- 可观测性其他版本
- 开始
- 应用程序和服务
- CI/CD
- 云
- 基础设施和主机
- 日志
- 故障排除
- 事件管理
- 数据集质量
- 可观测性 AI 助手
- 参考
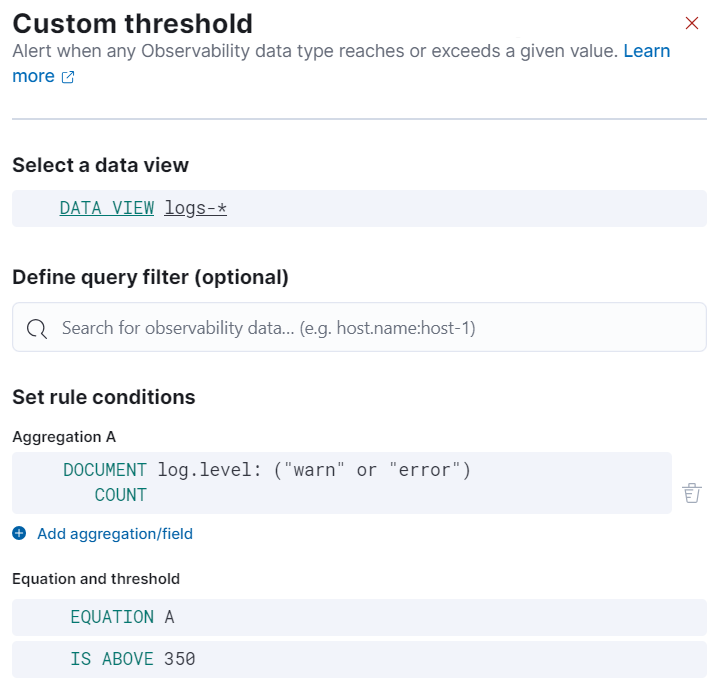
创建自定义阈值规则
编辑创建自定义阈值规则
编辑创建自定义阈值规则,以便在可观测性数据类型达到或超过给定值时触发警报。
定义规则数据
编辑指定以下设置以定义规则应用的数据
- 选择数据视图: 单击数据视图字段以搜索并选择指向您正在为其创建规则的索引或数据流的数据视图。您还可以通过单击 创建数据视图 来创建新的数据视图。有关创建数据视图的更多信息,请参阅 创建数据视图。
-
定义查询过滤器(可选): 使用查询过滤器来缩小规则应用的数据范围。例如,使用查询过滤器
host.name:host-1将查询过滤器设置为特定主机名,以便仅将规则应用于该主机。
设置规则条件
编辑使用聚合、方程式和阈值设置规则检测的条件。
设置聚合
编辑聚合汇总您的数据,使其更易于分析。设置以下任意聚合类型来收集数据以创建您的规则:Average、Max、Min、Cardinality、Count、Sum、Percentile 或 Rate。有关这些选项的更多信息,请参阅 聚合选项。
例如,要收集日志级别为 warn 的日志文档总数
- 将 聚合 设置为 文档计数,并将 KQL 过滤器 设置为
log.level: "warn"。 - 将阈值设置为
高于 100,以便在日志级别为warn的日志文档数达到 100 时触发警报。
设置方程式和阈值
编辑使用您的聚合设置方程式。根据方程式的结果,设置一个阈值来定义何时触发警报。方程式使用基本的数学或布尔逻辑。请参阅以下示例了解可能的用例。
基本数学方程式
编辑添加、减去、乘或除您的聚合,以定义警报条件。
示例
设置方程式和阈值,以便在指标高于阈值时触发警报。在此示例中,我们将使用平均 CPU 使用率——除 idle 或 IOWait 状态之外的其他状态所花费的 CPU 时间百分比,该值由 CPU 核心数标准化——并在 CPU 使用率高于特定百分比时触发警报。为此,请设置以下聚合、方程式和阈值
-
设置以下聚合
-
聚合 A: 平均
system.cpu.user.pct -
聚合 B: 平均
system.cpu.system.pct -
聚合 C: 最大
system.cpu.cores。
-
聚合 A: 平均
- 将方程式设置为
(A + B) / C * 100 - 将阈值设置为
高于 95,以便在 CPU 使用率高于 95% 时发出警报。
布尔逻辑
编辑使用条件运算符和比较运算符与您的聚合一起定义警报条件。
示例
设置方程式和阈值,以便在有状态 Pod 的数量与所需 Pod 的数量不同时触发警报。在此示例中,我们将使用 kubernetes.statefulset.ready 和 kubernetes.statefulset.desired,并在它们的值不同时触发警报。为此,请设置以下聚合、方程式和阈值
-
设置以下聚合
-
聚合 A: 总和
kubernetes.statefulset.ready -
聚合 B: 总和
kubernetes.statefulset.desired
-
聚合 A: 总和
- 将方程式设置为
A == B ? 1 : 0。如果 A 和 B 相等,则结果为1。如果它们不相等,则结果为0。 - 将阈值设置为
低于 1,以便在结果为0且字段值不匹配时触发警报。
预览图表
编辑预览图表提供了与您的配置匹配的条目数量的可视化效果。阴影区域显示您设置的阈值。
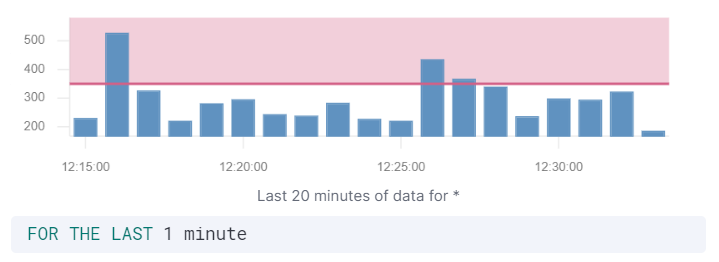
如果您使用 按分组警报 选项,则最大条形大小将为 3。它只会显示前 3 个字段。
按分组警报(可选)
编辑为自定义阈值规则设置一个或多个 按分组警报 字段,以针对选定字段执行复合聚合。当这些组中的任何一个与选定的规则条件匹配时,将按组触发警报。
当您选择多个分组时,组名称将以逗号分隔。
例如,如果您按 host.name 和 host.architecture 字段对警报进行分组,并且有两个主机(主机 A 和 主机 B)和两个架构(架构 A 和 架构 B),则复合聚合形成多个组。
如果 主机 A, 架构 A 组与规则条件匹配,但 主机 B, 架构 B 组不匹配,则将为 主机 A, 架构 A 触发一个警报。
如果您选择一个字段(例如 host.name),并且 主机 A 与条件匹配,但 主机 B 不匹配,则将为 主机 A 触发一个警报。如果两个组都与条件匹配,则将为两个组触发警报。
触发“无数据”警报(可选)
编辑可以选择配置规则在以下情况下触发警报
- 没有数据,或
- 先前检测到的组停止报告数据。
为此,请选择 如果没有数据则向我发出警报。
警报的行为取决于是否指定了任何 按分组警报 字段
- 没有“按分组警报”字段:(默认)如果条件未在预期的时间段内报告数据,或者规则无法查询 Elasticsearch,则会触发“无数据”警报。此警报表示存在问题,并且没有足够的数据来评估相关阈值。
-
有“按分组警报”字段:如果先前检测到的组停止报告数据,则会为缺失的组触发“无数据”警报。
例如,考虑
host.name是 CPU 使用率高于 80% 的 按分组警报 字段的情况。规则第一次运行时,两个主机报告数据:host-1和host-2。规则第二次运行时,host-1未报告任何数据,因此会为host-1触发“无数据”警报。当规则再次运行时,如果host-1再次开始报告数据,则可能会出现几种情况- 如果
host-1报告了 CPU 使用率数据,并且高于 80% 的阈值,则不会触发新警报。而是将现有警报从“无数据”更改为违反阈值的触发警报。请记住,在这种情况下不会发送通知,因为仍然存在正在进行的问题。 - 如果
host-1报告的 CPU 使用率低于 80% 的阈值,则警报状态将更改为已恢复。
- 如果
如何取消跟踪已停用的主机
如果主机(例如,host-1)已停用,您可能不再希望看到有关它的“无数据”警报。要将警报标记为未跟踪
转到“警报”表,单击 ![]() 图标以展开“更多操作”菜单,然后单击 标记为未跟踪。
图标以展开“更多操作”菜单,然后单击 标记为未跟踪。
选择角色可见性
编辑您必须选择一个范围值(日志 或 指标),这会影响访问该规则所需的 Kibana 功能权限。例如,当设置为 日志 时,您必须具有相应的 可观测性 > 日志 功能权限才能查看或编辑该规则。
操作类型
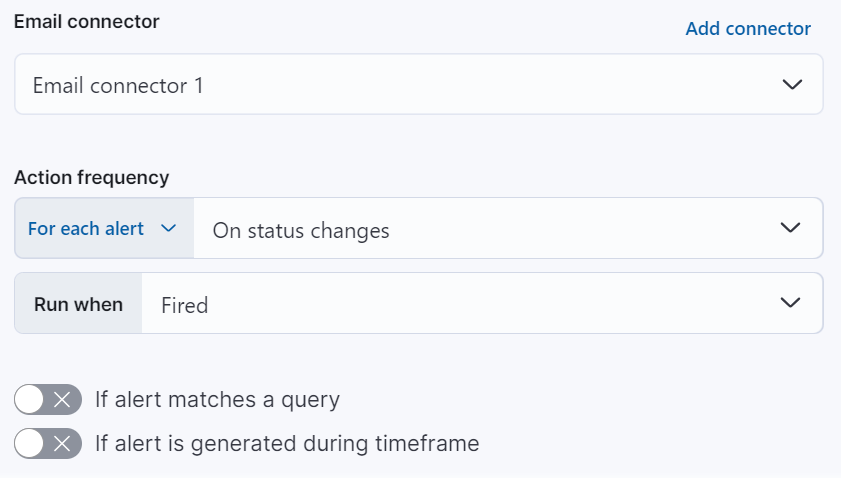
编辑通过将您的规则连接到使用以下受支持的内置集成操作来扩展您的规则。
某些连接器类型是付费的商业功能,而其他连接器类型是免费的。有关 Elastic 订阅级别的比较,请转到 订阅页面。
选择连接器后,必须设置操作频率。您可以选择在每个检查间隔或自定义间隔上创建警报摘要。或者,您可以设置操作频率,以便您可以选择操作的运行频率(例如,在每个检查间隔、仅当警报状态更改时或在自定义操作间隔)。在这种情况下,您还必须选择影响操作运行时间的特定阈值条件:警报、无数据 或 已恢复。
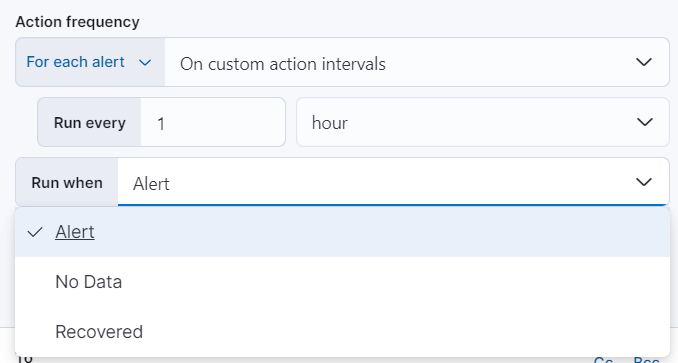
您还可以通过指定操作仅在与 KQL 查询匹配或警报发生在特定时间范围内时才运行,从而进一步优化操作运行的条件
- 如果警报与查询匹配:输入定义必须满足的字段值对或查询条件的 KQL 查询,以便发送通知。查询仅在为规则指定的索引中搜索警报文档。
- 如果在时间范围内生成警报:设置时间范围详细信息。仅当在您定义的时间范围内生成警报时才发送通知。
操作变量
编辑使用默认通知消息或自定义通知消息。 您可以通过点击消息文本框上方的图标,并从可用变量列表中选择,向消息添加更多上下文信息。
以下变量是此规则类型特有的。您还可以指定所有规则通用的变量。
-
context.alertDetailsUrl - 指向警报故障排除视图的链接,以获取更多上下文和详细信息。 如果未配置
server.publicBaseUrl,则这将是一个空字符串。 -
context.cloud - 如果源中可用,则由 ECS 定义的云对象。
-
context.container - 如果源中可用,则由 ECS 定义的容器对象。
-
context.group - 包含正在报告数据的组的对象。
-
context.host - 如果源中可用,则由 ECS 定义的主机对象。
-
context.labels - 与触发此警报的实体关联的标签列表。
-
context.orchestrator - 如果源中可用,则由 ECS 定义的编排器对象。
-
context.reason - 警报原因的简要描述。
-
context.tags - 与触发此警报的实体关联的标签列表。
-
context.timestamp - 检测到警报的时间戳。
-
context.value - 条件值的列表。
-
context.viewInAppUrl - 指向警报源的链接。