- 可观测性其他版本
- 开始
- 应用程序和服务
- CI/CD
- 云
- 基础设施和主机
- 日志
- 故障排除
- 事件管理
- 数据集质量
- 可观测性 AI 助手
- 参考
创建日志阈值规则
编辑创建日志阈值规则
编辑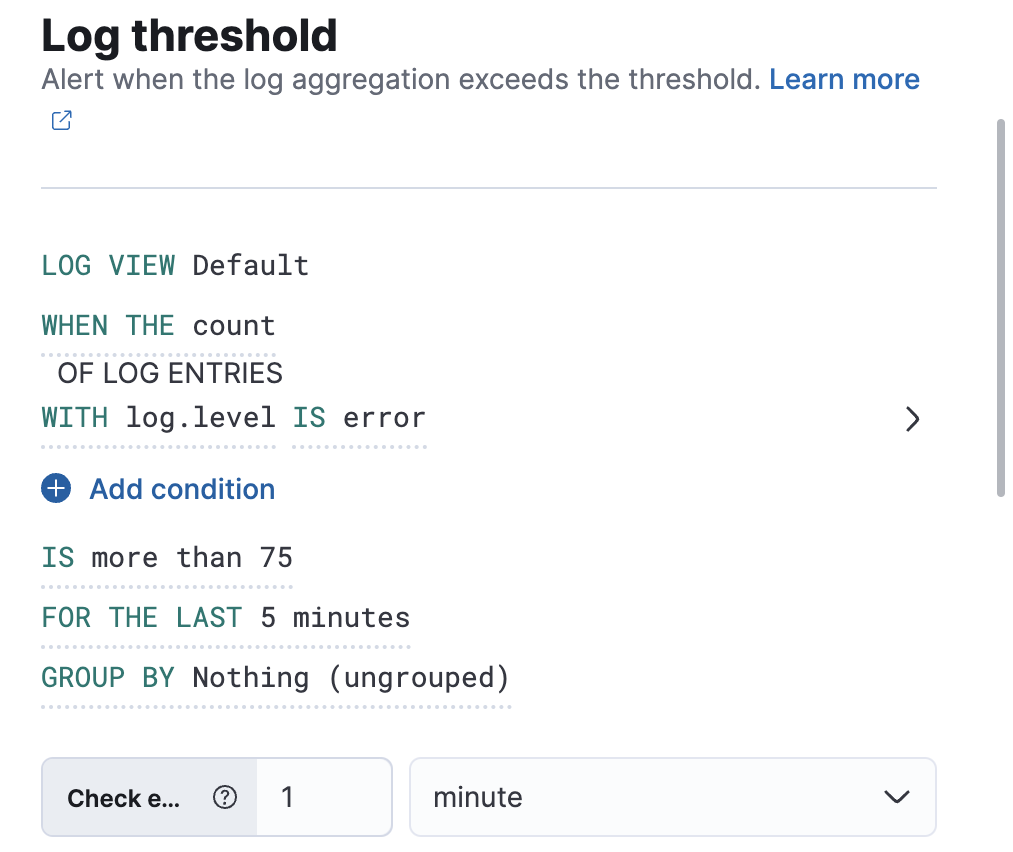
字段和比较器
编辑可用作条件的比较器取决于所选的字段。可用的组合如下:
- 数值字段:大于、大于或等于、小于或小于或等于。
- 可聚合字段:是或不是。
-
不可聚合字段:匹配、不匹配、匹配短语、不匹配短语。
-
匹配 查询您输入的值的部分或全部内容,而无需考虑顺序。例如,
WITH message MATCHES your example message会查找包含your、example和message单词的消息,并返回包含其中部分或全部单词的结果。 -
匹配短语 查询您输入的值的确切内容。例如,
WITH message MATCHES PHRASE your example message会查找短语your example message,并返回包含该确切短语的结果。
-
匹配 查询您输入的值的部分或全部内容,而无需考虑顺序。例如,
有几个关键的支持用例。您可以基于包含或匹配文本模式的字段创建规则,基于数值字段和算术运算符创建规则,或者创建一个具有多个条件的单个规则。
不同的 Elasticsearch 查询类型支持每个比较器,在某些情况下,了解这些查询类型对于正确配置规则非常重要。上面列出的比较器映射到以下 Elasticsearch 查询类型:
- 大于:使用 gt 的 range
- 大于或等于:使用 gte 的 range
- 小于:使用 lt 的 range
- 小于或等于:使用 lte 的 range
- 是和不是:term
- 匹配和不匹配:match
- 匹配短语和不匹配短语:match_phrase
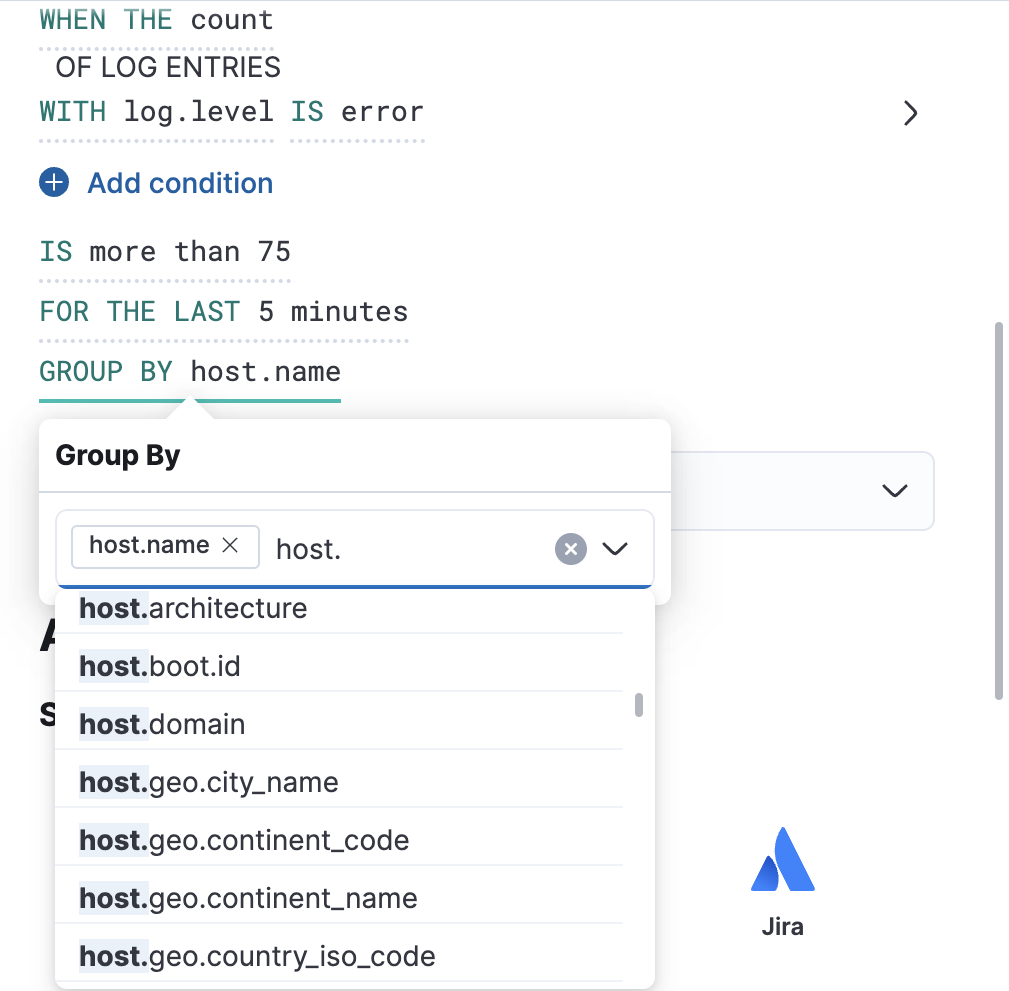
分组依据
编辑可以为日志阈值规则设置分组依据。您可以设置一个或多个分组。
设置分组依据时,会对所选字段执行复合聚合。当任何这些组匹配所选的规则条件时,会每个组触发警报。
在选择了多个分组的情况下,组名用逗号分隔。
例如,如果选择 host.name 和 host.architecture 作为分组依据字段,并且有两个主机(主机 A 和 主机 B)和两个架构(架构 A 和 架构 B),则复合聚合会形成多个组。我们将重点关注 主机 A,架构 A 和 主机 B,架构 B 组。
如果组 主机 A,架构 A 匹配规则条件,但 主机 B,架构 B 不匹配,则会触发一个警报。
类似地,如果选择了一个分组依据,例如 host.name,并且主机 A 匹配条件,但主机 B 不匹配,则会为主机 A 触发一个警报。如果两个组都匹配条件,则会触发两个警报。
当选择了分组依据字段,但在触发警报的给定时间范围内,没有文档包含所选字段时,则无法确定组。当规则条件对特定数量的文档敏感,并且该数量可能为 0 时,这很重要。例如,当查询主机是否具有少于五个文档匹配条件时,由于主机在查询期间没有报告日志,因此不会触发警报。
图表预览
编辑要确定有多少日志条目会匹配您的配置的每个部分,您可以查看每个条件的图表预览。这对于确定有多少日志条目会匹配您的配置的每个部分很有用。当设置了分组依据时,图表将为每个组显示一个条形。要查看预览,请选择条件旁边的箭头。
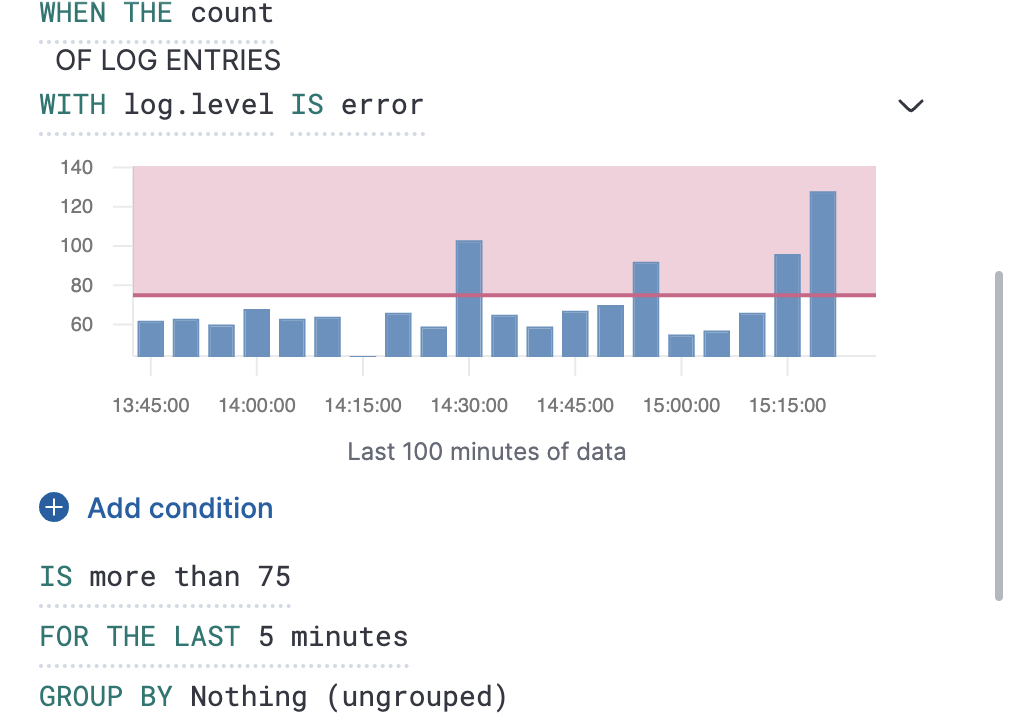
阴影区域表示已选择的阈值。
比率规则
编辑要了解一个查询与另一个查询的比较情况,请创建一个比率规则。当比率值达到特定阈值时,会触发此类型的规则。比率阈值是第一个查询(查询 A)的文档计数除以第二个查询(查询 B)的文档计数。
以下示例在错误日志的数量是警告日志的两倍时触发警报。
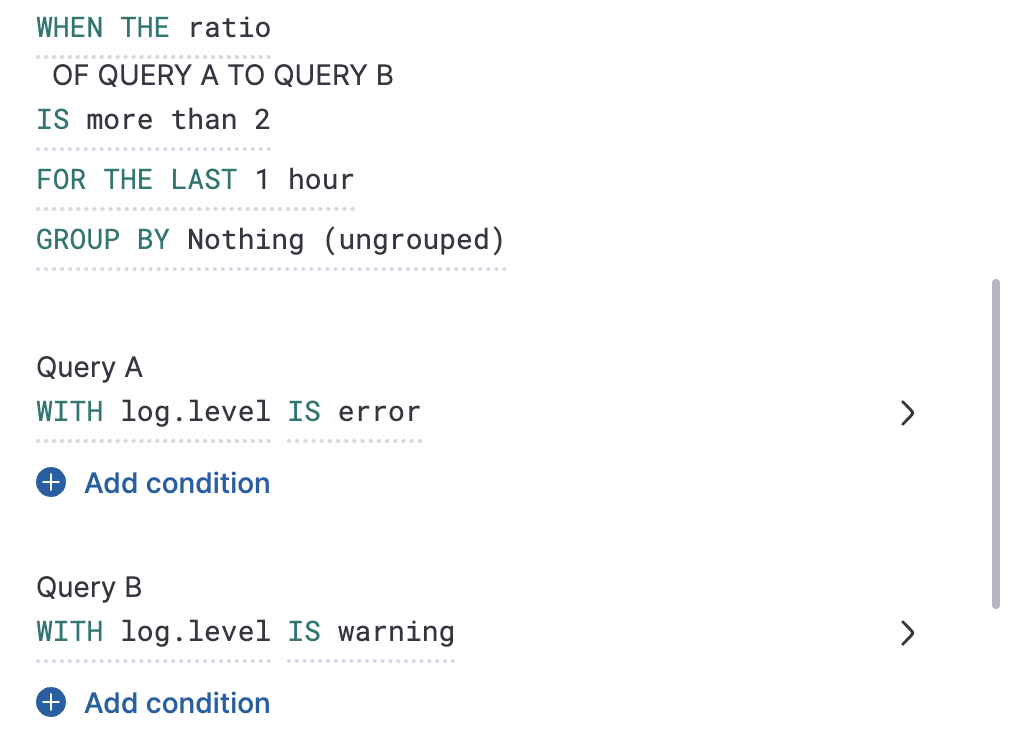
由于无法除以 0,当查询 A 或查询 B 的文档计数为 0 时,会导致未定义/不确定的比率。在这种情况下,不会触发警报。
操作类型
编辑通过将规则连接到使用以下支持的内置集成的操作来扩展规则。
某些连接器类型是付费的商业功能,而其他类型是免费的。有关 Elastic 订阅级别的比较,请转到订阅页面。
选择连接器后,必须设置操作频率。您可以选择在每个检查间隔或自定义间隔创建警报摘要。或者,您可以设置操作频率,以便选择操作的运行频率(例如,在每个检查间隔、仅在警报状态更改时或在自定义操作间隔)。在这种情况下,您还必须选择影响操作运行时间的特定阈值条件:已触发或已恢复。
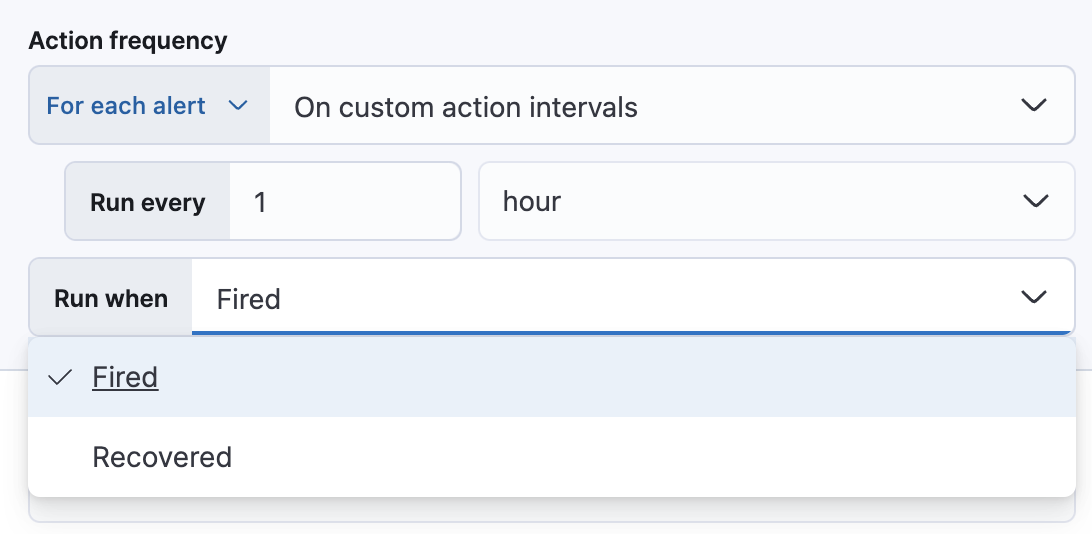
您还可以通过指定操作仅在它们匹配 KQL 查询或警报在特定时间范围内发生时运行,来进一步细化操作运行的条件
- 如果警报匹配查询:输入一个 KQL 查询,该查询定义必须满足才能发送通知的字段值对或查询条件。该查询仅在为规则指定的索引中搜索警报文档。
- 如果警报在时间范围内生成:设置时间范围详细信息。仅当在您定义的时间范围内生成警报时,才会发送通知。
操作变量
编辑使用默认的通知消息或自定义它。您可以通过单击消息文本框上方的图标并从可用变量列表中选择来向消息添加更多上下文。
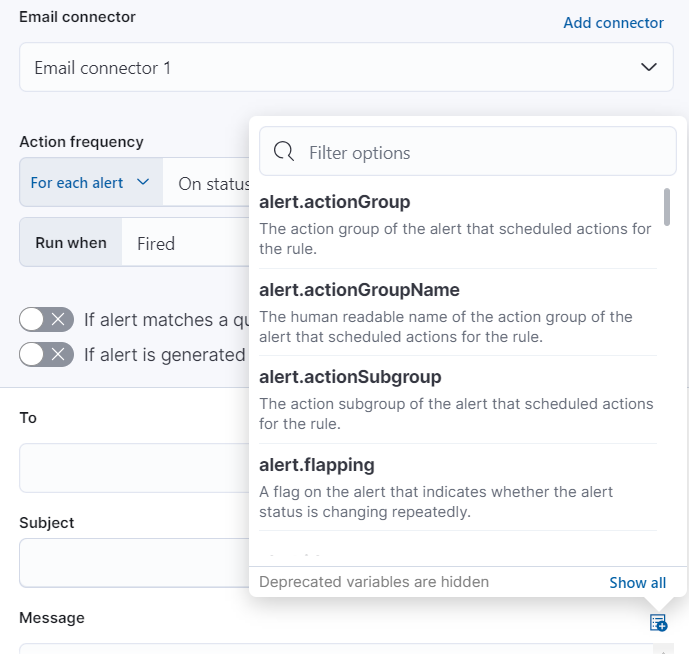
以下变量特定于此规则类型。您还可以指定所有规则通用的变量。
-
context.alertDetailsUrl - 指向警报故障排除视图的链接,以获取更多上下文和详细信息。如果未配置
server.publicBaseUrl,则这将是一个空字符串。 -
context.interval - 满足警报条件的时间段的长度和单位。
-
context.reason - 对警报原因的简要描述。
-
context.serviceName - 为其创建警报的服务。
-
context.threshold - 高于此值的任何触发值都将导致触发警报。
-
context.transactionName - 为其创建警报的事务名称。
-
context.transactionType - 为其创建警报的事务类型。
-
context.triggerValue - 违反阈值并触发警报的值。
-
context.viewInAppUrl - 指向警报源的链接。
性能注意事项
编辑当设置分组依据时,我们建议对阈值使用大于比较器——这允许我们的查询应用急切过滤,从而显著提高性能。否则,我们建议使用基数最低(可能性数量)的分组依据字段。
Elasticsearch 查询(高级)
编辑执行规则检查时,会根据规则的配置构建查询。在绝大多数情况下,没有必要知道这些查询是什么。但是,为了确定最佳配置或帮助调试,查看这些查询的结构可能会很有用。以下是以下配置的 Elasticsearch 查询示例:
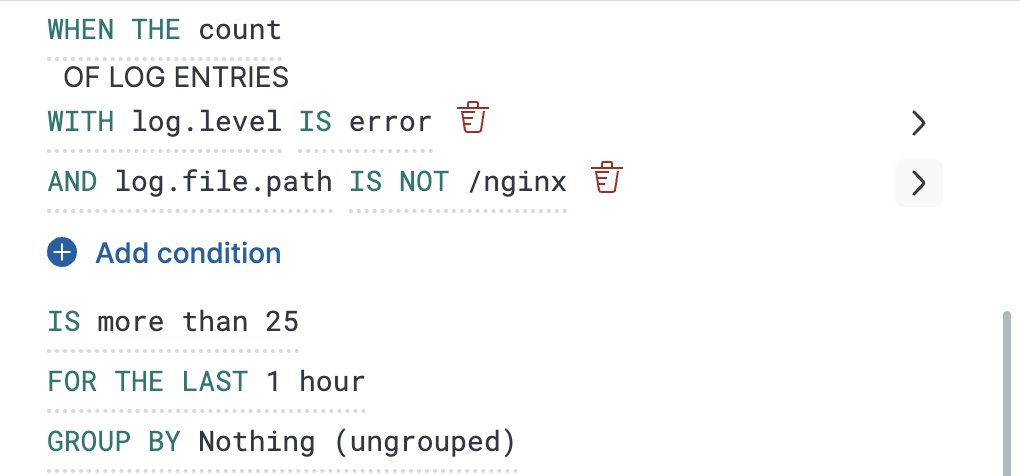
不使用分组依据。
{ "index":"filebeat-*", "allowNoIndices":true, "ignoreUnavailable":true, "body":{ "track_total_hits":true, "query":{ "bool":{ "filter":[ { "range":{ "@timestamp":{ "gte":1600771280862, "lte":1600774880862, "format":"epoch_millis" } } }, { "term":{ "log.level":{ "value":"error" } } } ], "must_not":[ { "term":{ "log.file.path":{ "value":"/nginx" } } } ] } }, "size":0 } }

使用分组依据。
{ "index":"filebeat-*", "allowNoIndices":true, "ignoreUnavailable":true, "body":{ "query":{ "bool":{ "filter":[ { "range":{ "@timestamp":{ "gte":1600768208910, "lte":1600779008910, "format":"epoch_millis" } } } ] } }, "aggregations":{ "groups":{ "composite":{ "size":40, "sources":[ { "group-0-host.name":{ "terms":{ "field":"host.name" } } } ] }, "aggregations":{ "filtered_results":{ "filter":{ "bool":{ "filter":[ { "range":{ "@timestamp":{ "gte":1600771808910, "lte":1600775408910, "format":"epoch_millis" } } }, { "term":{ "log.level":{ "value":"error" } } } ], "must_not":[ { "term":{ "log.file.path":{ "value":"/nginx" } } } ] } } } } } }, "size":0 } }
设置
编辑使用日志阈值规则时,无法在配置中设置显式的索引模式。索引模式是从日志应用程序的设置页面上的日志索引中推断出来的。
在每次执行规则检查时,都会检查日志索引设置,但创建规则时不会存储该设置。
在设置下设置的时间戳字段决定了查询中哪个字段用于时间戳。