- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
数据框分析特征处理器
编辑数据框分析特征处理器
编辑数据框分析自动包含一个特征编码阶段,该阶段将类别特征转换为数值特征。但是,如果您想更好地控制用于特定字段的编码方法,则可以定义特征处理器。如果在处理器运行后仍然存在任何类别特征,它们将在自动特征编码阶段进行处理。
您定义的特征处理器是分析过程的一部分,当数据通过聚合或管道时,处理器会针对新数据运行。生成的特征是临时的;它们不会存储在索引中。这提供了一种机制来创建可在搜索和摄取时使用的特征,并且不会占用索引中的空间。
请参阅创建数据框分析作业 API的feature_processors属性以了解更多信息。
可用的特征处理器
频率编码
编辑频率编码考虑给定类别特征相对于编码字段的值出现的次数。特征出现的频率越高,该特征在数据集中的权重就越大。使用这种编码技术,在编码完成后无法回到类别值,因为不同的类别可能具有相同的频率。
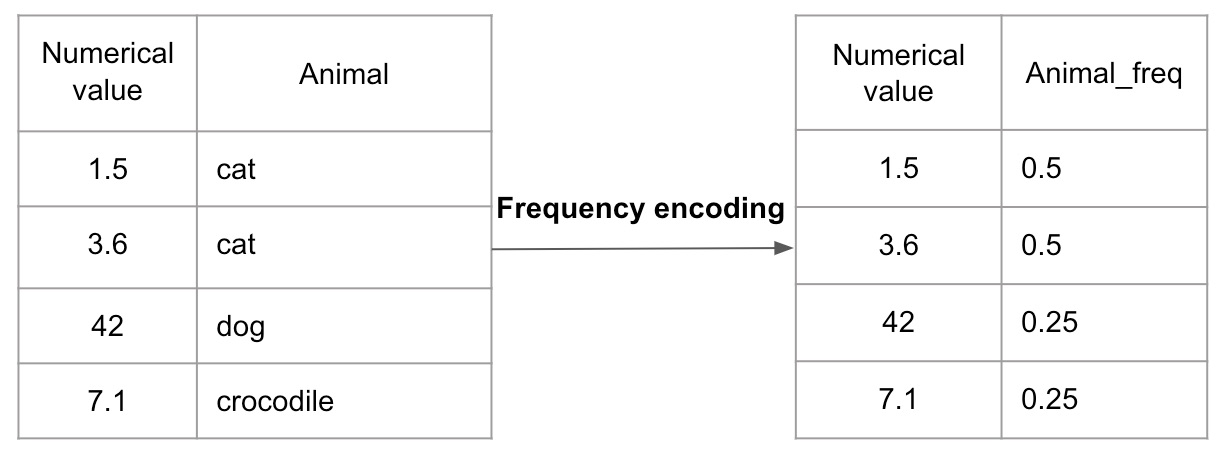
该图显示了一个简单的频率编码示例。 cat的 Animal_freq 值为 0.5,因为该特征出现在一半的相关值中。dog和crocodile标签各自只出现一次。因此,这些标签的 Animal_freq 值为 0.25。
多重编码
编辑多重编码使您可以在同一数据框分析作业中使用多个处理器。您可以定义一个有序的处理器序列,其中一个处理器的输出可以作为输入转发到下一个处理器。例如,您可以定义一个 n-gram 特征处理器,该处理器创建一系列 n-gram,这些 n-gram 可以由链式独热编码处理器进行编码。
n-gram 编码
编辑n-gram 编码将字符串编码为配置长度的 n-gram(n 个项目的序列)集合。此编码的输出是分类的。因此,将对生成的 n-gram 进行额外的自动处理。

该表显示了 Animal 字段的 n-gram 编码。它执行 unigram 和 bigram 编码(大小为 1 和 2 的 n-gram),并扩展到字符串长度 3。
独热编码
编辑独热编码通过为每个类别分配向量,将类别值转换为数值值。该向量表示在给定值处是否存在相应的特征(1)或不存在(0),因此编码方法将不同的类别特征映射到数值。
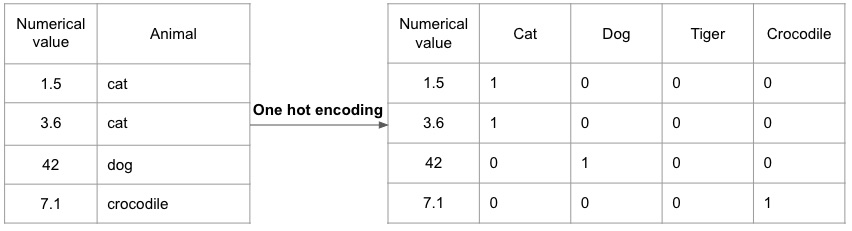
独热编码将每个类别映射到对应的值。如果给定值处存在该类别,则分配的向量为1,如果不存在,则向量为0。
目标均值编码
编辑目标均值编码将类别值替换为目标变量的平均值,因为它与类别变量本身相关。
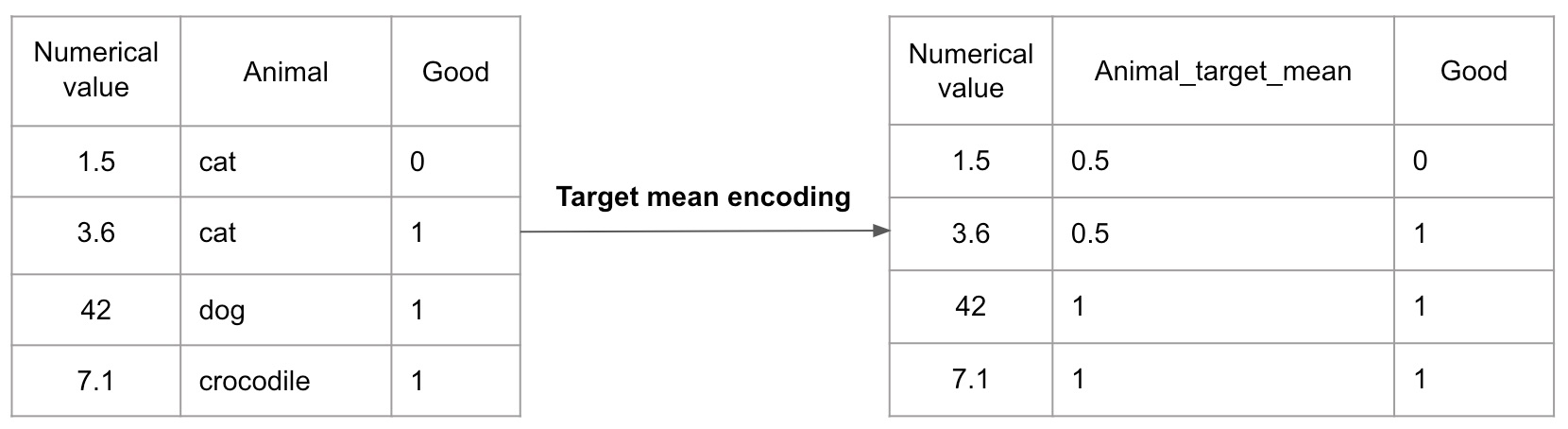
该图显示了一个简单的目标均值编码示例。标签cat在数据集中出现两次。其中一个对应的目标变量为0,另一个对应的目标变量为1。使用目标均值编码处理器后,cat标签的Animal_target_mean值为 0.5,而dog和crocodile的值为 1,因为它们的每次出现都对应着一个目标变量1。