- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
使用运行时字段修改数据馈送中的数据
编辑使用运行时字段修改数据馈送中的数据
编辑如果使用数据馈送,您可以使用运行时字段在分析数据之前修改数据。您可以向数据馈送添加一个可选的 runtime_mappings 属性,您可以在其中指定字段类型和脚本,这些脚本可以评估自定义表达式,而不会影响您从中检索数据的索引。
如果您的数据馈送定义了运行时字段,您可以在异常检测作业中使用这些字段。例如,您可以在一个或多个检测器中的分析函数中使用运行时字段。运行时字段可能会根据运行时脚本中定义的计算影响搜索性能。
其中一些示例使用了正则表达式。默认情况下,正则表达式是被禁用的,因为它们会规避 Painless 针对长时间运行和内存消耗大的脚本提供的保护。有关更多信息,请参阅Painless 脚本语言。
机器学习分析是区分大小写的。例如,“John”被认为与“john”不同。这是您可能考虑使用将字符串转换为大写或小写字母的脚本的原因之一。
以下索引 API 创建内容并将其添加到后续示例中使用的索引
PUT /my-index-000001 { "mappings":{ "properties": { "@timestamp": { "type": "date" }, "aborted_count": { "type": "long" }, "another_field": { "type": "keyword" }, "clientip": { "type": "keyword" }, "coords": { "properties": { "lat": { "type": "keyword" }, "lon": { "type": "keyword" } } }, "error_count": { "type": "long" }, "query": { "type": "keyword" }, "some_field": { "type": "keyword" }, "tokenstring1":{ "type":"keyword" }, "tokenstring2":{ "type":"keyword" }, "tokenstring3":{ "type":"keyword" } } } } PUT /my-index-000001/_doc/1 { "@timestamp":"2017-03-23T13:00:00", "error_count":36320, "aborted_count":4156, "some_field":"JOE", "another_field":"SMITH ", "tokenstring1":"foo-bar-baz", "tokenstring2":"foo bar baz", "tokenstring3":"foo-bar-19", "query":"www.ml.elastic.co", "clientip":"123.456.78.900", "coords": { "lat" : 41.44, "lon":90.5 } }
|
在此示例中,字符串字段被映射为 |
PUT _ml/anomaly_detectors/test1 { "analysis_config":{ "bucket_span": "10m", "detectors":[ { "function":"mean", "field_name": "total_error_count" } ] }, "data_description": { "time_field":"@timestamp" }, "datafeed_config":{ "datafeed_id": "datafeed-test1", "indices": ["my-index-000001"], "runtime_mappings": { "total_error_count": { "type": "long", "script": { "source": "emit(doc['error_count'].value + doc['aborted_count'].value)" } } } } }
此 test1 异常检测作业包含一个检测器,该检测器在平均值分析函数中使用运行时字段。datafeed-test1 数据馈送定义了运行时字段。它包含一个脚本,该脚本将文档中的两个字段相加,以生成“总”错误计数。
runtime_mappings 属性的语法与 Elasticsearch 使用的语法相同。有关更多信息,请参阅运行时字段。
您可以使用以下 API 预览数据馈送的内容
GET _ml/datafeeds/datafeed-test1/_preview
在此示例中,API 返回以下结果,其中包含 error_count 和 aborted_count 值的总和
[ { "@timestamp": 1490274000000, "total_error_count": 40476 } ]
此示例演示了如何使用运行时字段,但它包含的数据不足以生成有意义的结果。
您也可以使用 Kibana 创建使用运行时字段的高级异常检测作业。要将 runtime_mappings 属性添加到您的数据馈送,您必须使用编辑 JSON选项卡。例如
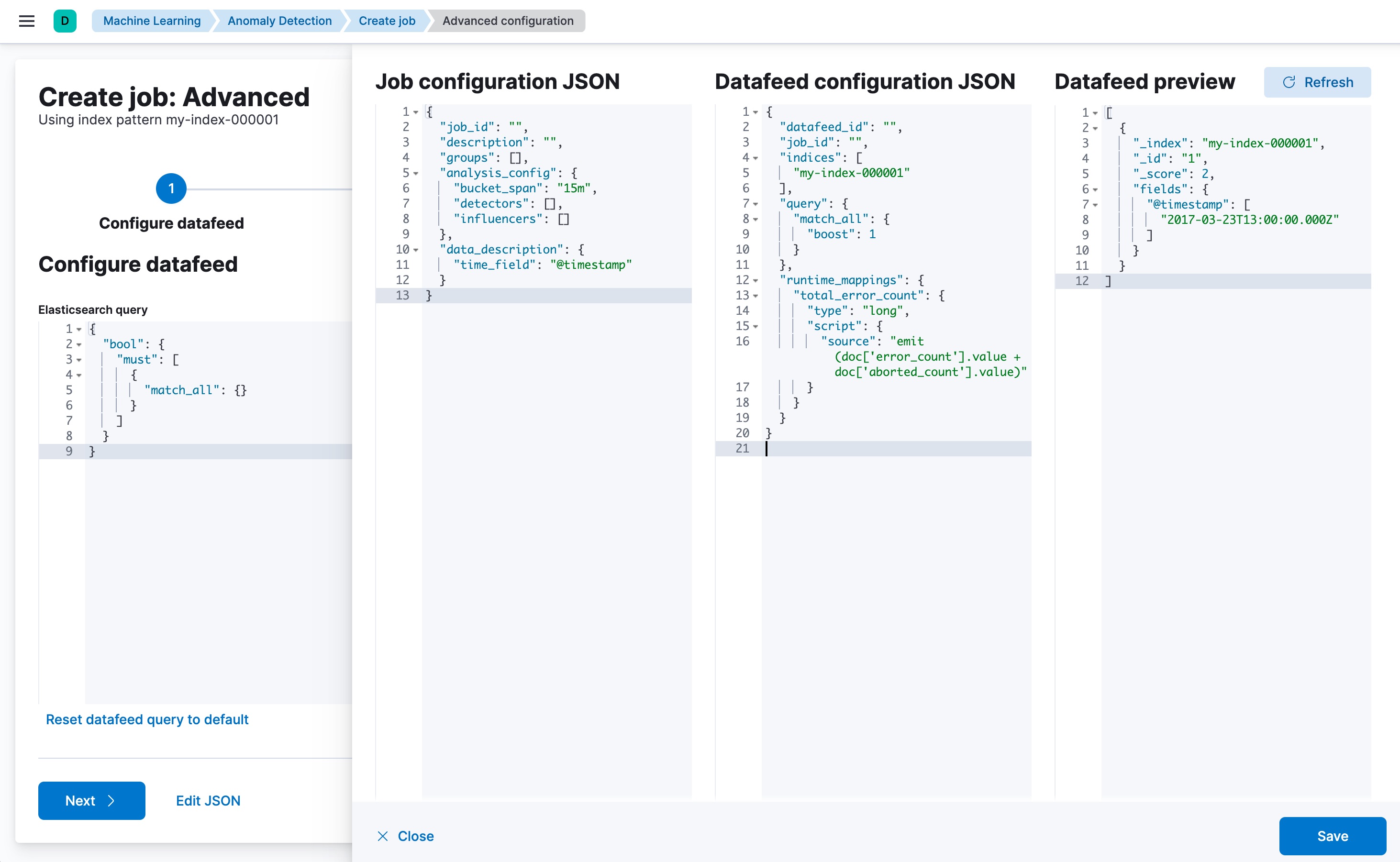
PUT _ml/anomaly_detectors/test2 { "analysis_config":{ "bucket_span": "10m", "detectors":[ { "function":"low_info_content", "field_name":"my_runtime_field" } ] }, "data_description": { "time_field":"@timestamp" }, "datafeed_config":{ "datafeed_id": "datafeed-test2", "indices": ["my-index-000001"], "runtime_mappings": { "my_runtime_field": { "type": "keyword", "script": { "source": "emit(doc['some_field'].value + '_' + doc['another_field'].value)" } } } } } GET _ml/datafeeds/datafeed-test2/_preview
预览数据馈送 API 返回以下结果,显示“JOE”和“SMITH”已连接并添加了下划线
[ { "@timestamp": 1490274000000, "my_runtime_field": "JOE_SMITH " } ]
POST _ml/datafeeds/datafeed-test2/_update { "runtime_mappings": { "my_runtime_field": { "type": "keyword", "script": { "source": "emit(doc['another_field'].value.trim())" } } } } GET _ml/datafeeds/datafeed-test2/_preview
预览数据馈送 API 返回以下结果,显示“SMITH”已被修剪为“SMITH”
[ { "@timestamp": 1490274000000, "my_script_field": "SMITH" } ]
POST _ml/datafeeds/datafeed-test2/_update { "runtime_mappings": { "my_runtime_field": { "type": "keyword", "script": { "source": "emit(doc['some_field'].value.toLowerCase())" } } } } GET _ml/datafeeds/datafeed-test2/_preview
预览数据馈送 API 返回以下结果,显示“JOE”已转换为“joe”
[ { "@timestamp": 1490274000000, "my_script_field": "joe" } ]
POST _ml/datafeeds/datafeed-test2/_update { "runtime_mappings": { "my_runtime_field": { "type": "keyword", "script": { "source": "emit(doc['some_field'].value.substring(0, 1).toUpperCase() + doc['some_field'].value.substring(1).toLowerCase())" } } } } GET _ml/datafeeds/datafeed-test2/_preview
预览数据馈送 API 返回以下结果,显示“JOE”已转换为“Joe”
[ { "@timestamp": 1490274000000, "my_script_field": "Joe" } ]
POST _ml/datafeeds/datafeed-test2/_update { "runtime_mappings": { "my_runtime_field": { "type": "keyword", "script": { "source": "emit(/\\s/.matcher(doc['tokenstring2'].value).replaceAll('_'))" } } } } GET _ml/datafeeds/datafeed-test2/_preview
预览数据馈送 API 返回以下结果,显示“foo bar baz”已转换为“foo_bar_baz”
[ { "@timestamp": 1490274000000, "my_script_field": "foo_bar_baz" } ]
POST _ml/datafeeds/datafeed-test2/_update { "runtime_mappings": { "my_runtime_field": { "type": "keyword", "script": { "source": "def m = /(.*)-bar-([0-9][0-9])/.matcher(doc['tokenstring3'].value); emit(m.find() ? m.group(1) + '_' + m.group(2) : '');" } } } } GET _ml/datafeeds/datafeed-test2/_preview
预览数据馈送 API 返回以下结果,显示“foo-bar-19”已转换为“foo_19”
[ { "@timestamp": 1490274000000, "my_script_field": "foo_19" } ]
PUT _ml/anomaly_detectors/test3 { "analysis_config":{ "bucket_span": "10m", "detectors":[ { "function":"lat_long", "field_name": "my_coordinates" } ] }, "data_description": { "time_field":"@timestamp" }, "datafeed_config":{ "datafeed_id": "datafeed-test3", "indices": ["my-index-000001"], "runtime_mappings": { "my_coordinates": { "type": "keyword", "script": { "source": "emit(doc['coords.lat'].value + ',' + doc['coords.lon'].value)" } } } } } GET _ml/datafeeds/datafeed-test3/_preview
在 Elasticsearch 中,位置数据可以存储在 geo_point 字段中,但机器学习分析本身不支持这种数据类型。这个运行时字段的示例将数据转换为适当的格式。有关更多信息,请参阅附录 K,地理函数。
预览数据馈送 API 返回以下结果,显示 41.44 和 90.5 已合并为“41.44,90.5”
[ { "@timestamp": 1490274000000, "my_coordinates": "41.44,90.5" } ]