。
我们应用程序中使用的底层库是 micrometer.io,这是一个与供应商无关的应用程序指标外观,结合其 Prometheus 支持 来实现基于拉取的模型。您可以使用 elastic 支持 来实现基于推送的模型。这将要求用户在我们的应用程序中存储 Elasticsearch 集群的凭据数据。此示例将此数据保留在周围的工具中。
将指标添加到应用程序
编辑-
将依赖项添加到我们的
build.gradle文件中。// metrics via micrometer implementation 'io.micrometer:micrometer-core:1.5.4' implementation 'io.micrometer:micrometer-registry-prometheus:1.5.4' implementation 'org.apache.commons:commons-lang3:3.11'
-
将 micrometer 插件及其对应的导入添加到我们的 Javalin 应用程序中。
... import io.javalin.plugin.metrics.MicrometerPlugin; import io.javalin.core.security.BasicAuthCredentials; ... Javalin app = Javalin.create(config -> { ... config.registerPlugin(new MicrometerPlugin()); );
-
添加一个新的指标端点,并确保也导入了
BasicAuthCredentials类。final Micrometer micrometer = new Micrometer(); app.get("/metrics", ctx -> { ctx.status(404); if (ctx.basicAuthCredentialsExist()) { final BasicAuthCredentials credentials = ctx.basicAuthCredentials(); if ("metrics".equals(credentials.getUsername()) && "secret".equals(credentials.getPassword())) { ctx.status(200).result(micrometer.scrape()); } } });
在这里,
MicroMeter类是一个自写的类,名为MicroMeter.java,它设置几个指标监视器并为 Prometheus 创建注册表,该注册表提供基于文本的 Prometheus 输出。package de.spinscale.javalin; import io.micrometer.core.instrument.Metrics; import io.micrometer.core.instrument.binder.jvm.JvmCompilationMetrics; import io.micrometer.core.instrument.binder.jvm.JvmGcMetrics; import io.micrometer.core.instrument.binder.jvm.JvmHeapPressureMetrics; import io.micrometer.core.instrument.binder.jvm.JvmMemoryMetrics; import io.micrometer.core.instrument.binder.jvm.JvmThreadMetrics; import io.micrometer.core.instrument.binder.logging.Log4j2Metrics; import io.micrometer.core.instrument.binder.system.FileDescriptorMetrics; import io.micrometer.core.instrument.binder.system.ProcessorMetrics; import io.micrometer.core.instrument.binder.system.UptimeMetrics; import io.micrometer.prometheus.PrometheusConfig; import io.micrometer.prometheus.PrometheusMeterRegistry; public class Micrometer { final PrometheusMeterRegistry registry = new PrometheusMeterRegistry(new PrometheusConfig() { @Override public String get(String key) { return null; } @Override public String prefix() { return "javalin"; } }); public Micrometer() { Metrics.addRegistry(registry); new JvmGcMetrics().bindTo(Metrics.globalRegistry); new JvmHeapPressureMetrics().bindTo(Metrics.globalRegistry); new JvmThreadMetrics().bindTo(Metrics.globalRegistry); new JvmCompilationMetrics().bindTo(Metrics.globalRegistry); new JvmMemoryMetrics().bindTo(Metrics.globalRegistry); new Log4j2Metrics().bindTo(Metrics.globalRegistry); new UptimeMetrics().bindTo(Metrics.globalRegistry); new FileDescriptorMetrics().bindTo(Metrics.globalRegistry); new ProcessorMetrics().bindTo(Metrics.globalRegistry); } public String scrape() { return registry.scrape(); } }
-
重新构建您的应用程序并轮询指标端点。
curl localhost:7000/metrics -u metrics:secret
这将返回一个基于行的响应,每行一个指标。这是标准的 Prometheus 格式。
安装和配置 Metricbeat
编辑要将指标发送到 Elasticsearch,需要 Metricbeat。要下载和安装 Metricbeat,请使用适用于您系统的命令
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.17.0-amd64.deb sudo dpkg -i metricbeat-8.17.0-amd64.deb
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.17.0-x86_64.rpm sudo rpm -vi metricbeat-8.17.0-x86_64.rpm
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.17.0-darwin-x86_64.tar.gz tar xzvf metricbeat-8.17.0-darwin-x86_64.tar.gz
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.17.0-linux-x86_64.tar.gz tar xzvf metricbeat-8.17.0-linux-x86_64.tar.gz
- 从 下载页面 下载 Metricbeat Windows zip 文件。
- 将 zip 文件的内容解压缩到
C:\Program Files。 - 将
metricbeat-<version>-windows目录重命名为Metricbeat。 - 以管理员身份打开 PowerShell 提示符(右键单击 PowerShell 图标并选择 以管理员身份运行)。
-
从 PowerShell 提示符下,运行以下命令以将 Metricbeat 安装为 Windows 服务
PS > cd 'C:\Program Files\Metricbeat' PS C:\Program Files\Metricbeat> .\install-service-metricbeat.ps1
如果您的系统上禁用了脚本执行,则需要为当前会话设置执行策略以允许脚本运行。例如:PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-metricbeat.ps1。
-
与 Filebeat 设置类似,使用管理员用户运行所有仪表板的初始设置,然后使用 API 密钥。
POST /_security/api_key { "name": "metricbeat_javalin-app", "role_descriptors": { "metricbeat_writer": { "cluster": ["monitor", "read_ilm"], "index": [ { "names": ["metricbeat-*"], "privileges": ["view_index_metadata", "create_doc"] } ] } } }
-
将
id和api_key字段的组合存储在密钥库中。./metricbeat keystore create echo -n "IhrJJHMB4JmIUAPLuM35:1GbfxhkMT8COBB4JWY3pvQ" | ./metricbeat keystore add ES_API_KEY --stdin echo -n "observability-javalin-app:ZXUtY2VudHJhbC0xLmF3cy5jbG91ZC5lcy5pbyQ4NDU5M2I1YmQzYTY0N2NhYjA2MWQ3NTJhZWFhNWEzYyQzYmQwMWE2OTQ2MmQ0N2ExYjdhYTkwMzI0YjJiOTMyYQ==" | ./metricbeat keystore add CLOUD_ID --stdin
不要忘记像这样进行初始设置。
./metricbeat setup -e -E 'cloud.id=${CLOUD_ID}' -E 'cloud.auth=elastic:YOUR_SUPER_SECRET_PASS'
-
配置 Metricbeat 以读取我们的 Prometheus 指标。从基本的
metricbeat.yaml开始。metricbeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false name: javalin-metrics-shipper cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} processors: - add_host_metadata: ~ - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~
由于 Metricbeat 支持数十个模块,而这些模块又是不同的指标摄取方式(Filebeat 对于不同类型的日志文件和格式也是如此),因此需要启用 Prometheus 模块。
./metricbeat modules enable prometheus
将要轮询的 Prometheus 端点添加到
./modules.d/prometheus.yml中- module: prometheus period: 10s hosts: ["localhost:7000"] metrics_path: /metrics username: "metrics" password: "secret" use_types: true rate_counters: true
- 为了提高安全性,您应该将用户名和密码添加到密钥库,并在配置中引用两者。
- 启动 Metricbeat。
sudo service metricbeat start
如果使用 init.d 脚本启动 Metricbeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前台启动 Metricbeat。
另请参阅 Metricbeat 和 systemd。
sudo service metricbeat start
如果使用 init.d 脚本启动 Metricbeat,则无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前台启动 Metricbeat。
另请参阅 Metricbeat 和 systemd。
|
您将以 root 用户身份运行 Metricbeat,因此您需要更改配置文件的所有权,或者使用指定的 |
|
您将以 root 用户身份运行 Metricbeat,因此您需要更改配置文件的所有权,或者使用指定的 |
PS C:\Program Files\metricbeat> Start-Service metricbeat
默认情况下,Windows 日志文件存储在 C:\ProgramData\metricbeat\Logs 中。
在 Windows 上,当前未捕获有关系统负载和交换使用情况的统计信息
验证 Prometheus 事件是否正在流入 Elasticsearch。
GET metricbeat-*/_search?filter_path=**.prometheus,hits.total { "query": { "term": { "event.module": "prometheus" } } }
步骤 6:在 Kibana 中查看指标
编辑由于这是来自我们 Javalin 应用程序的自定义数据,因此没有用于显示此数据的预定义仪表板。
让我们检查每个日志级别的日志消息数量。
GET metricbeat-*/_search { "query": { "exists": { "field": "prometheus.log4j2_events_total.counter" } } }
可视化随时间推移的日志消息数量,按日志级别分隔。自从 Elastic Stack 7.7 以来,出现了一种称为 Lens 的新可视化创建方式。
- 登录到 Kibana 并选择 可视化 → 创建可视化。
-
创建一个折线图,并选择
metricbeat-*作为源。基本思想是在 y 轴上对
prometheus.log4j2_events_total.rate字段进行 最大聚合,而 x 轴则使用对@timestamp字段的 date_histogram 聚合按日期分隔。在每个日期直方图桶内还有一个分割,通过使用对
prometheus.labels.level的 术语聚合 按日志级别分割,其中包含日志级别。此外,将日志级别的大小增加到六,以显示每个日志级别。最终结果如下所示。
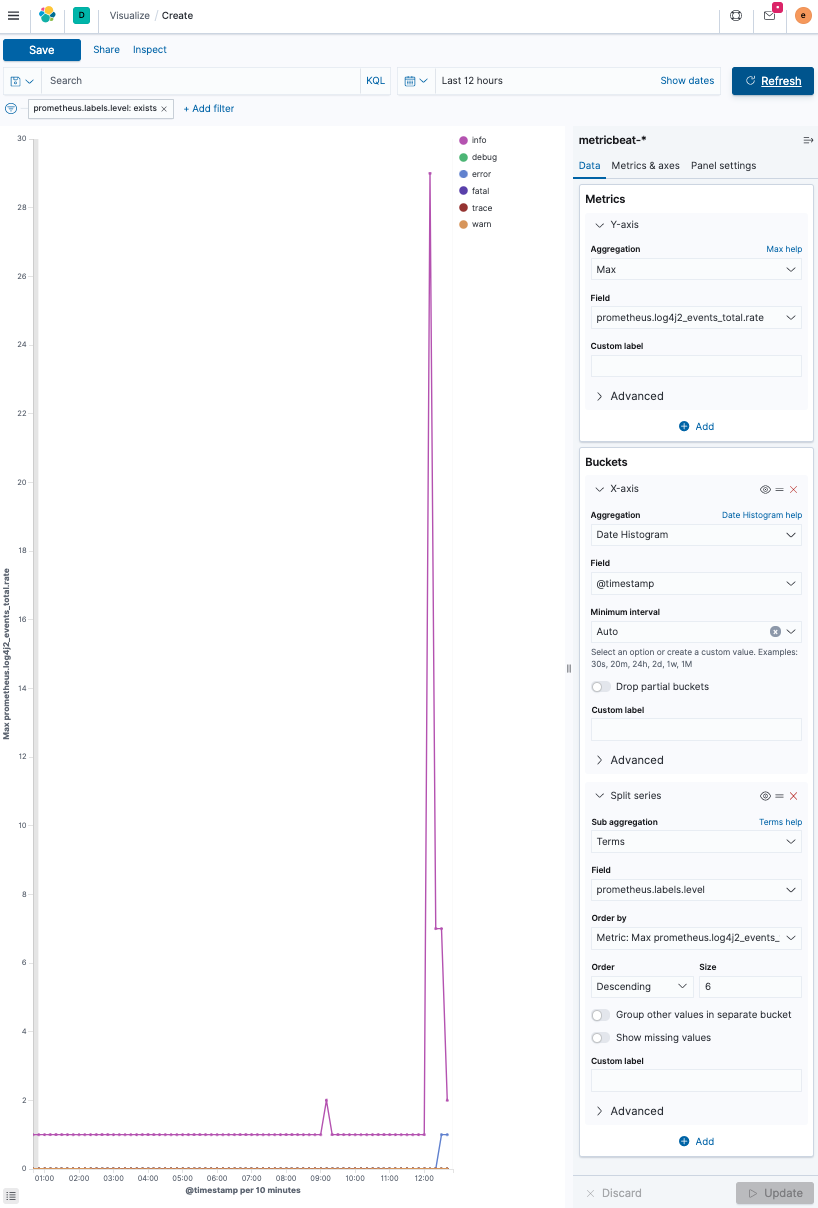
可视化随时间推移的打开文件
编辑第二个可视化是检查我们应用程序中打开的文件数量。
由于没有人能记住所有字段名称,让我们再次首先查看指标输出。
curl -s localhost:7000/metrics -u metrics:secret | grep ^process process_files_max_files 10240.0 process_cpu_usage 1.8120711232436825E-4 process_uptime_seconds 72903.726 process_start_time_seconds 1.594048883317E9 process_files_open_files 61.0
让我们看一下 process_files_open_files 指标。这应该是一个相当静态的值,很少更改。如果您运行一个在 JVM 中存储数据或打开和关闭网络套接字的应用程序,则此指标会根据负载而增加和减少。对于 Web 应用程序,这相当静态。让我们弄清楚为什么我们的小型 Web 应用程序上会打开 60 个文件。
-
运行
jps,它将在进程列表中包含您的应用程序。$ jps 14224 Jps 82437 Launcher 82438 App 40895
-
在该进程上使用
lsof。$ lsof -p 82438
您将看到比仅打开的所有文件更多的输出,因为文件也是现在发生的 TCP 连接。
-
添加一个端点,通过具有长时间运行的 HTTP 连接来增加打开的文件数(每个连接也被视为一个打开的文件,因为它需要一个文件描述符),然后针对它运行
wrk。... import java.util.concurrent.CompletableFuture; import java.util.concurrent.Executor; import java.util.concurrent.TimeUnit; ... public static void main(String[] args) { ... final Executor executor = CompletableFuture.delayedExecutor(20, TimeUnit.SECONDS); app.get("/wait", ctx -> { CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "done", executor); ctx.result(future); }); ...
每个 future 都会延迟 20 秒,这意味着单个 HTTP 请求将保持打开 20 秒。
-
让我们运行一个
wrk工作负载。wrk -c 100 -t 20 -d 5m https://127.0.0.1:7000/wait
结果表明仅发送了 20 个请求,考虑到处理时间,这是有道理的。
现在,让我们使用 Kibana 中的 Lens 构建可视化。
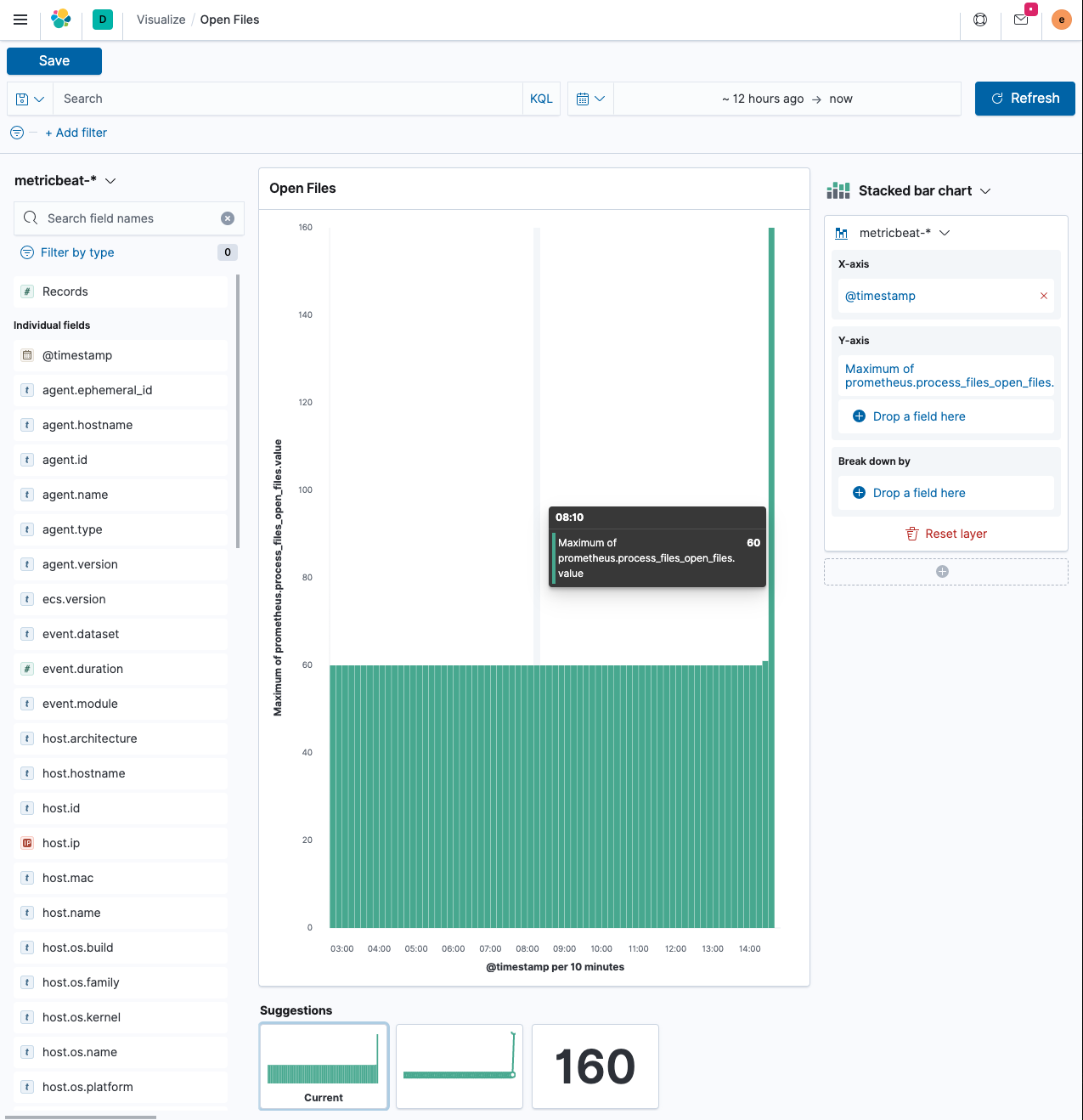
-
在
添加过滤器下,选择metricbeat-*索引模式。这很可能会使用filebeat-*作为默认值。x 轴使用
@timestamp字段 - 这反过来将再次创建一个date_histogram聚合。y 轴不应是文档计数,因为文档计数将始终是稳定的,而是存储桶中文档的最大值。单击 y 轴上字段名称的右侧,然后选择最大。这将为您提供与所示类似的视觉效果,其中有一个峰值,您在上面运行了wrk命令。 -
现在,让我们看一下 Kibana 中的 Infrastructure 应用程序。选择 可观察性 → 基础架构。
您只会看到来自单个托运人的数据。尽管如此,当您运行多个服务并且能够按 Kubernetes pod 或主机对此进行分组时,您就可以发现 CPU 或内存消耗较高的主机。
-
单击 指标资源管理器,您可以开始探索特定主机的数据或节点之间的 CPU 使用率。
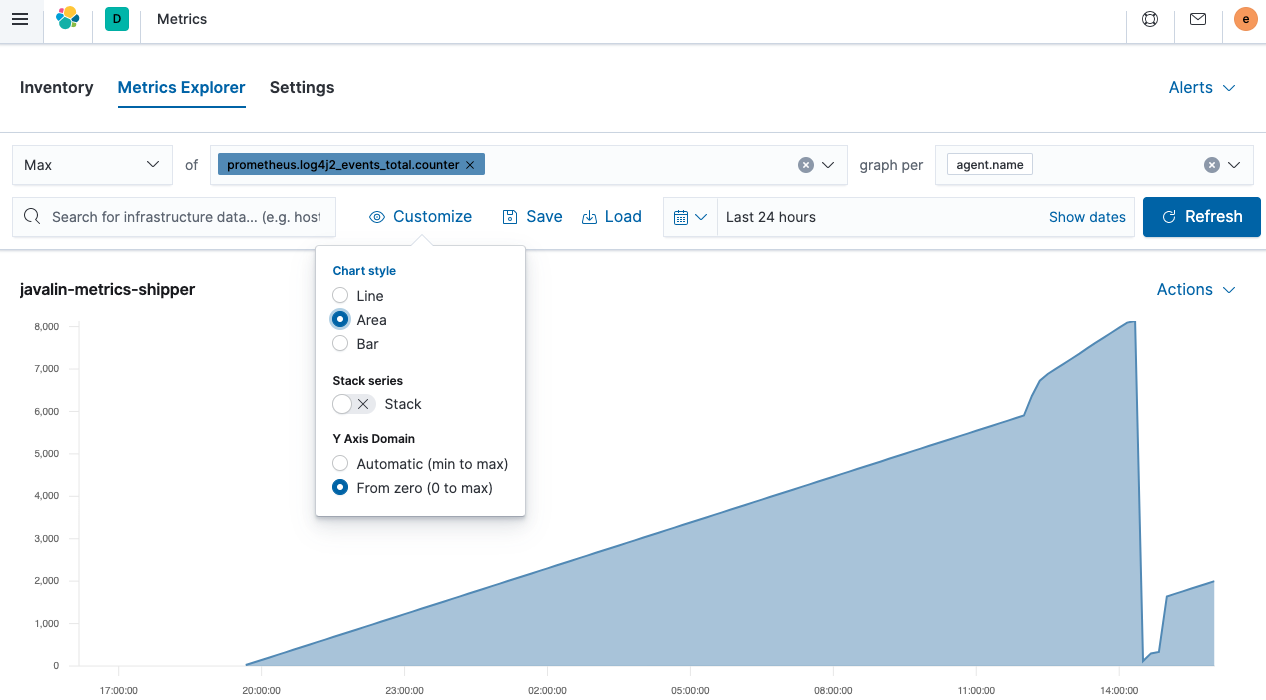
这是 Javalin 应用程序发出的总事件计数器的面积图。它正在上升,因为有一个组件正在轮询一个端点,而该端点又会生成另一条日志消息。陡峭的峰值是由于发送了更多请求。但是突然的下降来自哪里?JVM 重启。由于这些指标未持久化,因此它们会在 JVM 重启时重置。考虑到这一点,通常最好记录
rate而不是counter字段。
步骤 7:检测应用程序
编辑可观察性的第三部分是应用程序性能管理 (APM)。APM 设置由一个接受数据的 APM 服务器(已经在我们的 Elastic Cloud 设置中运行)和一个将数据传递到服务器的代理组成。
代理有两个任务:检测 Java 应用程序以提取应用程序性能信息,并将该数据发送到 APM 服务器。
APM 的核心思想之一是能够跟踪用户会话在整个堆栈中的流程,无论您是拥有数十个微服务还是一个响应用户请求的整体。这意味着能够标记整个堆栈中的请求。
要完全捕获用户活动,您需要从用户浏览器中使用真实用户监控 (RUM) 开始,直到您的应用程序,该应用程序会向您的数据库发送 SQL 查询。
数据模型
编辑尽管 APM 格局高度分散,但术语通常是相似的。两个最重要的术语是 跨度 和 事务。
事务封装了一系列跨度,其中包含有关一段代码执行的信息。让我们看一下 Kibana 应用程序 UI 中的此屏幕截图。
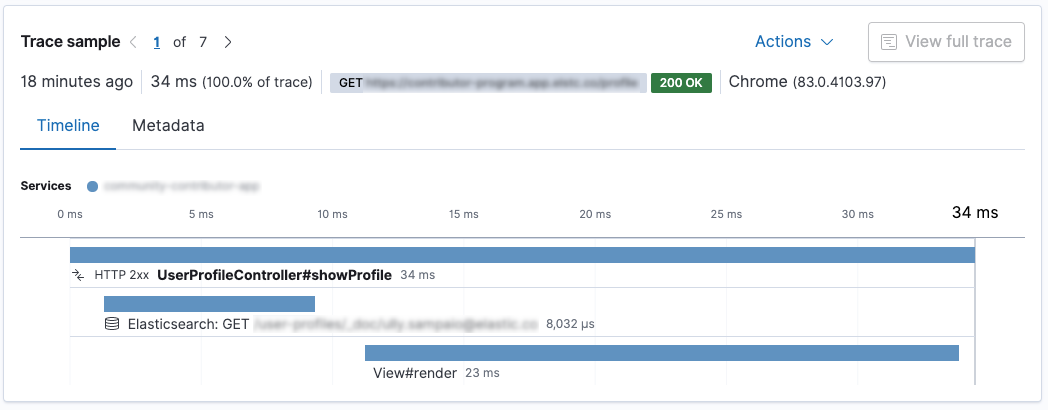
这是一个 Spring Boot 应用程序。调用了 UserProfileController.showProfile() 方法,该方法被标记为事务。其中有两个跨度。首先,使用 Elasticsearch REST 客户端向 Elasticsearch 发送请求,然后在使用 Thymeleaf 渲染响应。在这种情况下,对 Elasticsearch 的请求比渲染速度更快。
Java APM 代理可以自动检测特定的框架。Spring 和 Spring Boot 得到了很好的支持,并且上面的数据是通过将代理添加到 Spring Boot 应用程序来创建的;无需进行任何配置。
目前有 Go、.NET、Node、Python、Ruby 和浏览器 (RUM) 的代理。代理会不断添加,因此您可能需要查看 APM 代理文档。
将 APM 代理添加到您的代码中
编辑您有两种方法可以将 Java 代理检测添加到您的应用程序中。
首先,您可以在调用 java 二进制文件时通过参数添加代理。这样,它就不会干扰应用程序的打包。此机制在启动时检测应用程序。
首先,下载代理,您可以查找最新版本。
wget https://repo1.maven.org/maven2/co/elastic/apm/elastic-apm-agent/1.17.0/elastic-apm-agent-1.17.0.jar
在启动时指定代理以及将 APM 数据发送到的位置的配置参数。在启动 Java 应用程序之前,让我们为在 Elastic Cloud 中运行的 APM 服务器获取一个 API 密钥。
当您在 Elastic Cloud 中检查您的部署并单击左侧的 APM 时,您将看到 APM 服务器密钥令牌,您可以使用该令牌。您还可以从那里复制 APM 端点 URL。
java -javaagent:/path/to/elastic-apm-agent-1.17.0.jar\ -Delastic.apm.service_name=javalin-app \ -Delastic.apm.application_packages=de.spinscale.javalin \ -Delastic.apm.server_urls=$APM_ENDPOINT_URL \ -Delastic.apm.secret_token=PqWTHGtHZS2i0ZuBol \ -jar build/libs/javalin-app-all.jar
现在您可以继续打开应用程序 UI,您应该会看到数据正在流入。
自动附加
编辑如果您不想更改应用程序的启动选项,独立代理允许您附加到主机上运行的 JVM。
这需要您下载独立的 jar 文件。您可以在 官方文档上找到该链接。
要列出您本地运行的 Java 应用程序,您可以运行
java -jar /path/to/apm-agent-attach-1.17.0-standalone.jar --list
由于我通常在我的系统上运行多个 Java 应用程序,因此我指定要附加到的应用程序。另外,请确保您已停止已附加代理的 Javalin 应用程序,并且仅启动一个未配置附加代理的常规 Javalin 应用程序。
java -jar /tmp/apm-agent-attach-1.17.0-standalone.jar --pid 30730 \ --config service_name=javalin-app \ --config application_packages=de.spinscale.javalin \ --config server_urls=$APM_ENDPOINT_URL \ --config secret_token=PqWTHGtHZS2i0ZuBol
上面的消息将返回类似以下内容
2020-07-10 15:04:48.144 INFO Attaching the Elastic {apm-agent} to 30730 2020-07-10 15:04:49.649 INFO Done
现在,代理已附加到具有特殊配置的正在运行的应用程序。
虽然前两种可能性都有效,但您也可以使用第三种:将 APM 代理用作直接依赖项。这允许我们在应用程序中编写自定义跨度和事务。
程序化设置
编辑通过程序化设置,您可以通过源代码中的一行 Java 代码附加代理。
-
添加 Java 代理依赖项。
dependencies { ... implementation 'co.elastic.apm:apm-agent-attach:1.17.0' ... }
-
在我们的
main()方法中启动时检测应用程序。import co.elastic.apm.attach.ElasticApmAttacher; ... public static void main(String[] args) { ElasticApmAttacher.attach(); ... }
我们尚未配置任何端点或 API 令牌。虽然文档建议使用
src/main/resources/elasticapm.properties文件,但我更喜欢使用环境变量,因为这可以防止将 API 令牌提交到您的源代码或合并另一个存储库。诸如 Vault 之类的机制允许您以这种方式管理您的密钥。对于我们的本地部署,我通常使用像 direnv 这样的工具进行本地设置。
direnv是您本地 shell 的一个扩展,当您进入目录(如您的应用程序)时,它会加载/卸载环境变量。direnv可以做更多的事情,例如加载正确的 node/ruby 版本或将目录添加到您的 $PATH 变量。 -
要启用
direnv,您需要创建一个包含以下内容的.envrc文件。dotenv这告诉
direnv将.env文件的内容加载为环境变量。.env文件应如下所示ELASTIC_APM_SERVICE_NAME=javalin-app ELASTIC_APM_SERVER_URLS=https://APM_ENDPOINT_URL ELASTIC_APM_SECRET_TOKEN=PqWTHGtHZS2i0ZuBol
如果您不习惯将敏感数据放入
.env文件中,则可以使用诸如 envchain 之类的工具,或者在.envrc文件中调用任意命令(例如访问 Vault)。 -
您现在可以像之前一样运行 Java 应用程序。
java -jar build/libs/javalin-app-all.jar
如果您想在 IDE 中运行它,您可以手动设置环境变量,或搜索支持
.env文件的插件。等待几分钟,让我们最后看一下应用程序 UI。
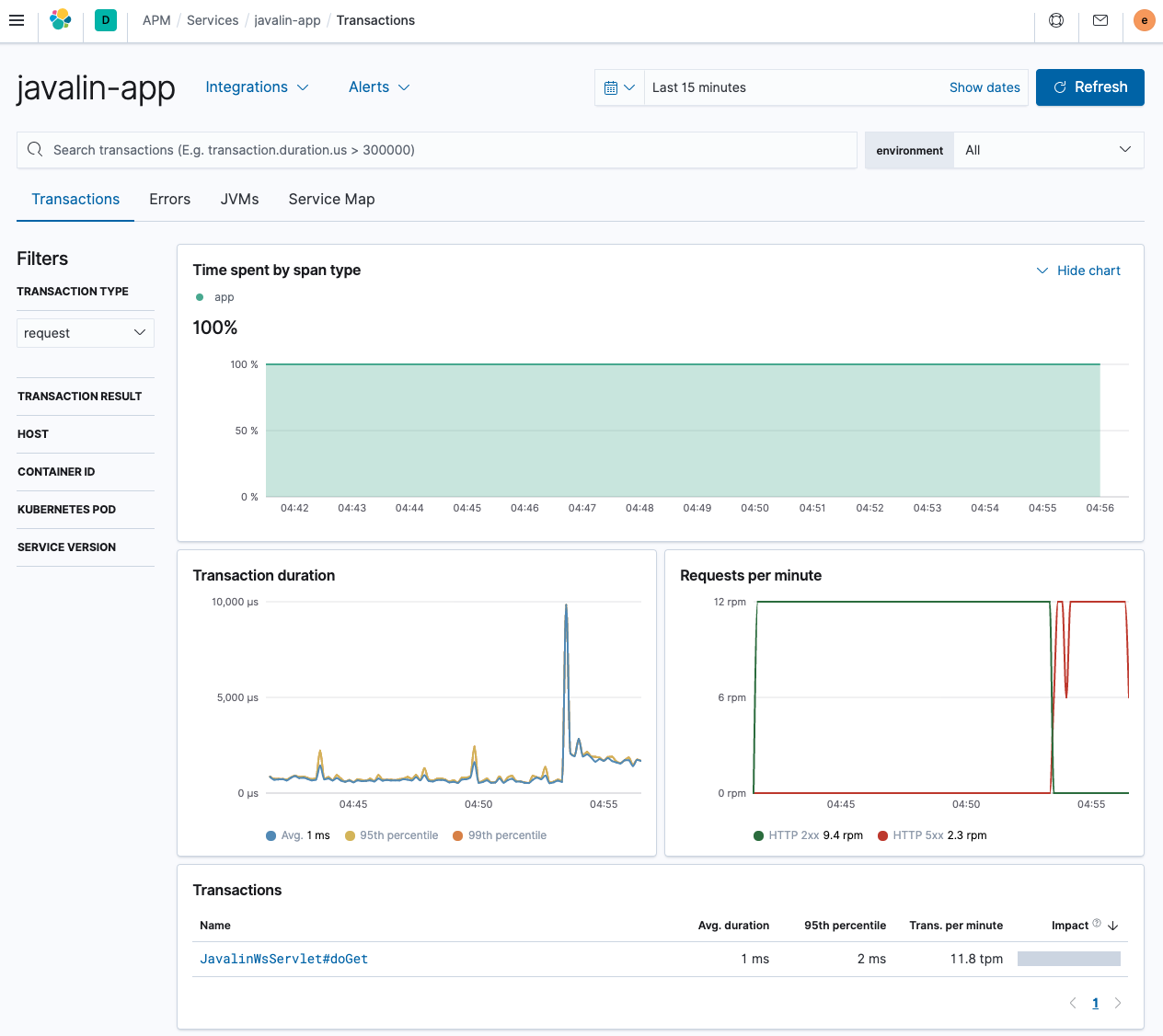
如您所见,这与之前显示的 Spring Boot 应用程序有很大不同。未列出不同的端点;我们可以看到每分钟的请求数,包括错误。
唯一的事务来自单个 servlet,这没什么帮助。让我们尝试通过引入自定义程序化事务来修复此问题。
自定义事务
编辑-
添加另一个依赖项。
dependencies { ... implementation 'co.elastic.apm:apm-agent-attach:1.17.0' implementation 'co.elastic.apm:apm-agent-api:1.17.0' ... }
-
修复事务的名称以包含 HTTP 方法和请求路径
app.before(ctx -> ElasticApm.currentTransaction() .setName(ctx.method() + " " + ctx.path()));
-
重新启动您的应用程序,并查看数据流入。测试几个不同的端点,尤其是抛出异常的端点和触发 404 的端点。
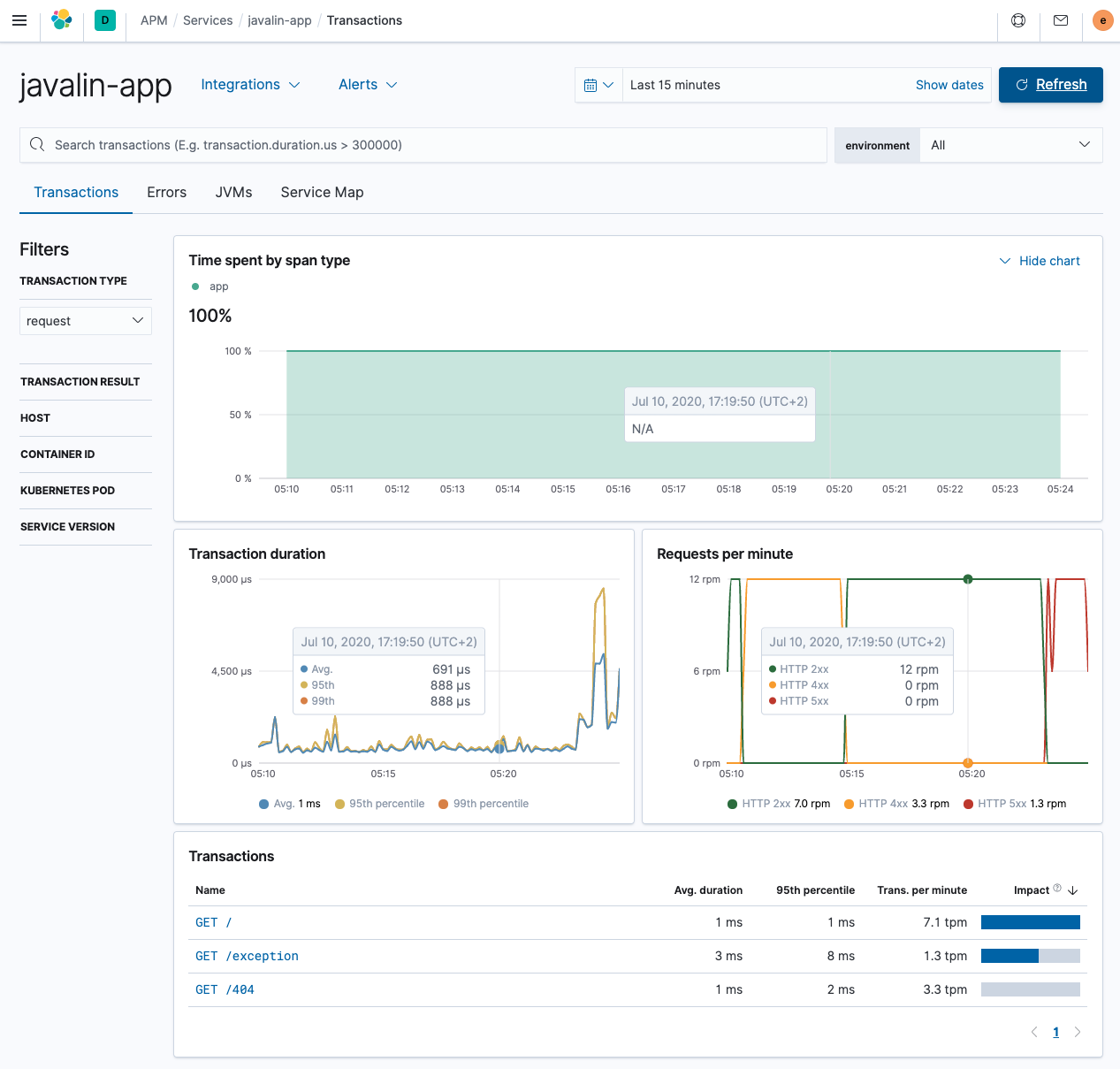
这看起来好多了,端点之间存在差异。
-
添加另一个端点以了解事务的强大功能,该端点轮询另一个 HTTP 服务。您可能听说过 wttr.in,这是一项用于轮询天气信息的服务。让我们实现一个代理 HTTP 方法,将请求转发到该端点。让我们使用 Apache HTTP 客户端,它是目前最典型的 HTTP 客户端之一。
implementation 'org.apache.httpcomponents:fluent-hc:4.5.12'
这是我们的新端点。
import org.apache.http.client.fluent.Request; ... public static void main(String[] args) { ... app.get("/weather/:city", ctx -> { String city = ctx.pathParam("city"); ctx.result(Request.Get("https://wttr.in/" + city + "?format=3").execute() .returnContent().asBytes()) .contentType("text/plain; charset=utf-8"); }); ...
-
Curl
https://127.0.0.1:7000/weather/Munich并查看有关当前天气的一行响应。让我们检查 APM UI。在概述中,您可以看到大部分时间都花在了 HTTP 客户端上,这并不奇怪。
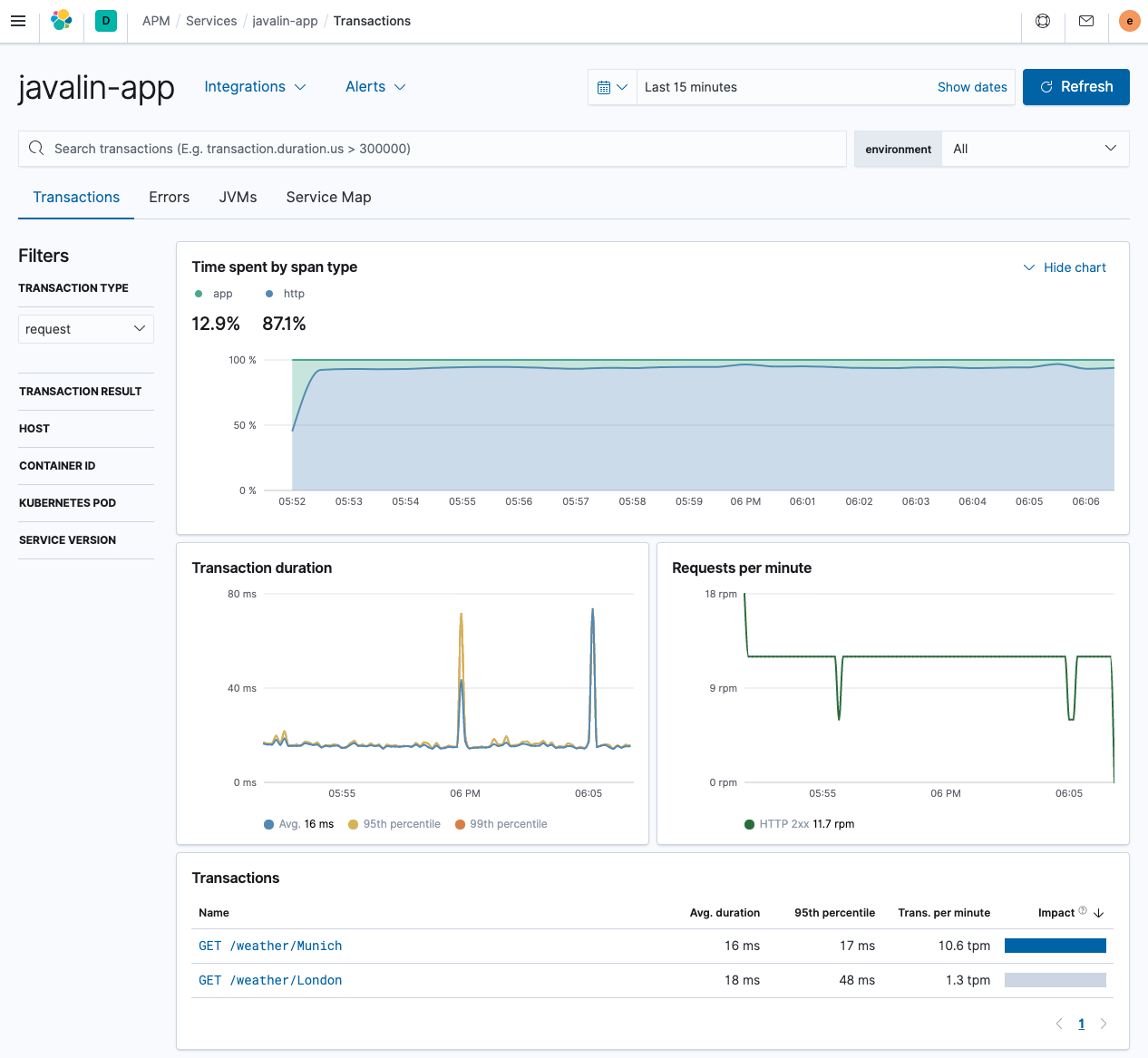
我们针对
/weather/Munich的事务现在包含一个跨度,显示了在检索天气数据上花费了多少时间。由于 HTTP 客户端是自动检测的,因此无需执行任何操作。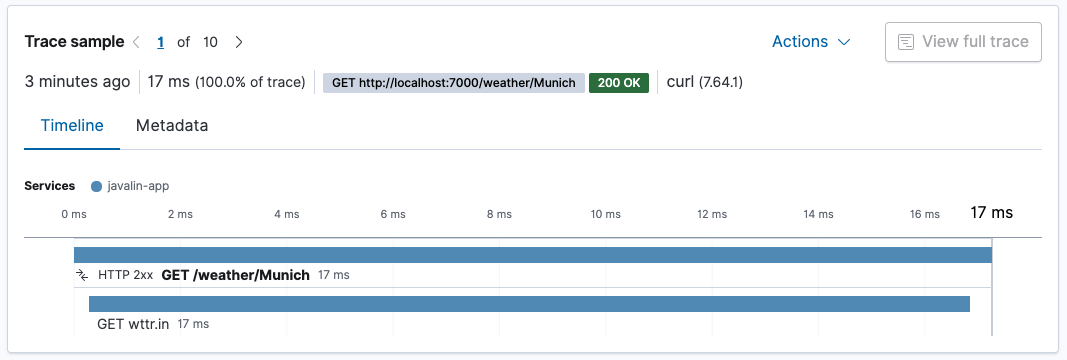
如果该 URL 中的
city参数的基数很高,则将导致提及大量的 URL 而不是通用端点。如果您想防止这种情况发生,一种可能性是使用ctx.matchedPath()将对天气 API 的每次调用记录为GET /weather/:city。但是,这需要通过删除app.before()处理程序并将其替换为app.after()处理程序来进行一些重构。app.after(ctx -> ElasticApm.currentTransaction().setName(ctx.method() + " " + ctx.endpointHandlerPath()));
通过代理配置进行方法跟踪
编辑您还可以配置代理来跟踪方法,而不是编写代码来跟踪方法。让我们尝试找出日志记录是否是应用程序的瓶颈,并跟踪我们之前添加的请求记录器语句。
代理可以根据其签名跟踪方法。
要监视的接口是具有 handle 方法的 io.javalin.http.RequestLogger 接口。因此,让我们尝试使用 io.javalin.http.RequestLogger#handle 来标识要记录的方法,并将其放入您的 .env 中。
ELASTIC_APM_TRACE_METHODS="de.spinscale.javalin.Log4j2RequestLogger#handle"
-
还要创建一个专用的记录器类以匹配上述跟踪方法。
package de.spinscale.javalin; import io.javalin.http.Context; import io.javalin.http.RequestLogger; import org.jetbrains.annotations.NotNull; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class Log4j2RequestLogger implements RequestLogger { private final Logger logger = LoggerFactory.getLogger(Log4j2RequestLogger.class); @Override public void handle(@NotNull Context ctx, @NotNull Float executionTimeMs) throws Exception { String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-"; logger.info("{} {} {} {} \"{}\" {}", ctx.method(), ctx.req.getPathInfo(), ctx.res.getStatus(), ctx.req.getRemoteHost(), userAgent, executionTimeMs.longValue()); } }
-
修复我们的
App类中的调用。config.requestLogger(new Log4j2RequestLogger());
-
重新启动您的应用程序,并查看日志记录花费了多少时间。
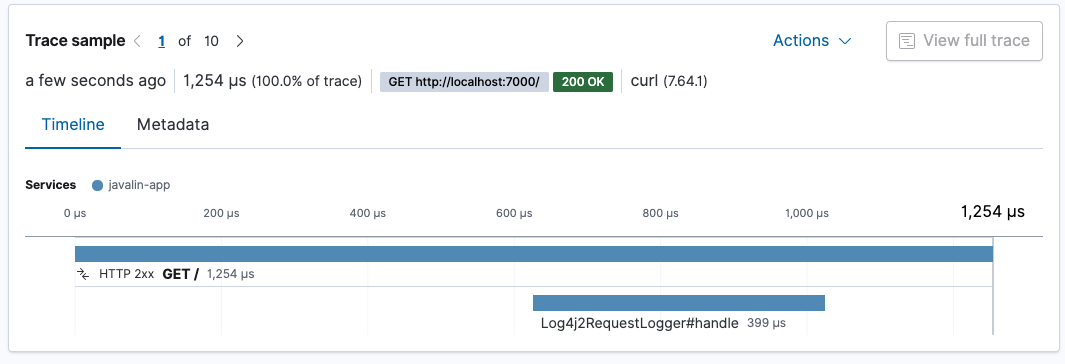
请求记录器大约需要 400 微秒。整个请求大约需要 1.3 毫秒。我们请求处理的约三分之一用于日志记录。
如果您正在追求更快的服务,您可能需要重新考虑日志记录。但是,此日志记录发生在结果写入客户端之后,因此虽然总处理时间随着日志记录的增加而增加,但响应客户端的时间不会增加(但是,关闭连接可能会增加)。另请注意,这些测试是在没有适当预热的情况下进行的。我认为,在 JVM 适当预热后,您将可以更快地处理请求。
自动分析推断跨度
编辑一旦您拥有比我们的示例应用程序更大的应用程序,并且具有更多的代码路径,您可以通过设置以下内容来尝试启用对推断跨度的自动分析。
ELASTIC_APM_PROFILING_INFERRED_SPANS_ENABLED=true
此机制使用 异步分析器来创建跨度,而无需您进行任何检测,从而使您可以更快地找到瓶颈。
日志关联
编辑事务 ID 会自动添加到日志中。您可以检查通过 Filebeat 发送到 Elasticsearch 的生成的日志文件。条目如下所示。
{ "@timestamp": "2020-07-13T12:03:22.491Z", "log.level": "INFO", "message": "GET / 200 0:0:0:0:0:0:0:1 \"curl/7.64.1\" 0", "service.name": "my-javalin-app", "event.dataset": "my-javalin-app.log", "process.thread.name": "qtp34871826-36", "log.logger": "de.spinscale.javalin.Log4j2RequestLogger", "trace.id": "ed735860ec0cd3ee3bdf80ed7ea47afb", "transaction.id": "8af7dff698937dc5" }
添加了 trace.id 和 transaction.id 后,如果发生错误,您将获得 error.id 字段。
我们尚未涵盖 Elastic APM OpenTracing 桥接,或者查看代理提供的其他指标,这使我们可以查看诸如垃圾回收或应用程序的内存占用之类的内容。
步骤 8:摄取正常运行时间数据
编辑到目前为止,我们的应用程序中具有一些基本的监视功能。我们索引日志(带有跟踪),我们索引指标,甚至可以查看我们的应用程序以找出由于 APM 导致的单个性能瓶颈。但是,仍然存在一个薄弱环节。到目前为止所做的一切都在应用程序内部,但是所有用户都是从 Internet 访问该应用程序的。
检查一下我们的用户是否具有与我们的 APM 数据向我们建议的相同的体验如何。想象一下,您的应用程序前端有一个滞后的负载均衡器,这使每个请求的额外成本为 50 毫秒。那将是灾难性的。或者 TLS 协商成本很高。即使这些外部事件都不是您的错,您仍然会受到它的影响,并且应该尝试缓解这些问题。这意味着您首先需要了解它们。
正常运行时间不仅使您能够监视服务的可用性,还可以绘制随时间变化的延迟图,并获得有关 TLS 证书过期的通知。
设置
编辑要将正常运行时间数据发送到 Elasticsearch,需要 Heartbeat(轮询组件)。要下载和安装 Heartbeat,请使用适用于您系统的命令
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.17.0-amd64.deb sudo dpkg -i heartbeat-8.17.0-amd64.deb
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.17.0-x86_64.rpm sudo rpm -vi heartbeat-8.17.0-x86_64.rpm
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.17.0-darwin-x86_64.tar.gz tar xzvf heartbeat-8.17.0-darwin-x86_64.tar.gz
curl -L -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.17.0-linux-x86_64.tar.gz tar xzvf heartbeat-8.17.0-linux-x86_64.tar.gz
- 从下载页面下载 Heartbeat Windows zip 文件。
- 将 zip 文件的内容解压缩到
C:\Program Files。 - 将
heartbeat-<版本>-windows目录重命名为Heartbeat。 - 以管理员身份打开 PowerShell 提示符(右键单击 PowerShell 图标并选择 以管理员身份运行)。
-
从 PowerShell 提示符下,运行以下命令以将 Heartbeat 安装为 Windows 服务
PS > cd 'C:\Program Files\Heartbeat' PS C:\Program Files\Heartbeat> .\install-service-heartbeat.ps1
如果您的系统上禁用了脚本执行,则需要为当前会话设置执行策略,以允许脚本运行。例如:PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-heartbeat.ps1。
下载并解压后,我们必须再次设置云 ID 和密码。
-
我们需要在 Kibana 中以弹性管理员用户身份创建另一个
API_KEY。POST /_security/api_key { "name": "heartbeat_javalin-app", "role_descriptors": { "heartbeat_writer": { "cluster": ["monitor", "read_ilm"], "index": [ { "names": ["heartbeat-*"], "privileges": ["view_index_metadata", "create_doc"] } ] } } }
-
让我们设置 Heartbeat 密钥库并运行设置。
./heartbeat keystore create echo -n "observability-javalin-app:ZXUtY2VudHJhbC0xLmF3cy5jbG91ZC5lcy5pbyQ4NDU5M2I1YmQzYTY0N2NhYjA2MWQ3NTJhZWFhNWEzYyQzYmQwMWE2OTQ2MmQ0N2ExYjdhYTkwMzI0YjJiOTMyYQ==" | ./heartbeat keystore add CLOUD_ID --stdin echo -n "SCdUSHMB1JmLUFPLgWAY:R3PQzBWW3faJT01wxXD6uw" | ./heartbeat keystore add ES_API_KEY --stdin ./heartbeat setup -e -E 'cloud.id=${CLOUD_ID}' -E 'cloud.auth=elastic:YOUR_SUPER_SECRET_PASS'
-
添加一些要监视的服务。
name: heartbeat-shipper cloud.id: ${CLOUD_ID} output.elasticsearch: api_key: ${ES_API_KEY} heartbeat.monitors: - type: http id: javalin-http-app name: "Javalin Web Application" urls: ["https://127.0.0.1:7000"] check.response.status: [200] schedule: '@every 15s' - type: http id: httpbin-get name: "httpbin GET" urls: ["https://httpbin.org/get"] check.response.status: [200] schedule: '@every 15s' - type: tcp id: javalin-tcp name: "TCP Port 7000" hosts: ["localhost:7000"] schedule: '@every 15s' processors: - add_observer_metadata: geo: name: europe-munich location: "48.138791, 11.583030"
- 现在启动 Heartbeat 并等待几分钟以获取一些数据。
sudo service heartbeat start
如果你使用 init.d 脚本来启动 Heartbeat,你无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前台启动 Heartbeat。
另请参阅 Heartbeat 和 systemd。
sudo service heartbeat start
如果你使用 init.d 脚本来启动 Heartbeat,你无法指定命令行标志(请参阅 命令参考)。要指定标志,请在前台启动 Heartbeat。
另请参阅 Heartbeat 和 systemd。
|
你将以 root 用户身份运行 Heartbeat,因此你需要更改配置文件的所有权,或者在运行 Heartbeat 时指定 |
|
你将以 root 用户身份运行 Heartbeat,因此你需要更改配置文件的所有权,或者在运行 Heartbeat 时指定 |
PS C:\Program Files\heartbeat> Start-Service heartbeat
默认情况下,Windows 日志文件存储在 C:\ProgramData\heartbeat\Logs 中。
要查看 Uptime 应用程序,请选择 可观察性 → Uptime。概览如下所示。
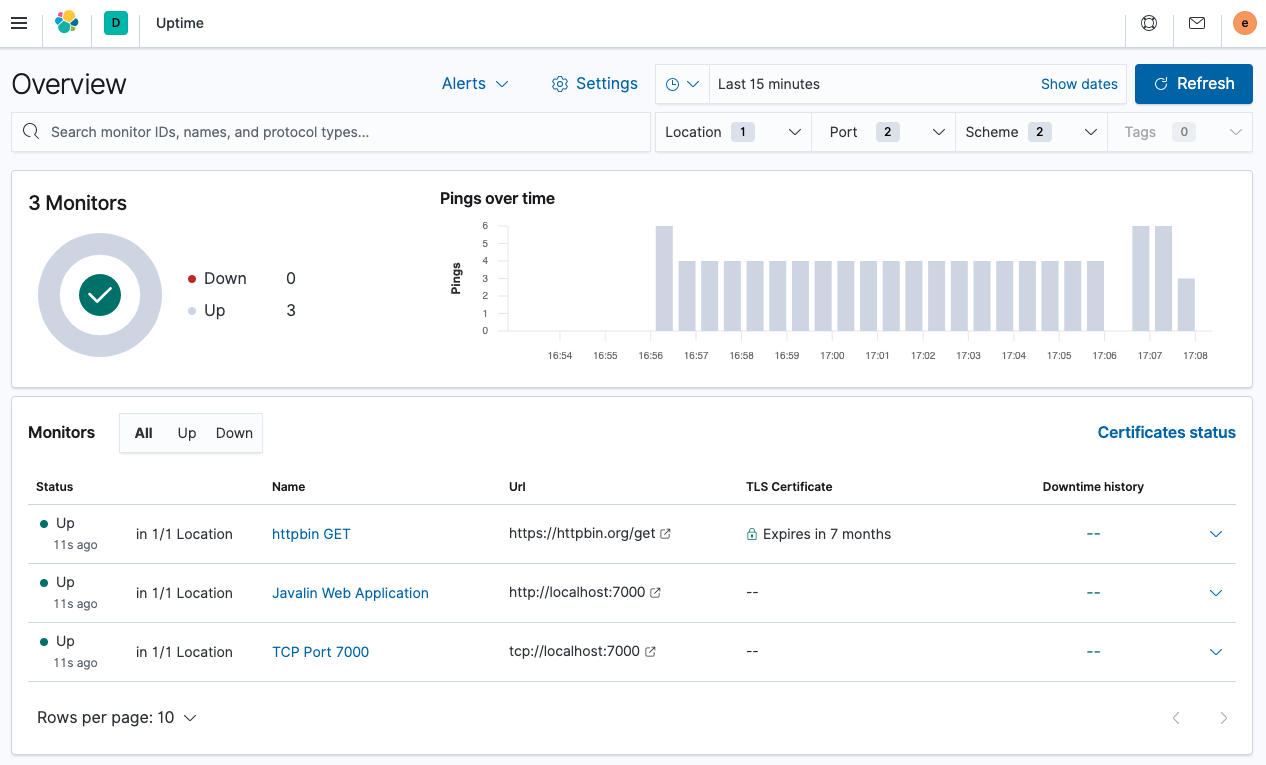
你可以看到监视器列表和全局概览。让我们查看其中一个警报的详细信息。点击 Javalin Web Application。
你可以看到上次计划检查的执行情况,但每次检查的持续时间可能更有趣。你可以看到其中一个检查的延迟是否正在增加。
有趣的部分是顶部的世界地图。你可以在配置中指定检查的来源,在这种情况下,它位于欧洲的慕尼黑。通过配置多个在世界各地运行的 Heartbeat,你可以比较延迟并确定你需要运行应用程序的数据中心,以便靠近你的用户。
监视器的持续时间在低毫秒范围内,因为它真的很快。检查 httpbin.org 端点的监视器,你会看到更高的持续时间。在这种情况下,每次请求大约需要 400 毫秒。这并不奇怪,因为端点不在附近,并且你每次请求都需要初始化 TLS 连接,这会产生很大的成本。
不要低估这种监控的重要性。此外,请考虑这仅仅是一个开始,因为下一步是拥有监控应用程序正确行为的综合监控,例如,确保你的结账流程始终正常工作。
下一步是什么?
编辑有关使用 Elastic 可观察性的更多信息,请参阅 可观察性文档。
On this page
- 您将学到什么
- 开始之前
- 步骤 1:创建 Java 应用程序
- 步骤 2:采集日志
- 添加日志记录实现
- 记录请求
- 创建 ISO8601 时间戳
- 记录到文件和标准输出
- 安装和配置 Filebeat
- 将数据发送到 Elasticsearch
- 步骤 3:在 Kibana 中查看日志
- 步骤 4:处理您的日志
- 结构化日志
- 解析异常
- 配置日志轮换
- 摄取节点
- 将日志写为 JSON
- 步骤 5:摄取指标
- 将指标添加到应用程序
- 安装和配置 Metricbeat
- 步骤 6:在 Kibana 中查看指标
- 可视化随时间推移的打开文件
- 步骤 7:检测应用程序
- 数据模型
- 将 APM 代理添加到您的代码中
- 自动附加
- 程序化设置
- 自定义事务
- 通过代理配置进行方法跟踪
- 自动分析推断跨度
- 日志关联
- 步骤 8:摄取正常运行时间数据
- 设置
- 下一步是什么?