- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
将 NLP 推理添加到摄取管道
编辑将 NLP 推理添加到摄取管道
编辑在您在集群中部署训练模型后,您可以使用它在摄取管道中执行自然语言处理任务。
- 验证是否满足所有摄取管道先决条件。
- 将推理处理器添加到摄取管道.
- 摄取文档.
- 查看结果.
将推理处理器添加到摄取管道
编辑在 Kibana 中,您可以在堆栈管理 > 摄取管道中创建和编辑管道。
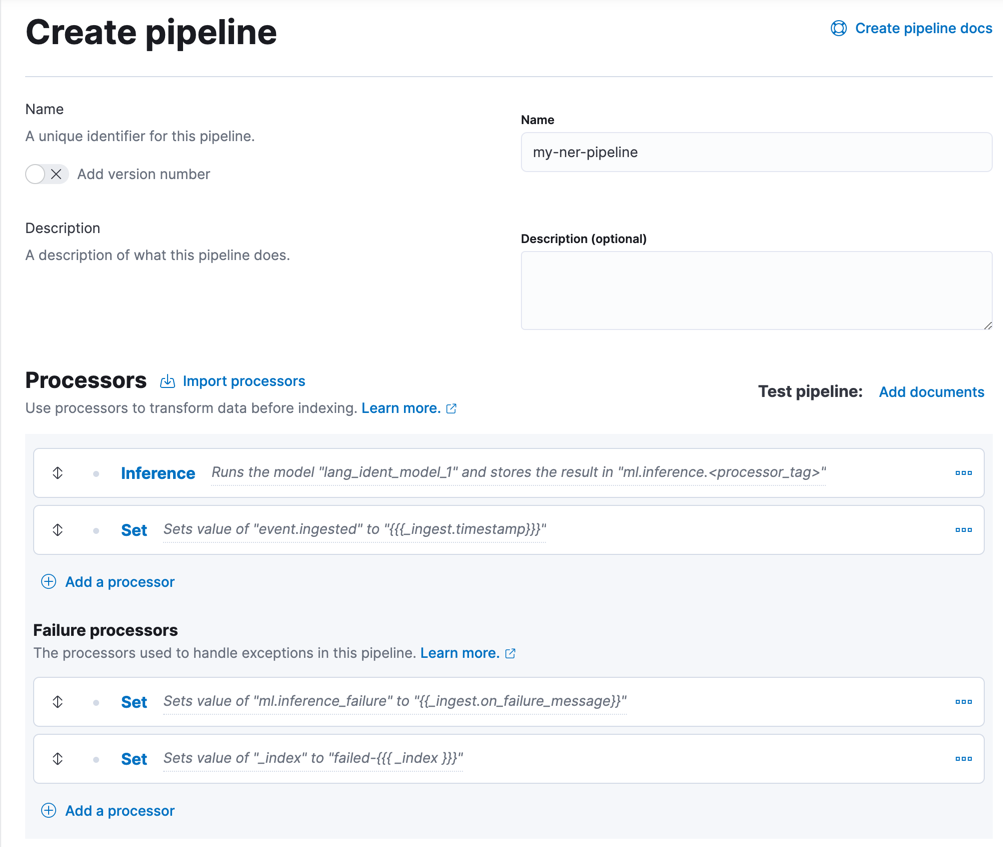
- 单击创建管道或编辑现有管道。
-
将推理处理器添加到您的管道
- 单击添加处理器并选择推理处理器类型。
- 将模型 ID设置为您的训练模型的名称,例如
elastic__distilbert-base-cased-finetuned-conll03-english或lang_ident_model_1。 -
如果您使用集群中提供的语言识别模型 (
lang_ident_model_1)-
输入字段名称默认为
text。如果您想在具有不同名称的字段中识别语言,您必须在字段映射部分将您的字段名称映射到text。例如{ "message": "text" }
-
您还可以选择在推理配置部分添加分类配置选项。例如,要包括前五个语言预测
{ "classification":{ "num_top_classes":5 } }
-
- 单击添加以保存处理器。
-
可选:添加设置处理器以索引摄取时间戳。
- 单击添加处理器并选择设置处理器类型。
- 为该字段选择一个名称(例如
event.ingested)并将其值设置为{{{_ingest.timestamp}}}。有关更多详细信息,请参阅在处理器中访问摄取元数据。 - 单击添加以保存处理器。
-
可选:添加故障处理器来处理异常。例如,在故障处理器部分
- 添加一个设置处理器来捕获管道错误消息。为该字段选择一个名称(例如
ml.inference_failure)并将其值设置为{{_ingest.on_failure_message}}文档元数据字段。 - 添加一个设置处理器,将有问题的文档重新路由到不同的索引以进行故障排除。使用
_index元数据字段并将其值设置为新名称(例如failed-{{{ _index }}})。有关更多详细信息,请参阅处理管道故障。
- 添加一个设置处理器来捕获管道错误消息。为该字段选择一个名称(例如
-
要测试管道,请单击添加文档。
-
在文档选项卡中,提供用于测试的示例文档。
例如,要测试执行命名实体识别 (NER) 的训练模型
[ { "_source": { "text_field":"Hello, my name is Josh and I live in Berlin." } } ]
要测试执行语言识别的训练模型
[ { "_source":{ "message":"Sziasztok! Ez egy rövid magyar szöveg. Nézzük, vajon sikerül-e azonosítania a language identification funkciónak? Annak ellenére is sikerülni fog, hogy a szöveg két angol szót is tartalmaz." } } ]
-
单击运行管道并验证管道是否按预期工作。
在语言识别示例中,预测值是概率最高的语言的 ISO 标识符。在这种情况下,匈牙利语应为
hu。 - 如果一切看起来都正确,请关闭面板,然后单击创建管道。该管道现在可以使用了。
-
摄取文档
编辑您现在可以使用您的摄取管道对您的数据执行 NLP 任务。
在添加数据之前,请考虑要使用哪些映射。例如,您可以使用开发工具 > 控制台中的 create index API 创建显式映射
PUT ner-test { "mappings": { "properties": { "ml.inference.predicted_value": {"type": "annotated_text"}, "ml.inference.model_id": {"type": "keyword"}, "text_field": {"type": "text"}, "event.ingested": {"type": "date"} } } }
要在此示例中使用 annotated_text 数据类型,您必须安装mapper annotated text 插件。有关更多安装详细信息,请参阅添加 Elasticsearch Service 提供的插件。
然后,您可以使用新的管道索引一些文档。例如,对您的 NER 管道使用带有 pipeline 查询参数的批量索引请求
POST /_bulk?pipeline=my-ner-pipeline {"create":{"_index":"ner-test","_id":"1"}} {"text_field":"Hello, my name is Josh and I live in Berlin."} {"create":{"_index":"ner-test","_id":"2"}} {"text_field":"I work for Elastic which was founded in Amsterdam."} {"create":{"_index":"ner-test","_id":"3"}} {"text_field":"Elastic has headquarters in Mountain View, California."} {"create":{"_index":"ner-test","_id":"4"}} {"text_field":"Elastic's founder, Shay Banon, created Elasticsearch to solve a simple need: finding recipes!"} {"create":{"_index":"ner-test","_id":"5"}} {"text_field":"Elasticsearch is built using Lucene, an open source search library."}
或者,对您的语言识别管道使用带有 pipeline 查询参数的单个索引请求
POST lang-test/_doc?pipeline=my-lang-pipeline { "message": "Mon pays ce n'est pas un pays, c'est l'hiver" }
当您将文档重新索引到新目标时,您还可以使用 NLP 管道。例如,由于示例 Web 日志数据集包含 message 文本字段,您可以使用您的语言识别管道重新索引它
POST _reindex { "source": { "index": "kibana_sample_data_logs", "size": 50 }, "dest": { "index": "lang-test", "pipeline": "my-lang-pipeline" } }
但是,这些 Web 日志消息不太可能包含足够的单词让模型准确识别语言。
将重新索引的 size 选项设置为小于训练模型部署的 queue_capacity 的值。否则,请求可能会被拒绝并显示“请求过多”的 429 错误代码。
查看结果
编辑在验证管道结果之前,您必须创建数据视图。然后,您可以在Discover中浏览您的数据
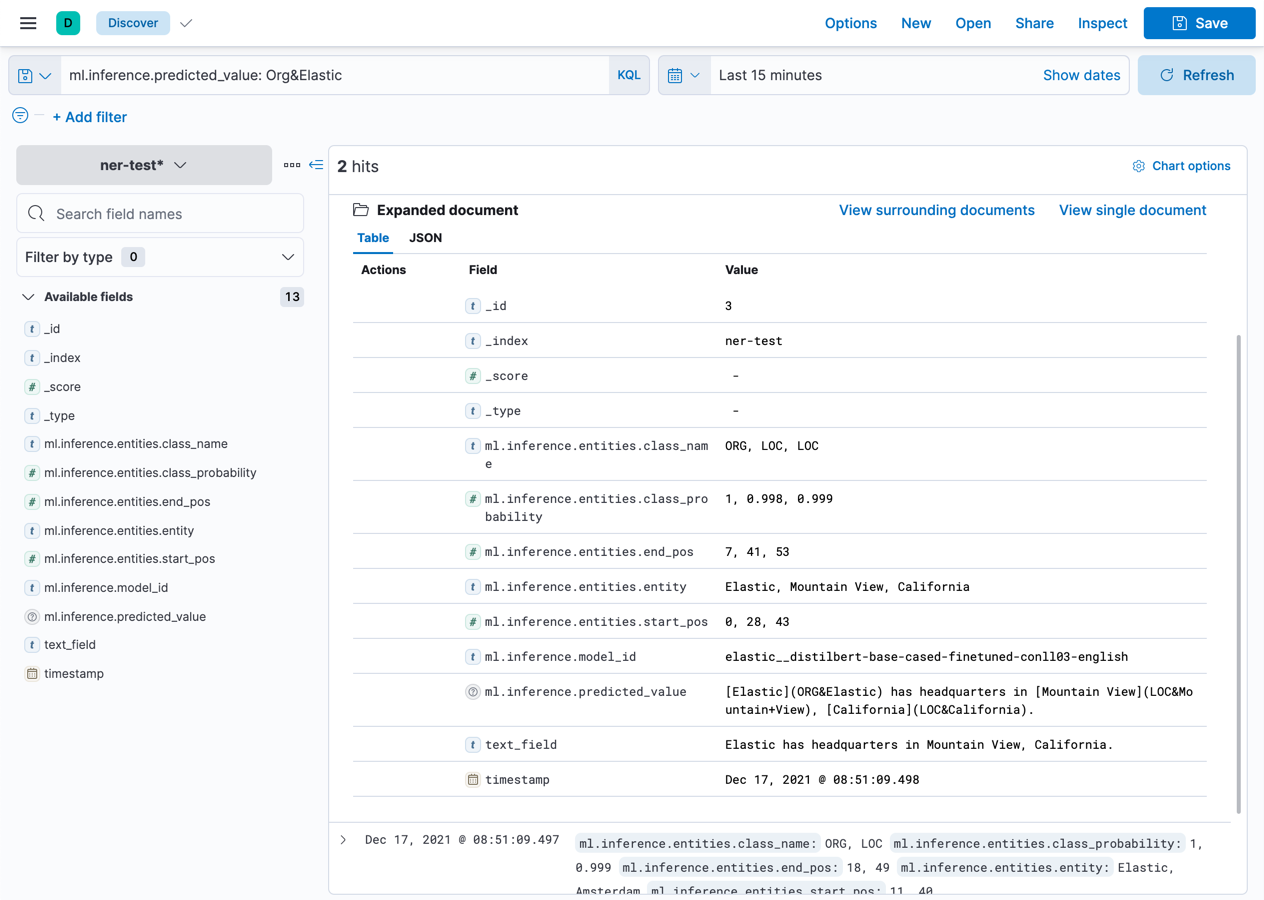
ml.inference.predicted_value 字段包含推理处理器的输出。在这个 NER 示例中,有两个文档包含 Elastic 组织实体。
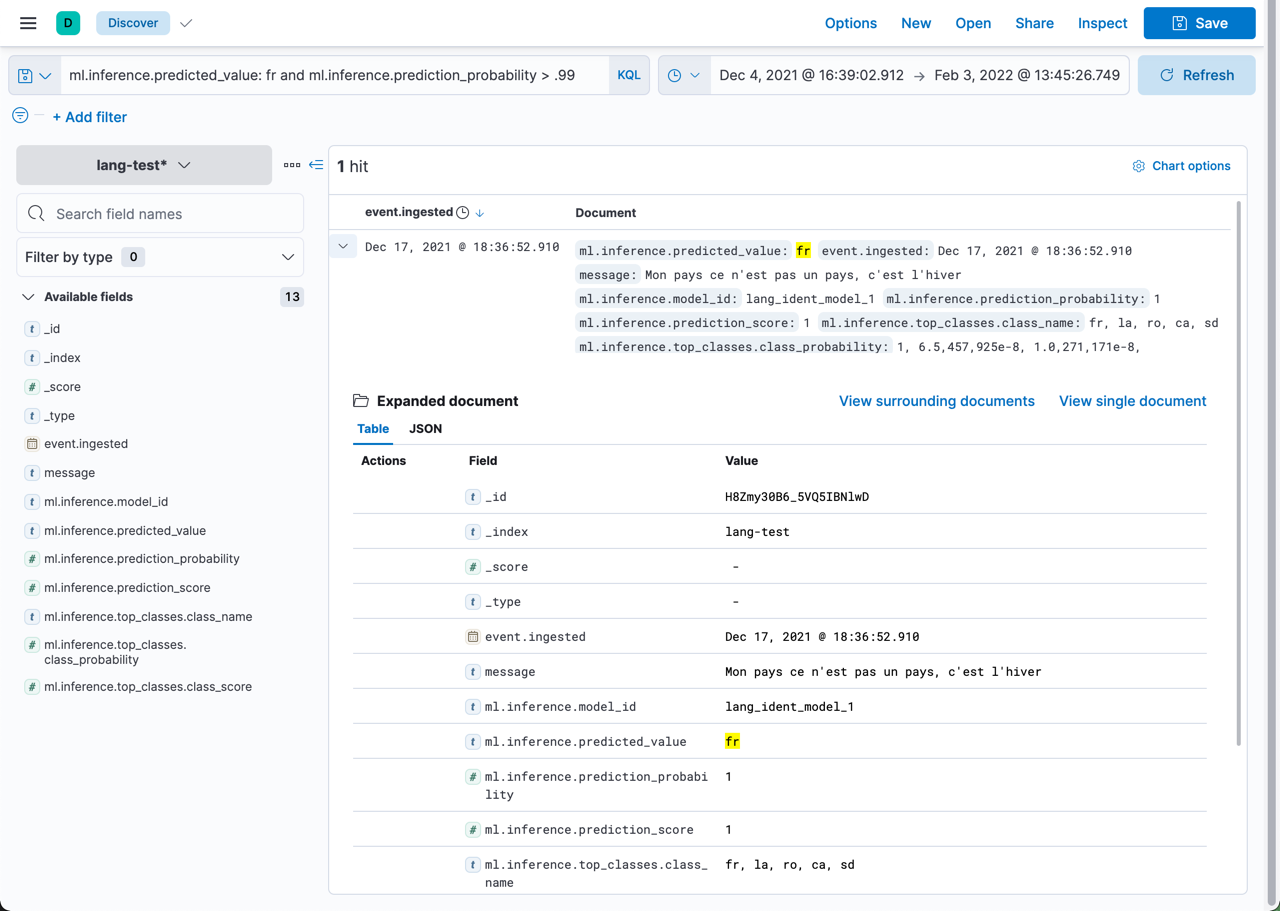
在这个语言识别示例中,ml.inference.predicted_value 包含概率最高的语言的 ISO 标识符,ml.inference.top_classes 字段包含前五种最有可能的语言及其分数
要了解有关摄取管道和您可以添加的所有其他处理器的更多信息,请参阅摄取管道。
常见问题
编辑如果您在摄取管道中使用训练模型时遇到问题,请检查以下可能的原因
- 该训练模型未在您的集群中部署。您可以在机器学习 > 模型管理中查看其状态,或使用获取训练模型统计信息 API。除非您使用内置的
lang_ident_model_1模型,否则您必须确保您的模型已成功部署。请参阅在您的集群中部署模型。 - 您的训练模型预期的默认输入字段名称不在您的源文档中。使用推理处理器中的字段映射选项设置适当的字段名称。
- 请求过多。如果您使用批量摄取,请减少批量请求中的文档数量。如果您正在重新索引,请使用
size参数减少每个批次中处理的文档数量。
通过将故障处理器添加到您的管道,可以捕获这些常见故障场景和其他场景。有关更多示例,请参阅处理管道故障。
进一步阅读
编辑On this page