- 可观测性其他版本
- 开始
- 应用程序和服务
- CI/CD
- 云
- 基础设施和主机
- 日志
- 故障排除
- 事件管理
- 数据集质量
- 可观测性 AI 助手
- 参考
通用分析
编辑通用分析
编辑Elastic 通用分析是一种全系统、常开、连续的分析解决方案,无需代码插桩、重新编译、主机调试符号和服务重启。利用 eBPF 技术,通用分析在 Linux 内核空间内运行,以不引人注意的方式捕获所需数据,且开销极小。有关通用分析的快速概览,请参阅通用分析产品页面。
在此页面上,您将找到有关以下方面的信息:
在 Kibana 中检查数据
编辑要打开通用分析,请在主菜单中找到基础设施,或使用全局搜索字段。
在通用分析下,单击堆栈跟踪以打开堆栈跟踪视图。
通用分析目前仅支持通过堆栈采样进行 CPU 分析。
从堆栈跟踪视图中,您可以获得所有数据的概述。您还可以使用搜索栏中的筛选查询,将您的数据切片为更详细的机群部分。基于时间的筛选器和属性筛选器允许您检查数据部分,并深入了解您的基础设施的各个部分随着时间的推移消耗了多少 CPU。
有关切片数据的更多信息,请参阅筛选,有关比较两个时间范围以检测性能改进或回归的更多信息,请参阅差异视图。
调试符号
编辑您的堆栈跟踪可以是
- 符号化的,显示完整的源代码的文件名和行号
- 部分符号化的
- 未符号化的
在以下屏幕截图中,您可以看到未符号化的帧不显示文件名和行号,而是显示十六进制数字,例如 0x80d2f4 或 <unsymbolized>。
为未符号化的帧添加符号当前是手动操作。请参阅为本机帧添加符号。

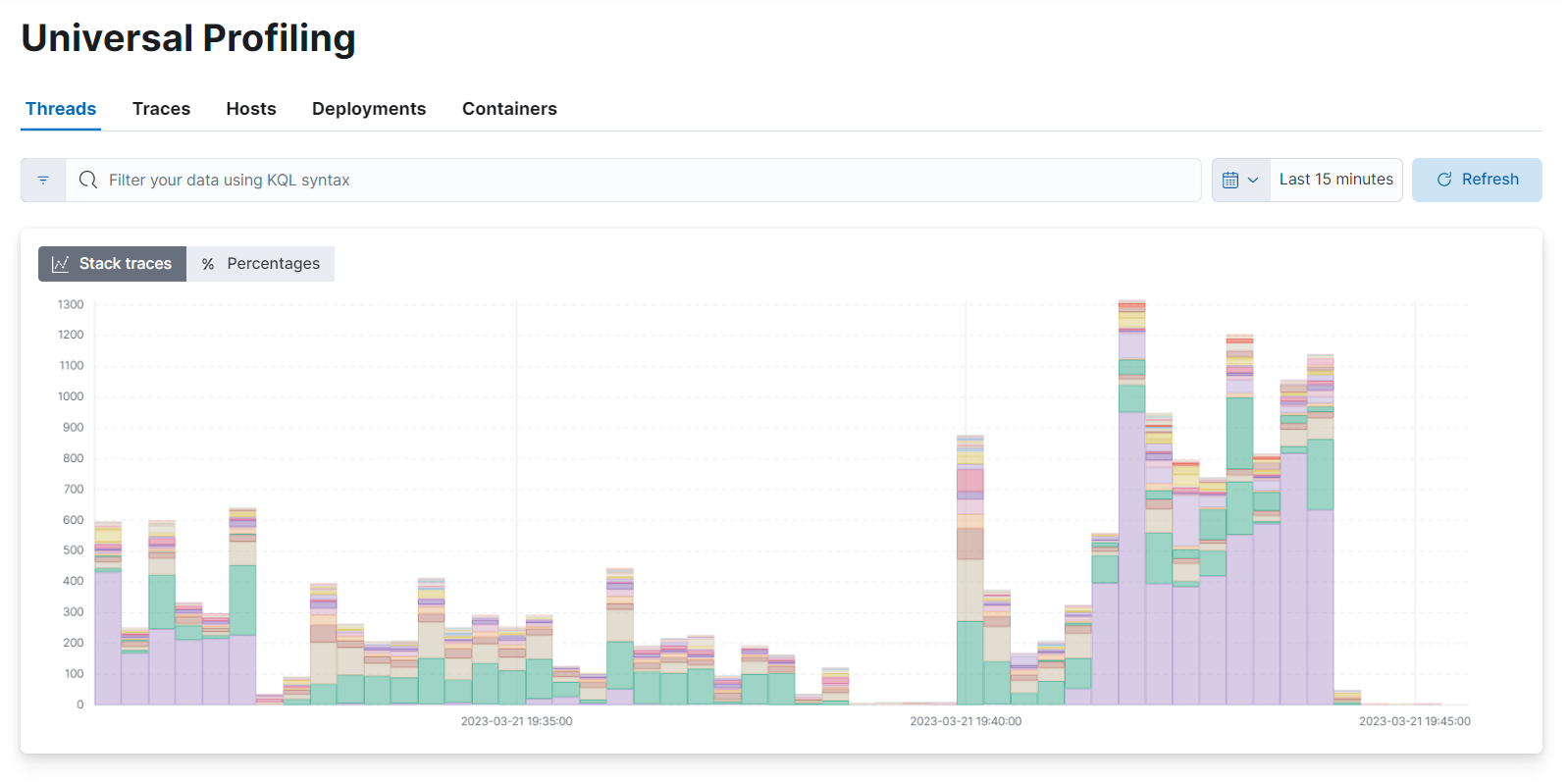
堆栈跟踪
编辑堆栈跟踪视图显示按线程、跟踪、主机、部署和容器分组的堆栈跟踪图表
概述
编辑堆栈跟踪页面上的不同视图显示
- 线程:按进程的线程名称分组的堆栈跟踪
- 跟踪:未分组的堆栈跟踪
- 主机:按机器的主机名或 IP 地址分组的堆栈跟踪
-
部署:按容器编排设置的部署名称分组的堆栈跟踪(例如,Kubernetes
ReplicaSet、DaemonSet或StatefulSet名称) - 容器:按主机代理发现的容器名称分组的堆栈跟踪
堆栈跟踪视图提供可用于以下方面的有价值信息:
- 发现哪个跨多台机器部署的容器正在使用最多的 CPU。
- 发现来自在您的机器上运行的第三方软件的相对开销有多大。
- 检测跨线程的意外 CPU 峰值,并深入研究较小的时间范围,以便使用火焰图进一步调查。
堆栈跟踪基于收集的堆栈跟踪的来源进行分组。如果您的主机代理部署正在分析任何不运行容器或容器编排器的系统,您可能会在容器和部署中找到一个空视图。在通用分析正确从主机代理接收数据的部署中,您应该始终在线程、主机和跟踪视图中看到图表。
导航堆栈跟踪视图
编辑将鼠标悬停并单击每个堆叠条形图部分以显示详细信息。您可以安排图表以显示绝对值或相对百分比值。
在顶部图表下方,有显示每个项目的各个趋势线的单独图表
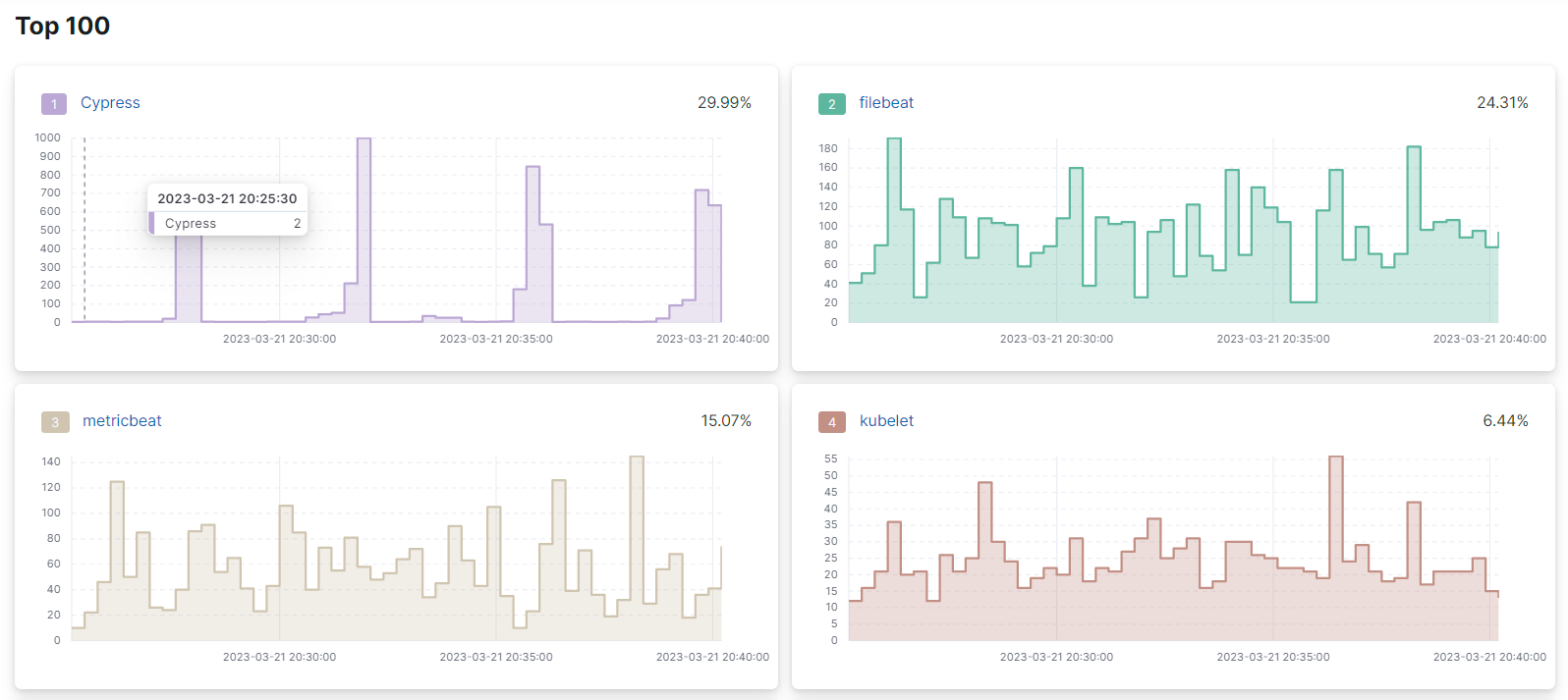
每个单独图表的右上角显示的百分比是每次在组中的样本总数中出现的相对次数。
显示的百分比与 CPU 使用率的百分比不同。通用分析并非旨在显示绝对监控数据。相反,它允许对您的基础设施中运行的软件进行相对比较(例如,哪个最昂贵?)
各个图表按降序排列,从上到下,从左到右。
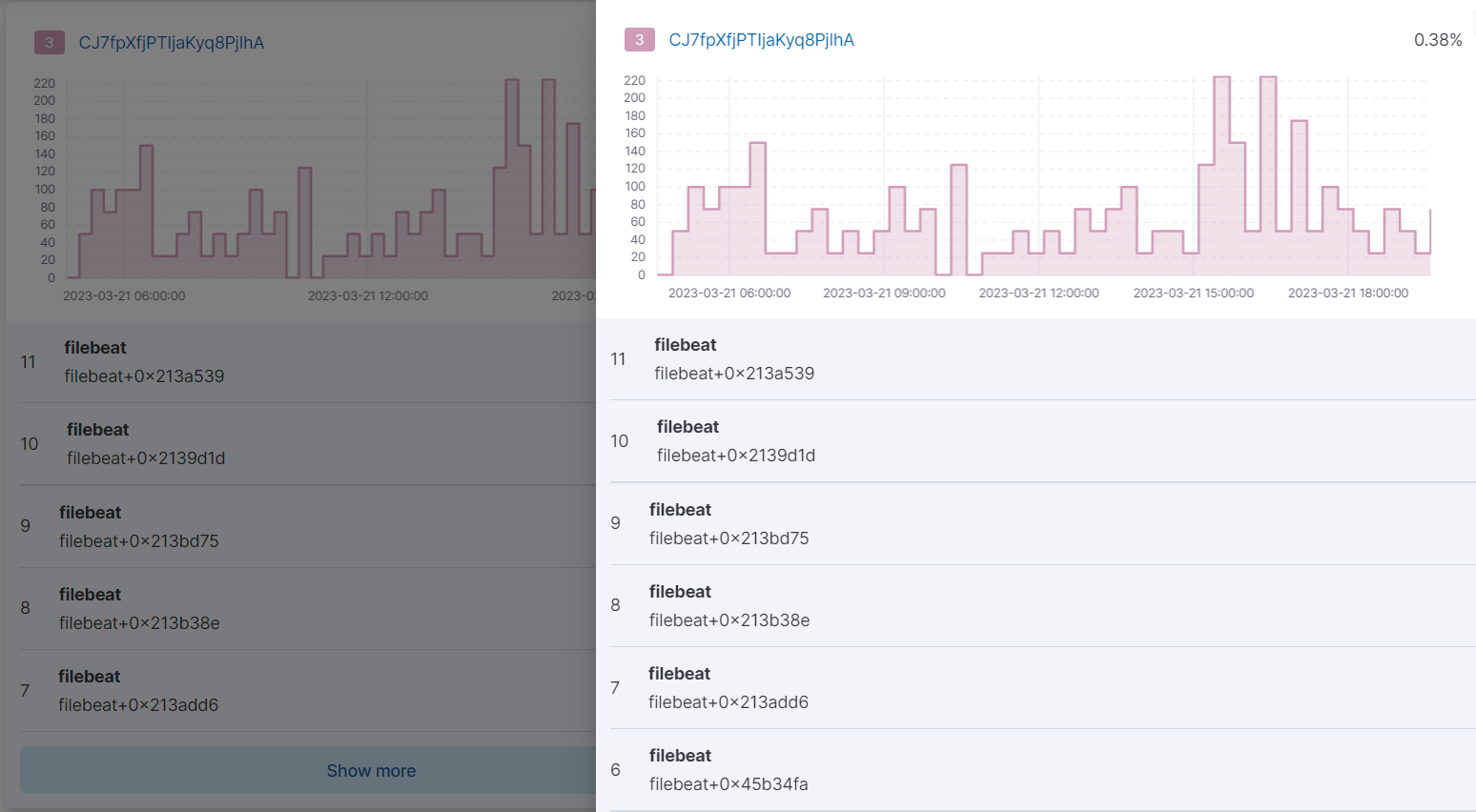
在跟踪选项卡中,单击其中一个单独图表底部的显示更多以显示完整的堆栈跟踪。
火焰图
编辑火焰图视图将分层数据(堆栈跟踪)分组为彼此堆叠或相邻的矩形。每个矩形的大小表示子项相对于其父项的相对权重。
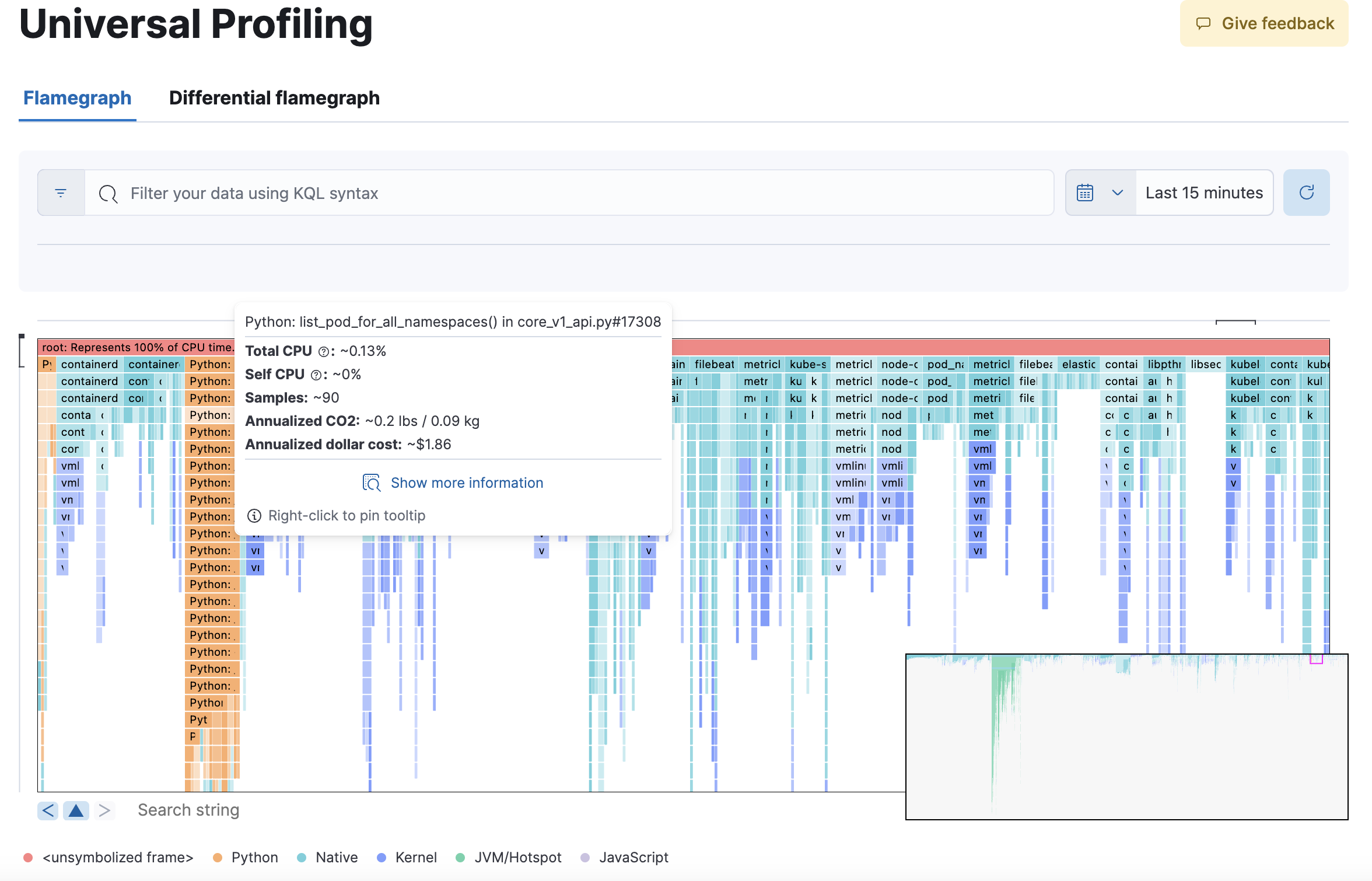
概述
编辑火焰图提供了关于应该首先搜索软件的哪些部分以寻找优化机会的即时反馈,突出了整个基础设施中最热的代码路径。
您可以使用火焰图来
- 检测对链接到您自己的软件的系统调用或本机库的意外使用:通用分析能够将用户空间边界的堆栈跟踪展开到内核空间
- 检查 CPU 密集型应用程序的调用堆栈,检测热代码路径并寻找优化机会
- 找到“深”调用堆栈,通常暗示类或对象之间存在许多间接操作的区域
导航火焰图视图
编辑您可以在水平轴和垂直轴上导航火焰图
- 水平轴:每个采样的进程在
root帧下至少有一个矩形。在通用分析火焰图中,您可能会发现您不控制但正在占用您大量 CPU 资源的进程的存在。 - 垂直轴:遍历进程的调用堆栈允许您识别进程的哪些部分执行最频繁。这允许查明应该可以忽略不计,但实际上是您的调用站点中很大一部分的函数或方法。
您可以向上、向下、向右或向左拖动图表以移动可见区域。
您可以通过单击各个帧或在彩色视图中向上滚动来放大和缩小堆栈跟踪的子集。
图表左下角的摘要正方形允许您移动图表的可见区域。当您拖动火焰图时,右下角的摘要正方形的位置会调整,并且移动摘要正方形会调整较大面板中的可见区域。
将鼠标悬停在火焰图中的矩形上会在窗口中显示帧的详细信息。要查看更多帧信息,请在固定工具提示后单击显示更多信息图标。
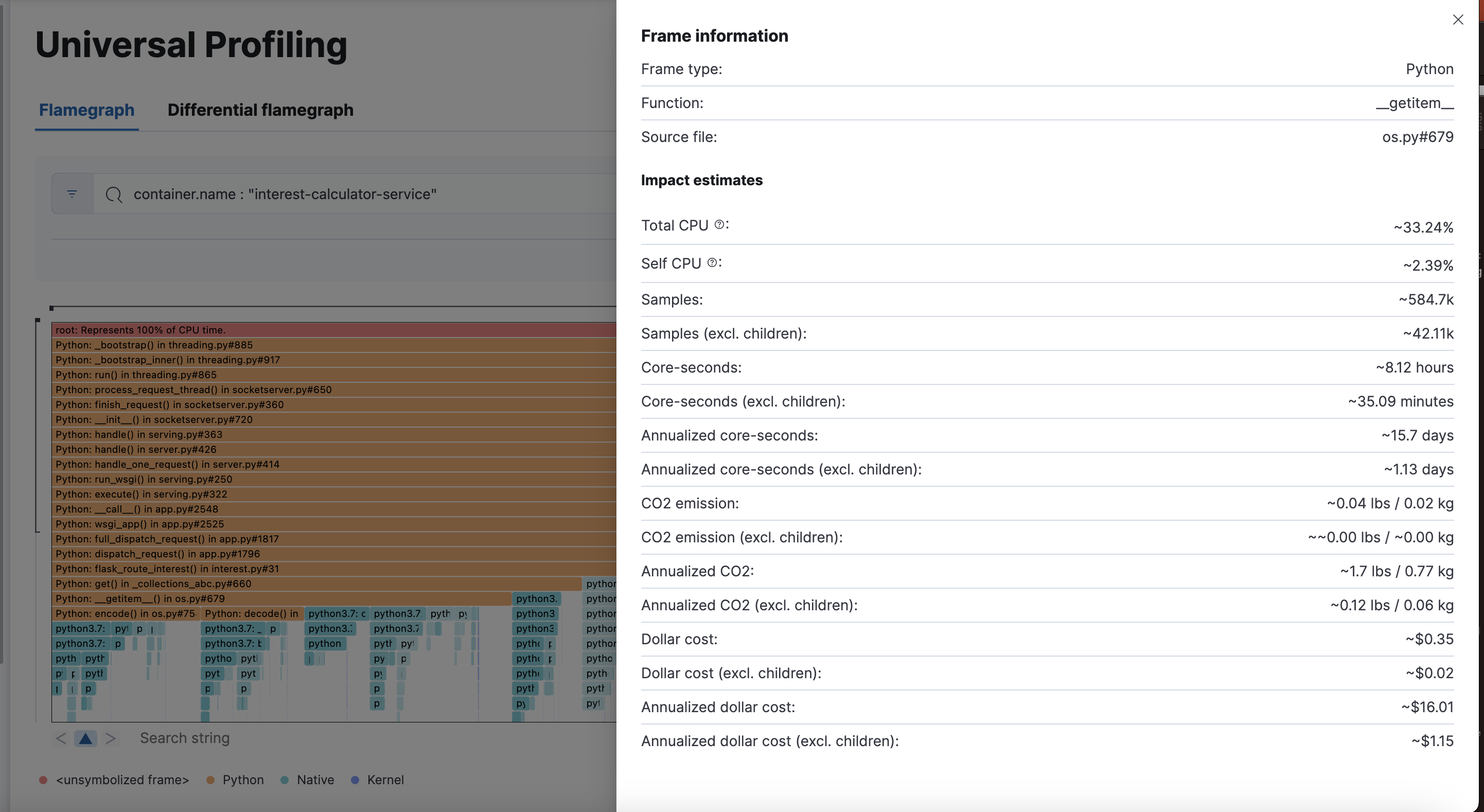
在图表区域下方,您可以使用搜索栏在火焰图中查找特定文本;在这里,您可以搜索二进制文件、函数或文件名,并在出现的地方移动。
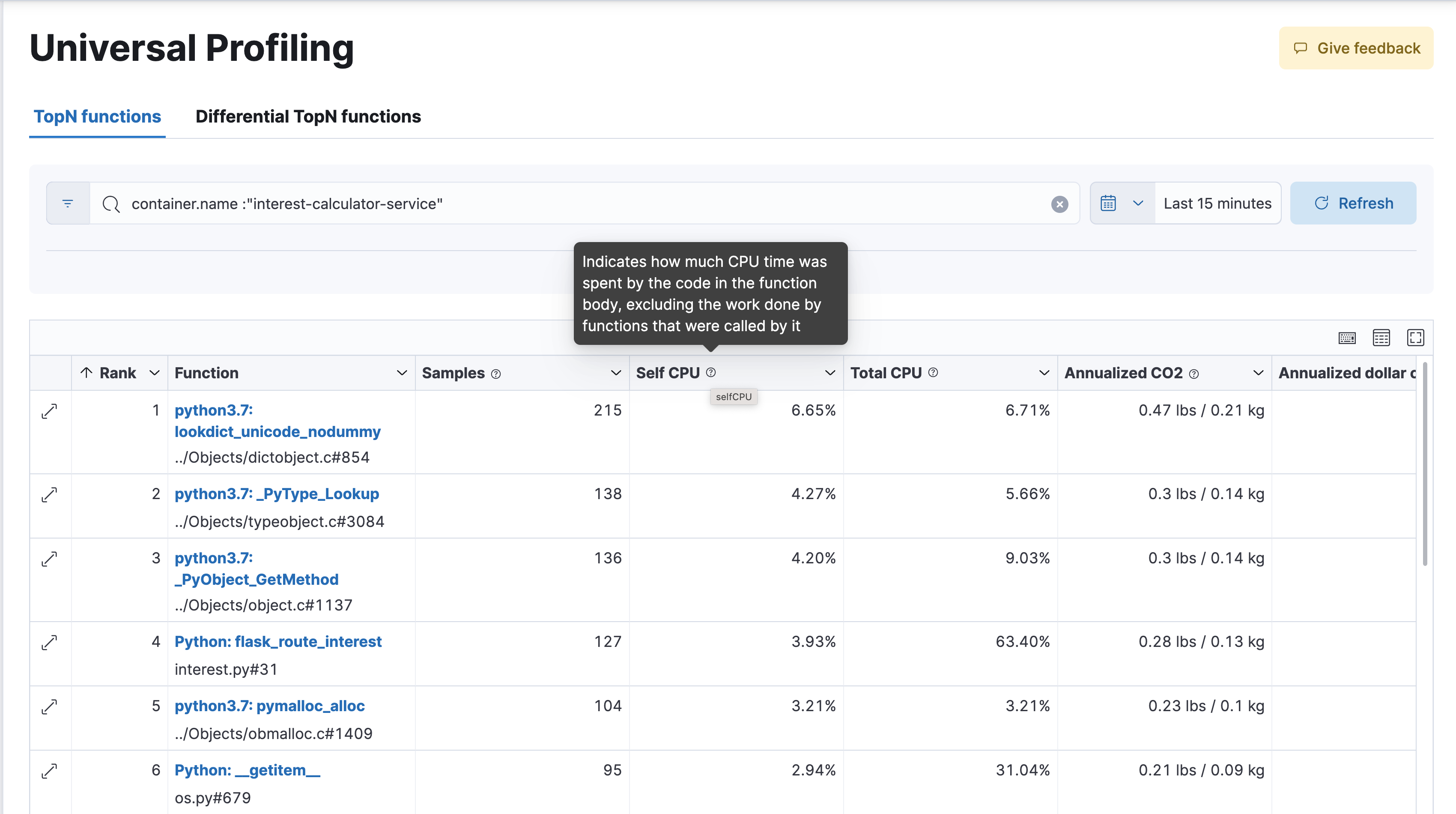
函数
编辑函数视图呈现一个按顺序排列的列表,其中包含通用分析最常采样的函数。从这个视图中,您可以找到在整个基础设施中运行最多的函数,应用筛选器以深入研究各个组件。
筛选
编辑在所有通用分析视图中,搜索栏都接受 Kibana 查询语言 (KQL) 的筛选器。
最值得注意的是,您可能希望筛选以下内容:
-
profiling.project.id:project-id主机代理标志的对应值,已部署的主机代理的逻辑组 -
process.thread.name:进程的线程名称,例如python、java或kauditd -
orchestrator.resource.name:容器化部署的组的名称,由编排器设置 -
container.name:单个容器实例的名称,由容器引擎设置 -
host.name或host.ip:机器的主机名或 IP 地址(用于调试单个虚拟机上的问题)
差异视图
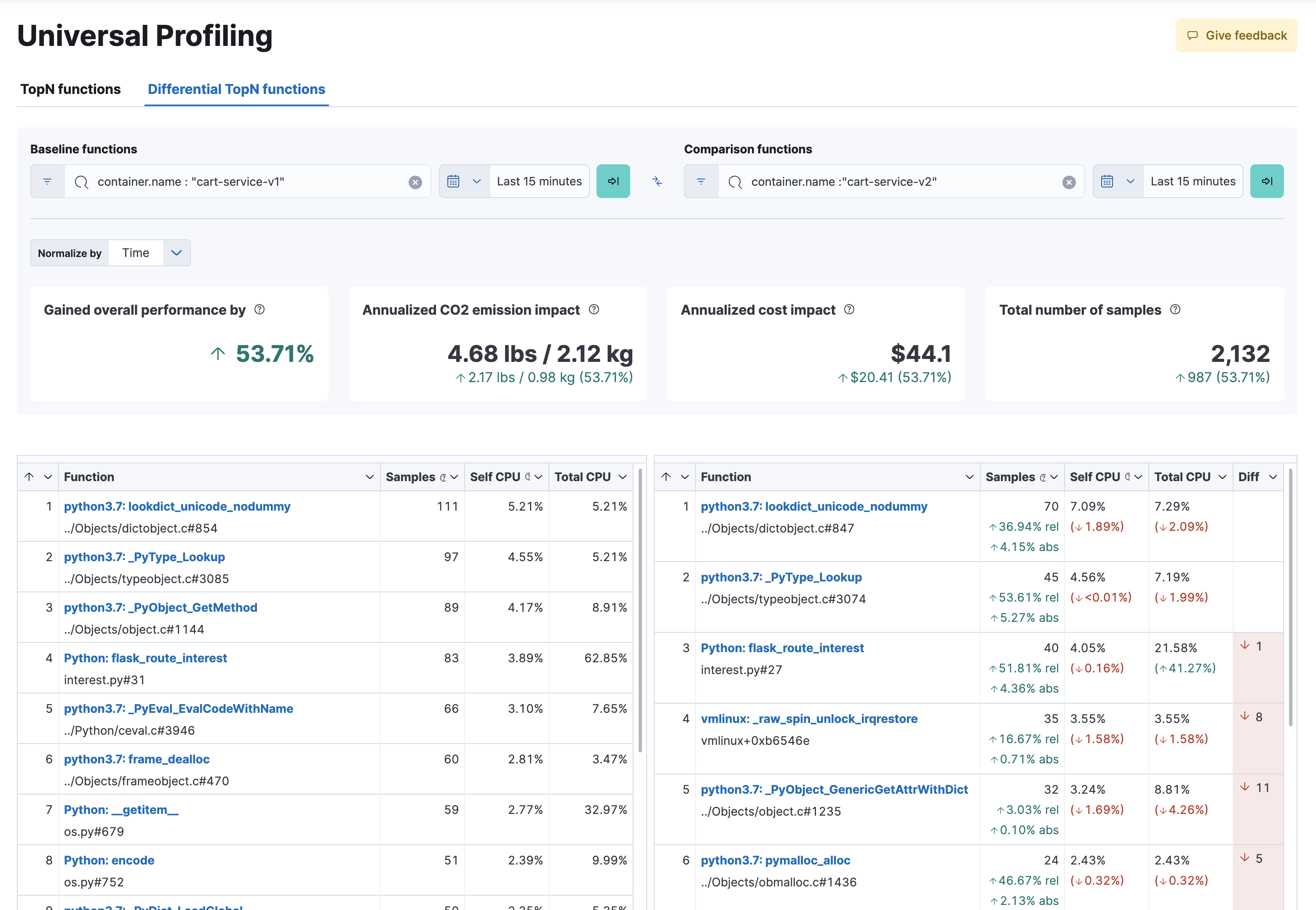
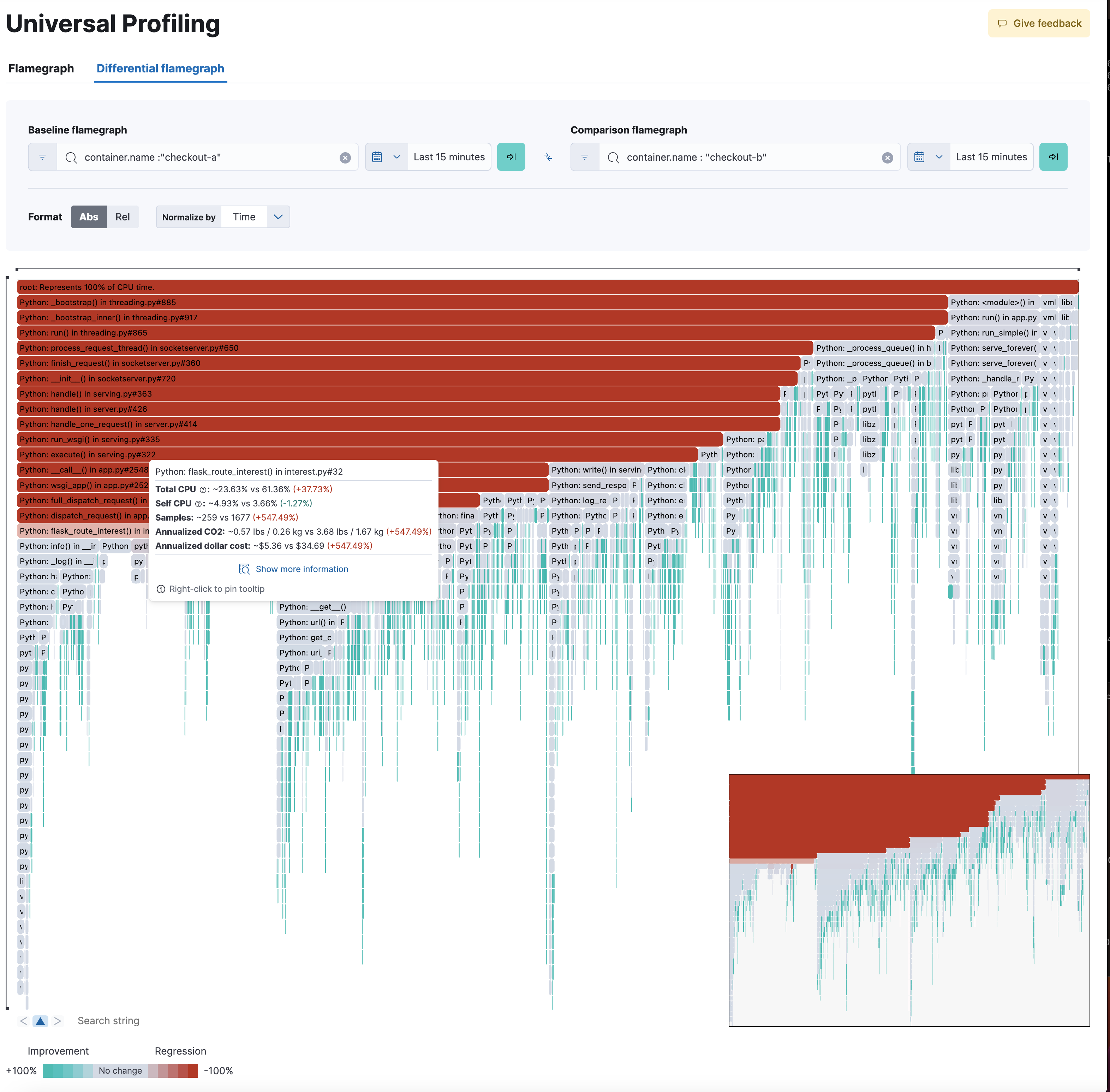
编辑可以将火焰图和函数视图转换为差异视图,比较两个不同时间范围或跨多个维度的数据。
从顶部的选项卡切换到差异火焰图或差异 TopN 函数时,您会看到两个单独的搜索栏和日期时间选择器。最左侧的筛选器表示您想要用作比较基线的数据,而最右侧的筛选器表示将与基线进行比较的数据。
在每个数据筛选器上点击刷新会触发频率比较,突出显示 CPU 使用率的变化。
在差异函数中,函数的最右侧列具有绿色或橙色的分数计算器,表示作为最重的 CPU 命中函数的相对位置差异。
在差异火焰图中,与基线的差异用颜色和色调突出显示。鲜艳的绿色矩形表示与基线相比,在较少的样本中看到了帧,这意味着有所改进。鲜艳的红色矩形表示在 CPU 上记录的更多样本中看到了帧,这表明存在潜在的性能回归。
资源约束
编辑通用分析的关键目标之一是为用户带来净正成本效益:分析和观察应用程序的成本不应高于优化产生的节省。
本着这种精神,主机代理和存储都经过精心设计,以尽可能少地使用资源。
Elasticsearch 存储
编辑通用分析存储预算在每个分析核心的基础上是可预测的。我们以 20 Hz 的固定采样频率生成的数据将以每天每个核心约 40 MB 的速率存储在 Elasticsearch 中。
主机代理 CPU 和内存
编辑由于通用分析提供全系统持续分析,主机代理的资源使用情况与机器上运行的进程数量高度相关。
我们记录了实际生产环境中主机代理的部署情况,其 CPU 时间消耗在 0.5% 到 1% 之间,进程内存消耗在较空闲的主机上低至 50 MB,而在较繁忙的主机上高达 250 MB。