- 可观测性其他版本
- 开始
- 应用程序和服务
- CI/CD
- 云
- 基础设施和主机
- 日志
- 故障排除
- 事件管理
- 数据集质量
- 可观测性 AI 助手
- 参考
服务概览
编辑服务概览
编辑选择一个非移动端的 服务 会将您带到 服务概览。 服务概览 包含各种图表和表格,可提供对服务在整个基础设施中性能的高级可见性。
- 服务详细信息,如服务版本、运行时版本、框架以及 APM 代理名称和版本
- 容器和编排信息
- 云提供商、机器类型、服务名称、区域和可用区
- 无服务器函数名称和事件触发类型
- 随时间变化的延迟、吞吐量和错误
- 服务依赖项
时间序列和预期边界比较
编辑为了深入了解服务的健康状况,您可以比较服务相对于之前的时间段或来自相应异常检测作业的预期边界的性能。 例如,延迟是否随着时间的推移而缓慢增加,服务是否经历了突然的峰值,吞吐量是否与机器学习作业预期的相似——启用比较可以提供答案。
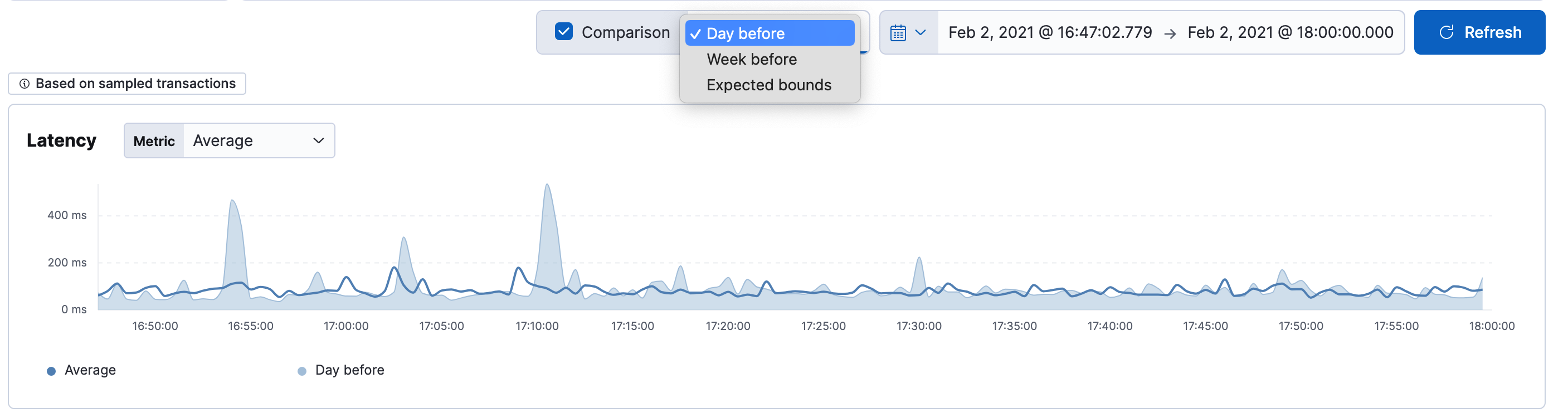
选择 比较 框以应用基于时间的比较或预期边界比较。 基于时间的比较选项基于选定的时间过滤器范围
| 时间过滤器 | 时间比较选项 |
|---|---|
≤ 24 小时 |
一天或一周 |
> 24 小时且 ≤ 7 天 |
一周 |
> 7 天 |
与选定时间范围紧邻的前一段时间 |
如果您的选定环境中存在机器学习作业,并且您有访问机器学习功能的权限,则可以使用预期边界比较。
延迟
编辑服务的响应时间。 您可以过滤 延迟 图表,以显示该服务的平均、第 95 百分位或第 99 百分位延迟时间。

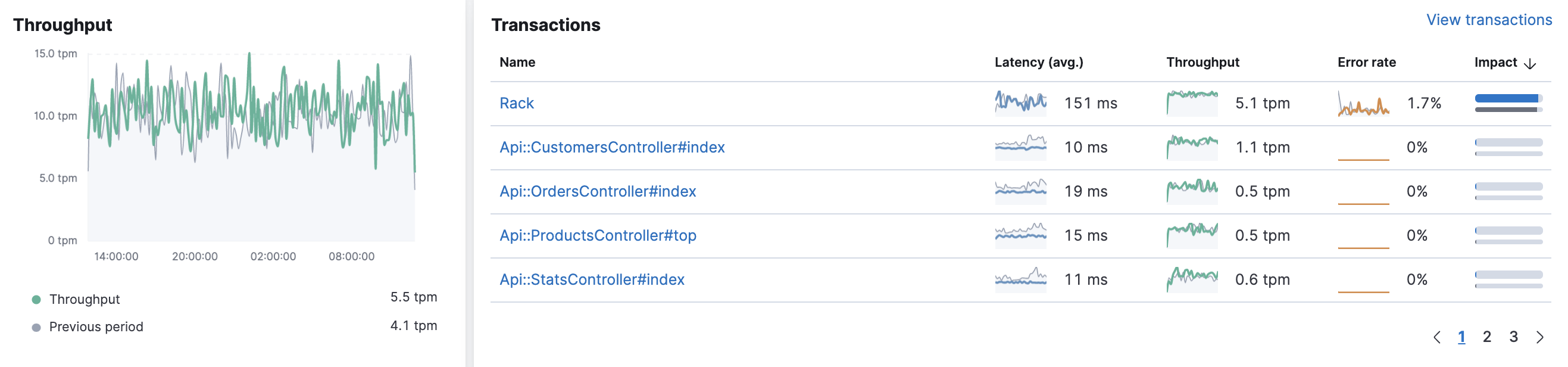
吞吐量和事务
编辑吞吐量 图表可视化了所选服务的每分钟平均事务数。
事务 表显示了所选服务的事务组列表,并包括每个事务的延迟、流量、错误率和影响。 共享相同名称的事务将被分组,并且每个组仅显示一个条目。
默认情况下,事务组按影响排序,以显示服务中最常用和最慢的端点。 如果您对某个特定端点感兴趣,请单击 查看事务 以在事务概览页面上查看类似事务的列表。
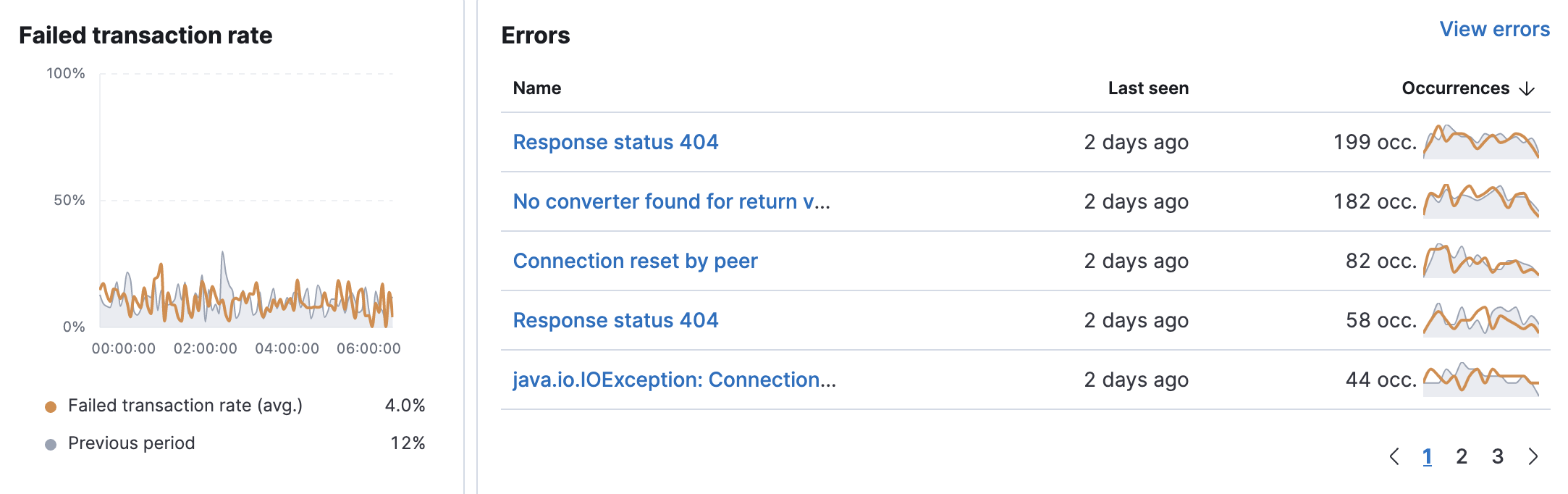
失败事务率和错误
编辑失败事务率表示从所选服务的角度来看失败事务的百分比。 它有助于可视化服务事务中意外的增加、减少或不规则模式。
来自 HTTP 服务器视角的 HTTP 事务 不会将 4xx 状态代码(客户端错误)视为失败,因为失败是由调用者而不是 HTTP 服务器引起的。 因此,event.outcome=success 并且失败事务率不会增加。
但是,如果 HTTP 状态代码 ≥ 400,则来自客户端视角的 HTTP 跨度 会被视为失败。 这些跨度将设置 event.outcome=failure 并增加失败事务率。
如果没有 HTTP 状态,则除非报告错误,否则事务和跨度都被认为是成功的。
错误 表提供了每个错误消息首次和最后一次发生以及总发生次数的高级视图。 这使得可以非常容易地快速查看哪些错误会影响您的服务并采取措施纠正它们。 为此,请单击 查看错误。
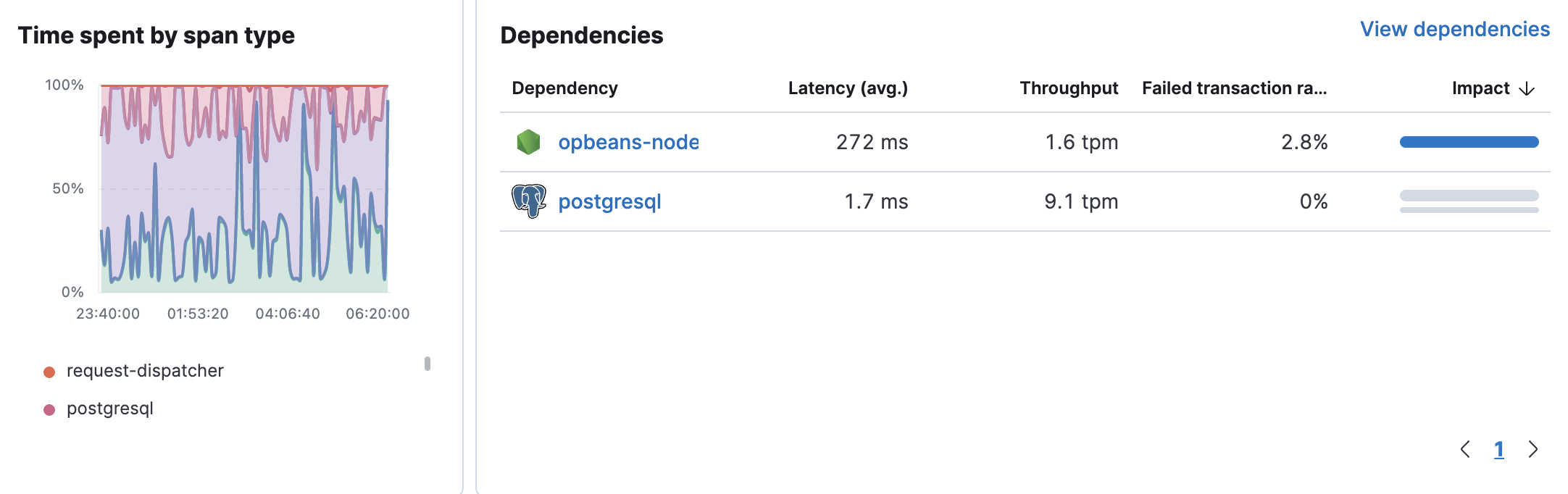
跨度类型平均持续时间和依赖项
编辑按跨度类型花费的时间 图表可视化了每种跨度类型的平均持续时间,并帮助您确定哪些跨度可能会减慢事务的速度。 图表下显示的“app”标签表示应用程序内部正在发生某些事情。 这可能表明 APM 代理对于该时间段内发生的任何事情都没有自动检测,或者时间花费在应用程序代码中,而不是数据库或外部请求中。
依赖项 表显示了与所选时间范围内服务相关的下游服务或外部连接的列表。 该表显示了每个依赖项的延迟、吞吐量、失败事务率和影响。 默认情况下,依赖项按影响排序,以显示最常用和最慢的依赖项。 如果您对某个特定依赖项感兴趣,请单击 查看依赖项 以了解更多信息。
显示使用真实用户监控 (RUM) 代理检测的服务依赖项需要代理版本 ≥ v5.6.3。
冷启动率
编辑冷启动率图表特定于无服务器服务,并显示触发无服务器函数冷启动的请求百分比。 当无服务器函数在一段时间内未使用时,会发生冷启动。 分析冷启动率有助于确定要为函数分配多少内存,或者何时删除大型依赖项。
冷启动率图表目前支持 AWS Lambda 函数和 Azure 函数。
实例
编辑实例 表显示了在选定时间范围内所有可用的服务实例的列表。 根据服务的运行方式,实例可以是主机或容器。 该表显示了每个实例的延迟、吞吐量、失败事务、CPU 使用率和内存使用率。 默认情况下,实例按吞吐量排序。

服务元数据
编辑要查看与服务代理相关的元数据,以及(如果相关)容器和云提供商,请单击页面顶部服务名称旁边的每个图标。
服务信息
- 服务版本
- 运行时名称和版本
- 框架名称
- APM 代理名称和版本
容器信息
- 操作系统
- 已容器化 - 是或否。
- 实例总数
- 编排
云提供商信息
- 云提供商
- 云服务名称
- 可用区
- 机器类型
- 项目 ID
- 区域
无服务器信息
- 函数名称
- 事件触发类型
警报
- 最近触发的警报