- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
检测异常数据类别
编辑检测异常数据类别
编辑分类是一种机器学习过程,它将文本字段标记化,将相似的数据聚类在一起,并将其分类。它最适用于机器编写的消息和应用程序输出,这些消息和输出通常由重复元素组成。分类任务使您能够发现分类数据中的异常行为。分类不是自然语言处理(NLP)。当您创建分类异常检测任务时,机器学习模型会学习每个类别随时间的正常数量和模式。然后,您可以使用计数或罕见函数来检测异常并发现罕见事件或不寻常类型的消息。分类在有限的消息集上效果良好,例如
{"@timestamp":1549596476000, "message":"org.jdbi.v2.exceptions.UnableToExecuteStatementException: com.mysql.jdbc.exceptions.MySQLTimeoutException: Statement cancelled due to timeout or client request [statement:\"SELECT id, customer_id, name, force_disabled, enabled FROM customers\"]", "type":"logs"}
建议
编辑- 分类经过调整,可以通过考虑标记顺序(包括停用词)并且不在分析中考虑同义词来最好地处理日志消息之类的数据。将机器编写的消息用于分类分析。
- 人类交流或文学文本中的完整句子(例如电子邮件、维基页面、散文或其他人类生成的内容)在结构上可能非常多样化。由于分类是为机器数据调整的,因此它对人类生成的数据产生较差的结果。它会创建太多类别,以至于无法有效地处理它们。避免将人类生成的数据用于分类分析。
创建分类任务
编辑- 在 Kibana 中,导航到机器学习 > 异常检测 > 任务。
- 单击创建异常检测任务,选择您要分析的{data-view}。
- 从列表中选择分类向导。
-
选择一个分类检测器 - 在此示例中为
count函数 - 以及您要分类的字段 - 在此示例中为message字段。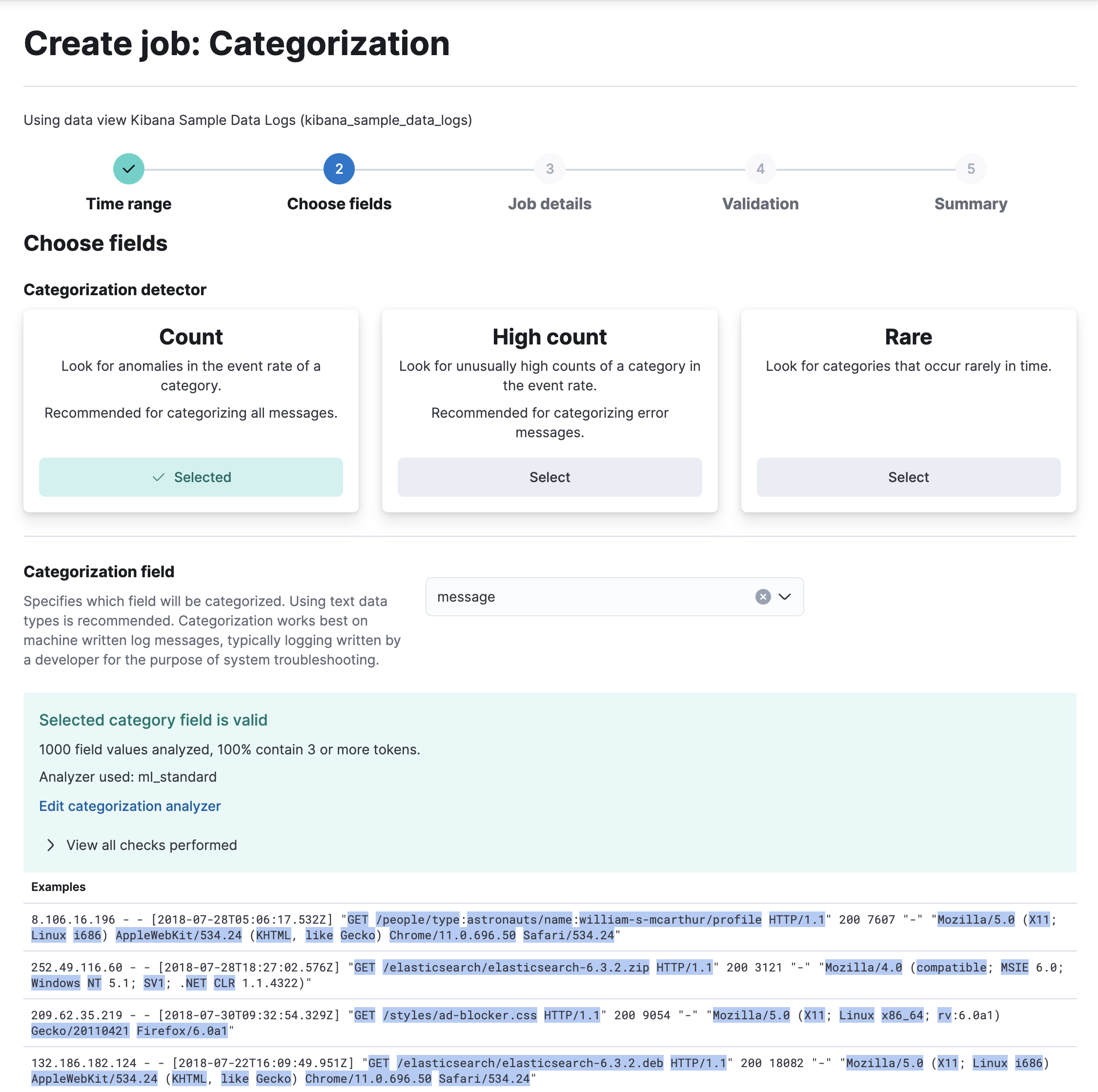
- 单击下一步。
- 提供任务 ID 并单击下一步。
- 如果验证成功,请单击下一步以查看任务创建的摘要。
- 单击创建任务。
此示例任务从 message 字段的内容生成类别,并使用 count 函数来确定某些类别何时以异常速率发生。
API 示例
查看任务结果
编辑使用 Kibana 中的异常资源管理器查看分析结果
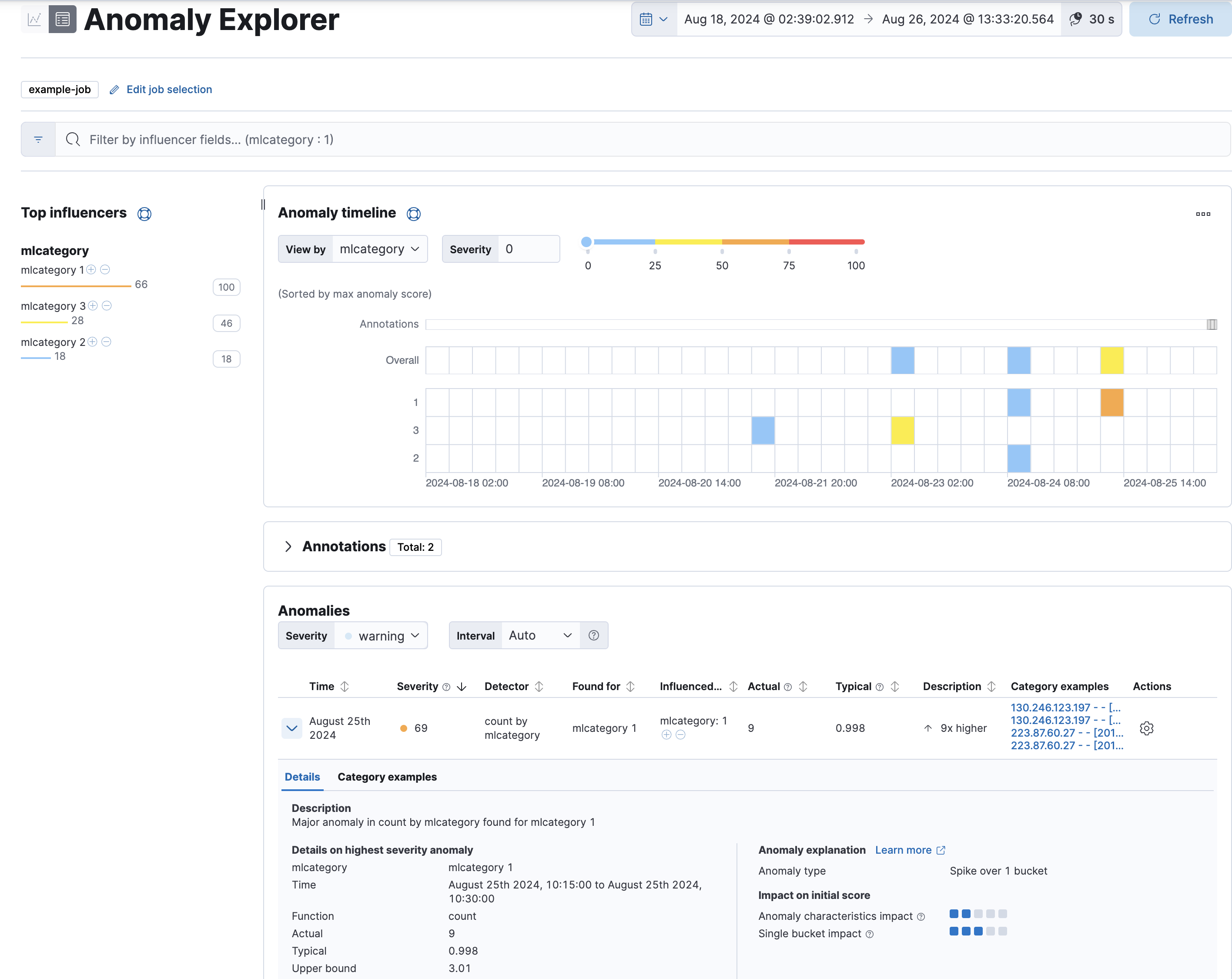
对于此类任务,结果包含每个异常的额外信息:类别的名称(例如,mlcategory 2)和该类别中消息的示例。您可以使用这些详细信息来调查消息计数异常高的出现次数。
高级配置选项
编辑如果您在 Kibana 中使用高级异常检测任务向导或 创建异常检测任务 API,则还有其他配置选项。例如,可选的 categorization_examples_limit 属性指定每个类别存储在内存和结果数据存储中的最大示例数。默认值为 4。请注意,此设置不影响分类;它只影响可见示例的列表。如果增加此值,则会有更多示例可用,但您必须有更多可用的存储空间。如果将此值设置为 0,则不存储任何示例。
另一个高级选项是 categorization_filters 属性,该属性可以包含正则表达式数组。如果分类字段值与正则表达式匹配,则在定义类别时不会考虑匹配的字段部分。分类过滤器按其在任务配置中列出的顺序应用,这使您能够忽略分类字段值的多个部分。在此示例中,您可以创建一个类似 [ "\\[statement:.*\\]"] 的过滤器,以从分类算法中删除 SQL 语句。
按分区分类
编辑如果您启用按分区分类,则将为每个分区单独确定类别。例如,如果您的数据包含来自不同应用程序的多种日志类型的消息,则可以使用类似 ECS event.dataset 字段的字段作为 partition_field_name,并单独对每种日志类型的消息进行分类。
如果您的任务有多个检测器,则每个使用 mlcategory 关键字的检测器还必须定义 partition_field_name。您必须在所有这些检测器中使用相同的 partition_field_name 值。否则,当您创建或更新任务并启用按分区分类时,该任务将失败。
启用按分区分类后,您还可以利用 stop_on_warn 配置选项。如果分区的分类状态更改为 warn,则其分类效果不佳,并可能导致不必要的资源使用。当您将 stop_on_warn 设置为 true 时,任务将停止分析这些有问题的分区。因此,您可以避免对不适合分类的分区产生持续的性能成本。
自定义分类分析器
编辑分类使用英语词典单词来识别日志消息类别。默认情况下,它还使用英语标记化规则。因此,如果您使用默认的分类分析器,则仅支持英语日志消息,如限制中所述。
如果您在 Kibana 中使用分类向导,则可以查看它使用哪个分类分析器,并突出显示它识别的标记示例。您还可以通过自定义解释分类字段值的方式来更改标记化规则
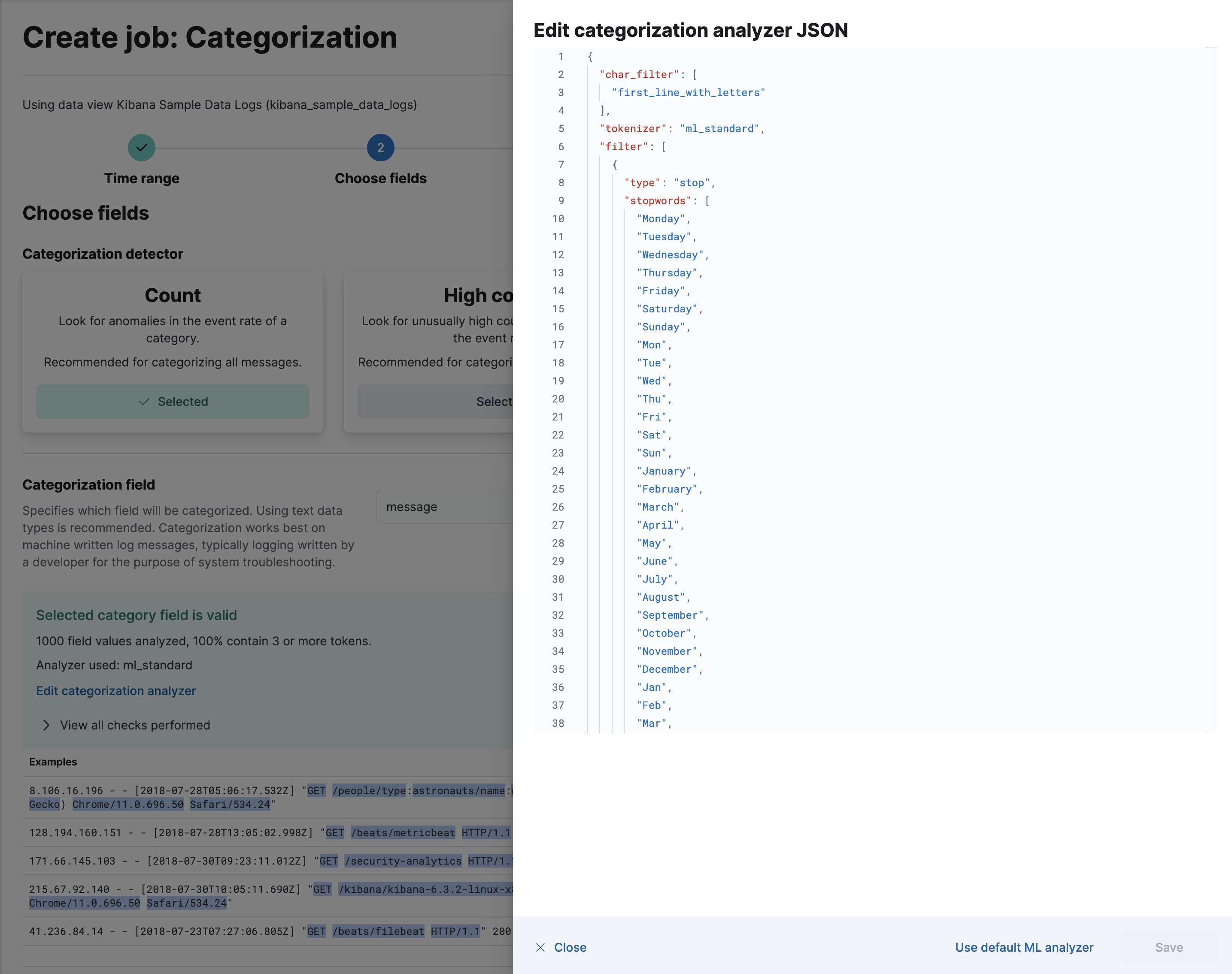
分类分析器可以引用内置的 Elasticsearch 分析器,也可以引用零个或多个字符过滤器、标记器和零个或多个标记过滤器的组合。在此示例中,添加一个 pattern_replace 字符过滤器 可以实现与之前描述的 categorization_filters 任务配置选项相同的行为。有关这些属性的更多详细信息,请参阅 categorization_analyzer API 对象。
如果您在 Kibana 中使用默认分类分析器或从 API 中省略 categorization_analyzer 属性,则将使用以下默认值
POST _ml/anomaly_detectors/_validate { "analysis_config" : { "categorization_analyzer" : { "char_filter" : [ "first_line_with_letters" ], "tokenizer" : "ml_standard", "filter" : [ { "type" : "stop", "stopwords": [ "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun", "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December", "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec", "GMT", "UTC" ] } ] }, "categorization_field_name": "message", "detectors" :[{ "function":"count", "by_field_name": "mlcategory" }] }, "data_description" : { } }
但是,如果您指定 categorization_analyzer 的任何部分,则任何省略的子属性都不会设置为默认值。
ml_standard 标记器以及日和月停用词过滤器几乎等效于以下分析器,该分析器仅使用内置的 Elasticsearch 标记器 和 标记过滤器 定义
PUT _ml/anomaly_detectors/it_ops_new_logs { "description" : "IT Ops Application Logs", "analysis_config" : { "categorization_field_name": "message", "bucket_span":"30m", "detectors" :[{ "function":"count", "by_field_name": "mlcategory", "detector_description": "Unusual message counts" }], "categorization_analyzer":{ "char_filter" : [ "first_line_with_letters" ], "tokenizer": { "type" : "simple_pattern_split", "pattern" : "[^-0-9A-Za-z_./]+" }, "filter": [ { "type" : "pattern_replace", "pattern": "^[0-9].*" }, { "type" : "pattern_replace", "pattern": "^[-0-9A-Fa-f.]+$" }, { "type" : "pattern_replace", "pattern": "^[^0-9A-Za-z]+" }, { "type" : "pattern_replace", "pattern": "[^0-9A-Za-z]+$" }, { "type" : "stop", "stopwords": [ "", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun", "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December", "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec", "GMT", "UTC" ] } ] } }, "analysis_limits":{ "categorization_examples_limit": 5 }, "data_description" : { "time_field":"time", "time_format": "epoch_ms" } }
|
仅考虑消息中包含字母的第一行以进行分类。 |
|
|
标记由连字符、数字、字母、下划线、点和斜杠组成。 |
|
|
默认情况下,分类会忽略以数字开头的标记。 |
|
|
默认情况下,分类会忽略十六进制数字的标记。 |
|
|
下划线、连字符和点将从标记的开头删除。 |
|
|
下划线、连字符和点也将从标记的末尾删除。 |
默认 categorization_analyzer 与此示例分析器之间的关键区别在于,使用 ml_standard 标记器的速度快了好几倍。ml_standard 标记器还尝试将 URL、Windows 路径和电子邮件地址保留为单个标记。行为上的另一个区别是,自定义分析器不包含标记中的重音字母,而 ml_standard 标记器包含重音字母。可以通过使用更复杂的正则表达式来修复此问题。
如果您使用空格分隔单词的语言对非英语消息进行分类,则如果将停用标记过滤器中的日或月单词更改为您的语言中相应的单词,则可能会获得更好的结果。如果您使用单词不以空格分隔的语言对消息进行分类,则还必须使用其他标记器,才能获得合理的分类结果。
必须注意,分析机器生成的日志消息的分类与标记化以进行搜索略有不同。对搜索效果良好的功能(例如词干提取、同义词替换和小写)可能会使分类结果变得更糟。但是,要从机器学习结果中深入研究以正确工作,分类分析器生成的标记必须与搜索分析器生成的标记相似。如果它们足够相似,则当您搜索分类分析器生成的标记时,您会找到分类字段值来自的原始文档。