- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
查找异常值
编辑查找异常值
编辑异常值检测是指识别数据集中与其他值明显不同的数据点。例如,异常值可能是数据集中的错误或异常实体。异常值检测是一种无监督的机器学习技术,不需要提供训练数据。
异常值检测是一种批处理分析,它会对您的数据运行一次。如果有新数据进入索引,您需要对更改后的数据再次进行分析。
异常值检测算法
编辑在 Elastic Stack 中,我们使用四种不同的基于距离和密度的异常值检测方法的集成
- 第 K 个最近邻的距离:计算数据点到其第 K 个最近邻的距离,其中 K 是一个小数字,通常与数据点的总数无关。
- K 个最近邻的距离:计算数据点到其最近邻的平均距离。平均距离最大的点将是最异常的。
- 局部异常因子 (
lof):考虑点到其 K 个最近邻的距离,以及这些邻居到其邻居的距离。 - 基于局部距离的异常因子 (
ldof):是两个度量的比率:第一个计算数据点到其 K 个最近邻的平均距离;第二个计算邻居本身成对距离的平均值。
您无需选择方法或提供任何参数,但您可以根据需要覆盖默认行为。基于距离的方法假设正常数据点的值保持更接近或相似,而异常值则位于远处或值明显不同。这些方法的缺点是它们不考虑数据集的密度变化。基于密度的方法用于缓解此问题。
这四种算法并非总是在哪些点是异常值上达成一致。默认情况下,异常值检测作业使用所有这些方法,然后标准化并组合它们的结果,并为索引中的每个数据点提供一个异常值分数。异常值分数范围为 0 到 1,其中较高的数字表示数据点与索引中的其他数据点相比是异常值的可能性。
特征影响
编辑特征影响 - 在检测异常值时计算的另一个分数 - 提供了不同特征及其对点成为异常值的贡献的相对排名。此分数使您可以了解某个数据点为何是异常值的上下文或原因。
1. 定义问题
编辑Elastic Stack 中的异常值检测可用于检测给定群体中的任何异常实体。例如,检测机器上的恶意软件或网络上的异常用户行为。由于异常值检测基于异常值占整体数据群体的一小部分的假设进行操作,因此您可以在这种情况下使用此功能。异常值检测是一种批处理分析,最适合以实体为中心的索引。如果您的用例基于时间序列数据,您可能需要改用异常检测。
机器学习功能提供无监督的异常值检测,这意味着无需提供训练数据集。
2. 设置环境
编辑在您可以使用 Elastic Stack 机器学习功能之前,需要解决一些配置要求(例如安全特权)。请参阅设置和安全。
3. 准备和转换数据
编辑异常值检测需要特定结构的源数据:二维表格数据结构。因此,您可能需要转换您的数据以创建可用作异常值检测源的数据帧。
您可以在本节中找到如何将数据转换为以实体为中心的索引的示例。
4. 创建作业
编辑数据帧分析作业包含执行分析任务所需的配置信息和元数据。您可以通过 Kibana 或使用 创建数据帧分析作业 API 来创建数据帧分析作业。选择异常值检测作为数据帧分析作业执行的分析类型。您还可以在创建作业时决定是否将字段包含在分析中或从中排除。
您可以在数据帧分析向导中查看可选字段的统计信息。在弹出窗口中显示的字段统计信息提供了更有意义的上下文,以帮助您选择相关字段。
5. 启动作业
编辑您可以通过 Kibana 或使用 启动数据帧分析作业 API 来启动作业。异常值检测作业有四个阶段
-
重新索引:文档从源索引复制到目标索引。 -
加载数据:作业从目标索引中提取必要的数据。 -
计算异常值:作业识别数据中的异常值。 -
写入结果:作业将结果与目标索引中的数据行匹配、合并它们,然后将其索引回目标索引。
在最后一个阶段完成后,作业停止,结果可以进行评估。
与其他的其他数据帧分析作业不同,异常值检测作业在其生命周期中只运行一次。如果您想再次运行分析,则需要创建一个新作业。
6. 评估结果
编辑使用数据帧分析功能从数据集中获取见解是一个迭代过程。在您定义了要解决的问题,并选择了可以帮助您解决问题的分析类型后,您需要生成高质量的数据集并创建适当的数据帧分析作业。您可能需要尝试不同的配置、参数和转换数据的方法,然后才能获得满足您用例的结果。此过程的一个有价值的补充是评估数据帧分析 API,它使您可以评估数据帧分析性能。它可以帮助您了解错误分布,并识别数据帧分析模型表现良好或不太可靠的点。
要使用此 API 评估分析,您需要使用一个字段注释包含分析结果的索引,该字段使用实际情况标记每个文档。评估数据帧分析 API 会根据此手动提供的实际情况评估数据帧分析的性能。
异常值检测评估类型提供以下指标来评估模型性能
- 混淆矩阵
- 精度
- 召回率
- 接收者操作特征 (ROC) 曲线。
混淆矩阵
编辑混淆矩阵提供了四个度量,用于衡量数据帧分析在您的数据集上的工作效果
- 真正例 (TP):分析识别为类成员的类成员。
- 真负例 (TN):分析识别为非类成员的非类成员。
- 假正例 (FP):分析错误地识别为类成员的非类成员。
- 假负例 (FN):分析错误地识别为非类成员的类成员。
尽管评估数据帧分析 API 可以从分析结果中计算出混淆矩阵,但这些结果不是二进制值(类成员/非类成员),而是一个介于 0 和 1 之间的数字(在异常值检测的情况下称为异常值分数)。此值捕获数据点成为特定类成员的可能性。这意味着用户可以决定将数据点视为给定类的成员的阈值或截止点。例如,用户可以说异常值分数高于 0.5 的所有数据点都将被视为异常值。
为了考虑这种复杂性,评估数据帧分析 API 返回不同阈值(默认情况下为 0.25、0.5 和 0.75)处的混淆矩阵。
精度和召回率
编辑精度和召回率值将算法性能总结为单个数字,从而更容易比较评估结果。
精度显示被识别为类成员的数据点中有多少实际上是类成员。它是真正例数除以真正例和假正例之和 (TP/(TP+FP))。
召回率显示实际类成员的数据点中有多少被正确识别为类成员。它是真正例数除以真正例和假负例之和 (TP/(TP+FN))。
精度和召回率在不同的阈值级别计算。
接收者操作特征曲线
编辑接收者操作特征 (ROC) 曲线是一个图,它表示二进制分类过程在不同阈值下的性能。它比较不同阈值级别下真正例率与假正例率,从而创建曲线。从该图中,您可以计算曲线下面积 (AUC) 值,这是一个介于 0 和 1 之间的数字。越接近 1,算法性能越好。
评估数据帧分析 API 可以返回不同阈值级别下的假正例率 (fpr) 和真正例率 (tpr),因此您可以使用这些值来可视化算法性能。
检测日志数据集中的异常行为
编辑异常值检测的目标是查找索引中最不寻常的文档。让我们尝试检测 数据日志示例数据集中的异常行为。
-
验证您的环境是否已正确设置为使用机器学习功能。如果启用了 Elasticsearch 安全功能,您需要一个有权创建和管理数据帧分析作业的用户。请参阅设置和安全。
由于我们将创建转换,您还需要
manage_data_frame_transforms集群特权。 -
创建一个转换,该转换生成一个包含要分析的数字或布尔数据的以实体为中心的索引。
在此示例中,我们将使用 Web 日志示例数据并透视数据,以便我们获得一个新索引,其中包含每个客户端 IP 的网络使用情况摘要。
特别是,创建一个转换,计算特定客户端 IP 与网络通信的次数(
@timestamp.value_count),网络与客户端机器之间交换的字节总数(bytes.sum),单次通信期间交换的最大字节数(bytes.max),以及特定客户端 IP 发起的请求总数(request.value_count)。您可以在 Stack Management > Transforms 中创建转换之前预览它。
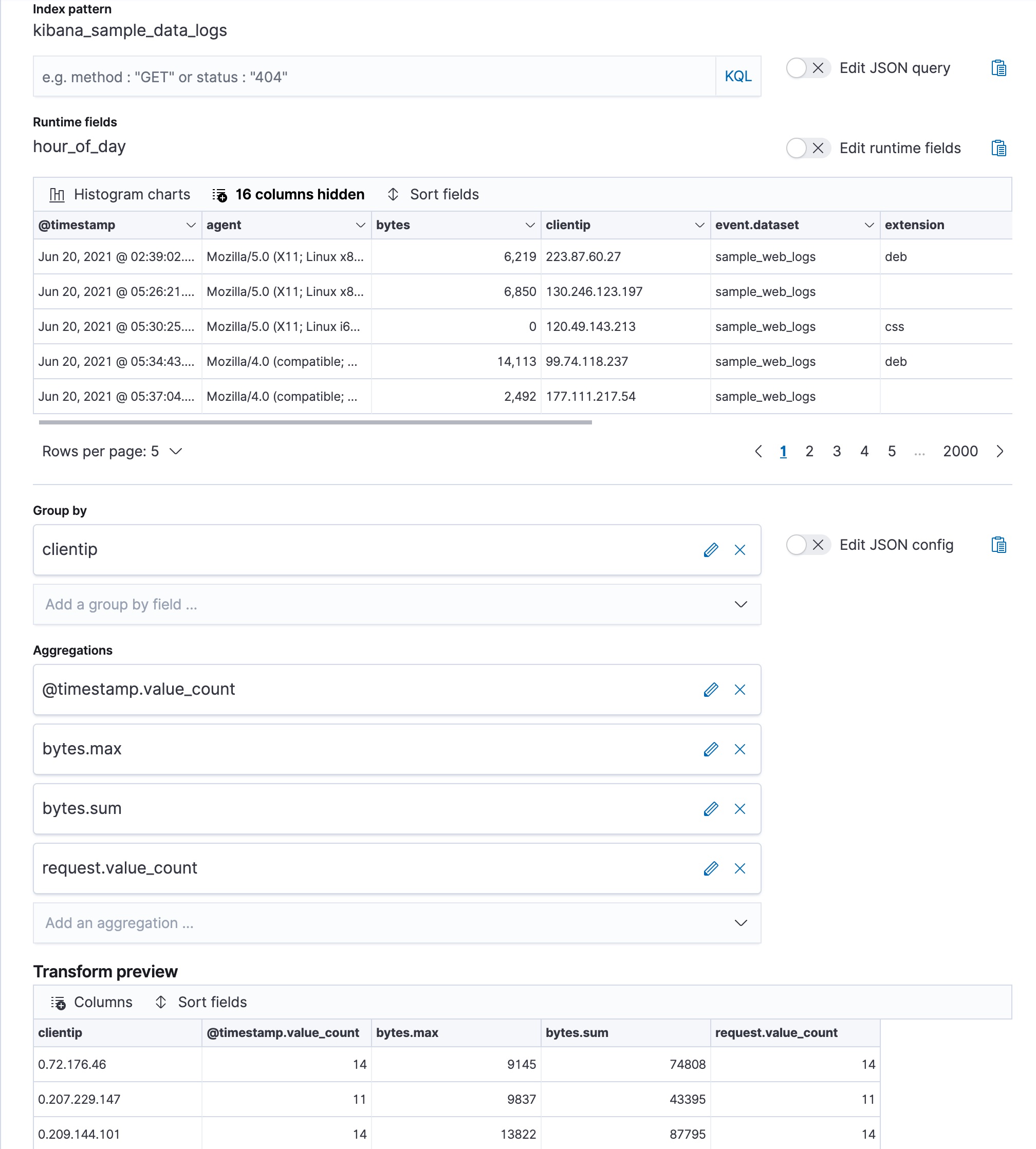
API 示例
POST _transform/_preview { "source": { "index": [ "kibana_sample_data_logs" ] }, "pivot": { "group_by": { "clientip": { "terms": { "field": "clientip" } } }, "aggregations": { "@timestamp.value_count": { "value_count": { "field": "@timestamp" } }, "bytes.max": { "max": { "field": "bytes" } }, "bytes.sum": { "sum": { "field": "bytes" } }, "request.value_count": { "value_count": { "field": "request.keyword" } } } } } PUT _transform/logs-by-clientip { "source": { "index": [ "kibana_sample_data_logs" ] }, "pivot": { "group_by": { "clientip": { "terms": { "field": "clientip" } } }, "aggregations": { "@timestamp.value_count": { "value_count": { "field": "@timestamp" } }, "bytes.max": { "max": { "field": "bytes" } }, "bytes.sum": { "sum": { "field": "bytes" } }, "request.value_count": { "value_count": { "field": "request.keyword" } } } }, "description": "Web logs by client IP", "dest": { "index": "weblog-clientip" } }
有关创建转换的更多详细信息,请参阅 转换电子商务示例数据。
-
启动转换。
即使资源利用率会根据集群负载自动调整,转换在运行时也会增加集群的搜索和索引负载。但是,如果您遇到过度的负载,可以停止它。
您可以在 Kibana 中启动、停止和管理转换。或者,您可以使用 启动转换 API。
API 示例
POST _transform/logs-by-clientip/_start
-
创建一个数据帧分析作业,以检测新的以实体为中心的索引中的异常值。
在 Kibana 的 Machine Learning > Data Frame Analytics 页面上的向导中,选择您的新数据视图,然后对异常值检测使用默认值。例如
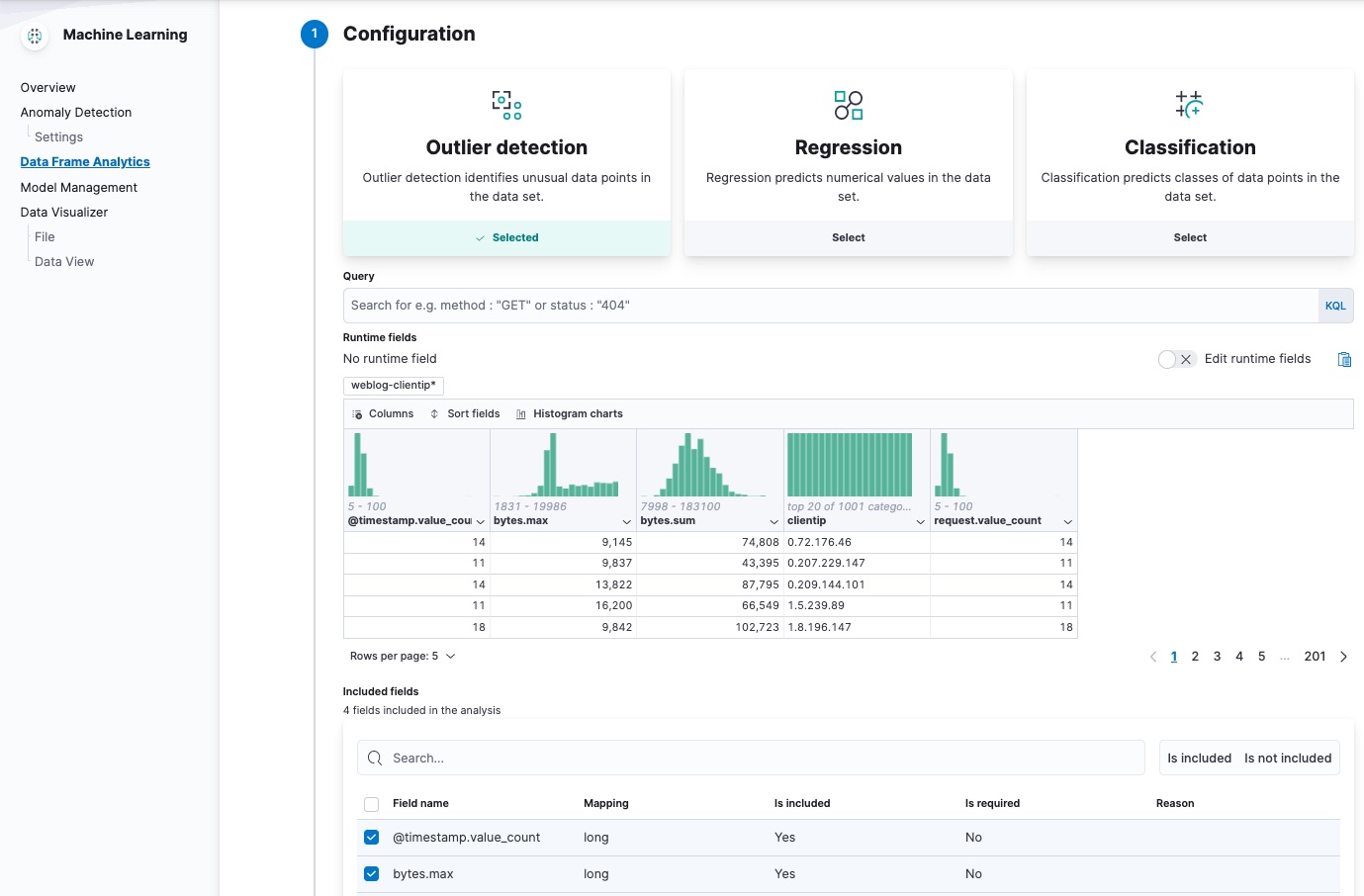
该向导包括一个散点图矩阵,使您可以探索字段之间的关系。您可以使用该信息来帮助您决定在分析中包含或排除哪些字段。
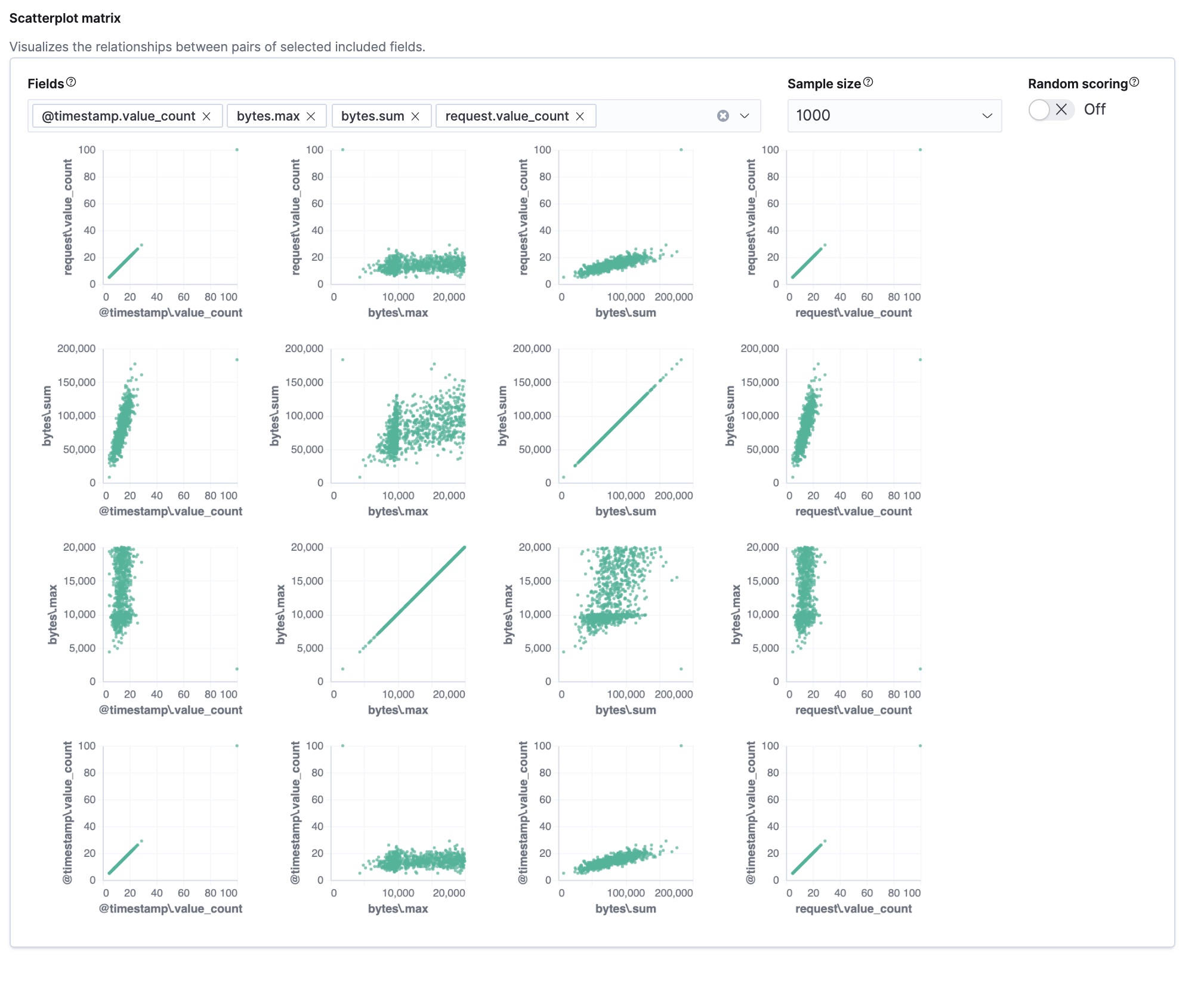
如果您希望这些图表表示来自更大样本量或来自随机选择的文档的数据,则可以更改默认行为。但是,更大的样本量可能会减慢矩阵的性能,而随机选择可能会由于更密集的查询而给集群带来更大的负载。
或者,您可以使用 创建数据帧分析作业 API。
API 示例
PUT _ml/data_frame/analytics/weblog-outliers { "source": { "index": "weblog-clientip" }, "dest": { "index": "weblog-outliers" }, "analysis": { "outlier_detection": { } }, "analyzed_fields" : { "includes" : ["@timestamp.value_count","bytes.max","bytes.sum","request.value_count"] } }
配置作业后,配置详细信息将自动验证。如果检查成功,您可以继续并启动作业。如果配置无效,则会显示警告消息。该消息包含一个建议,以改进配置以进行验证。
-
启动数据帧分析作业。
您可以在 Machine Learning > Data Frame Analytics 页面上启动、停止和管理数据帧分析作业。或者,您可以使用 启动数据帧分析作业 和 停止数据帧分析作业 API。
API 示例
POST _ml/data_frame/analytics/weblog-outliers/_start
-
查看异常值检测分析的结果。
数据帧分析作业会创建一个索引,其中包含每个文档的原始数据和异常值分数。异常值分数表示每个实体与其他实体的差异程度。
在 Kibana 中,您可以查看数据帧分析作业的结果,并按异常值分数对其进行排序
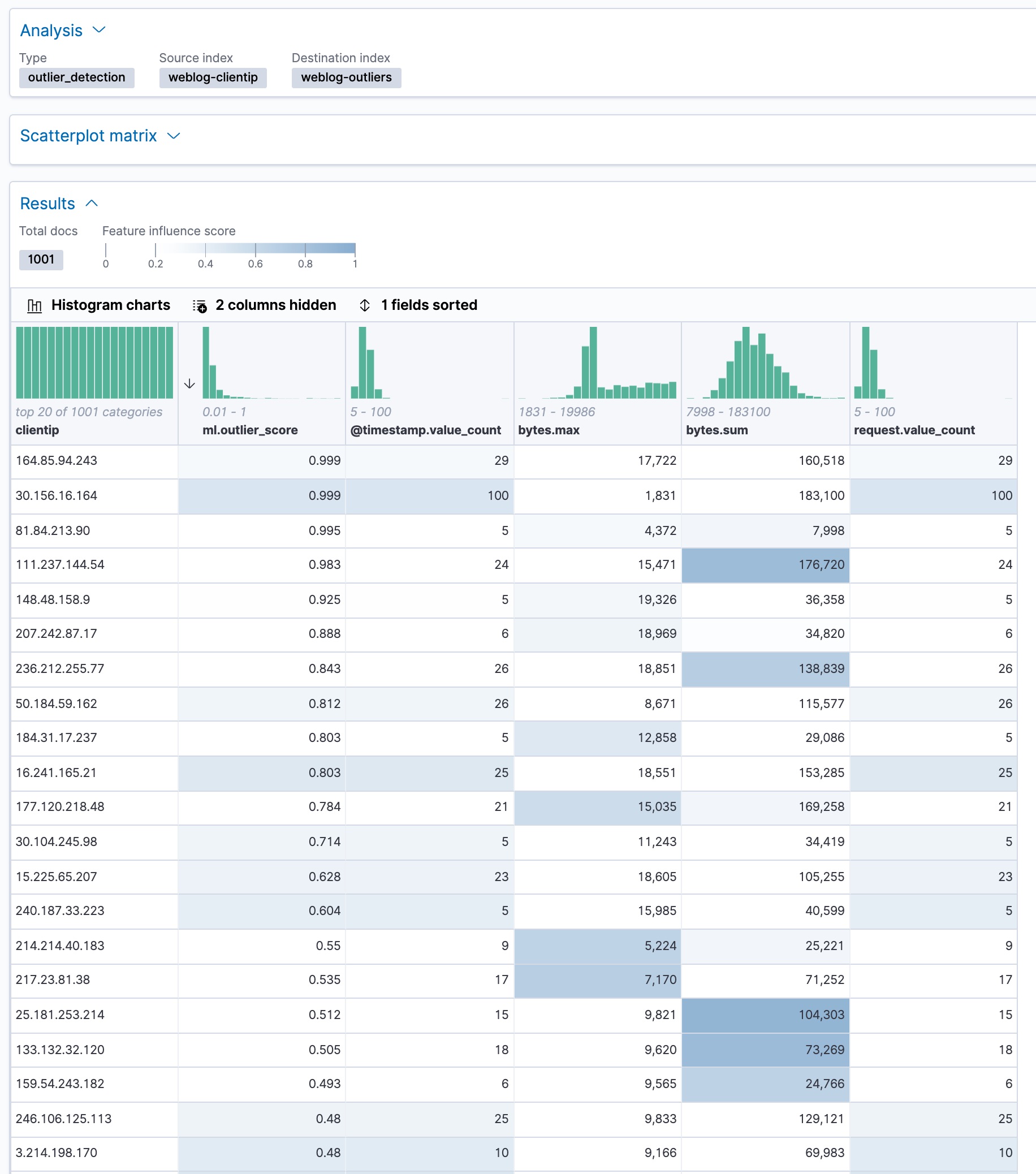
ml.outlier分数是介于 0 和 1 之间的值。值越大,它们成为异常值的可能性就越大。在 Kibana 中,您可以选择启用直方图图表,以更好地了解结果中每一列的值分布。除了整体异常值分数之外,每个文档还使用每个字段的特征影响值进行注释。这些值加起来为 1,并指示哪些字段在决定实体是异常值还是正常值时最重要。例如,客户端 IP
111.237.144.54的bytes.sum字段上的深色阴影表示,交换字节的总和是确定该客户端 IP 为异常值时最具影响力的特征。如果您想查看确切的特征影响值,可以从与您的数据帧分析作业关联的索引中检索它们。
API 示例
GET weblog-outliers/_search?q="111.237.144.54"
搜索结果包括以下异常值检测分数
... "ml" : { "outlier_score" : 0.9830020666122437, "feature_influence" : [ { "feature_name" : "@timestamp.value_count", "influence" : 0.005870792083442211 }, { "feature_name" : "bytes.max", "influence" : 0.12034820765256882 }, { "feature_name" : "bytes.sum", "influence" : 0.8679102063179016 }, { "feature_name" : "request.value_count", "influence" : 0.005870792083442211 } ] } ...
Kibana 还在结果中提供了一个散点图矩阵。分数超过阈值的异常值在每个图表中突出显示。可以使用矩阵下的滑块设置异常值分数阈值
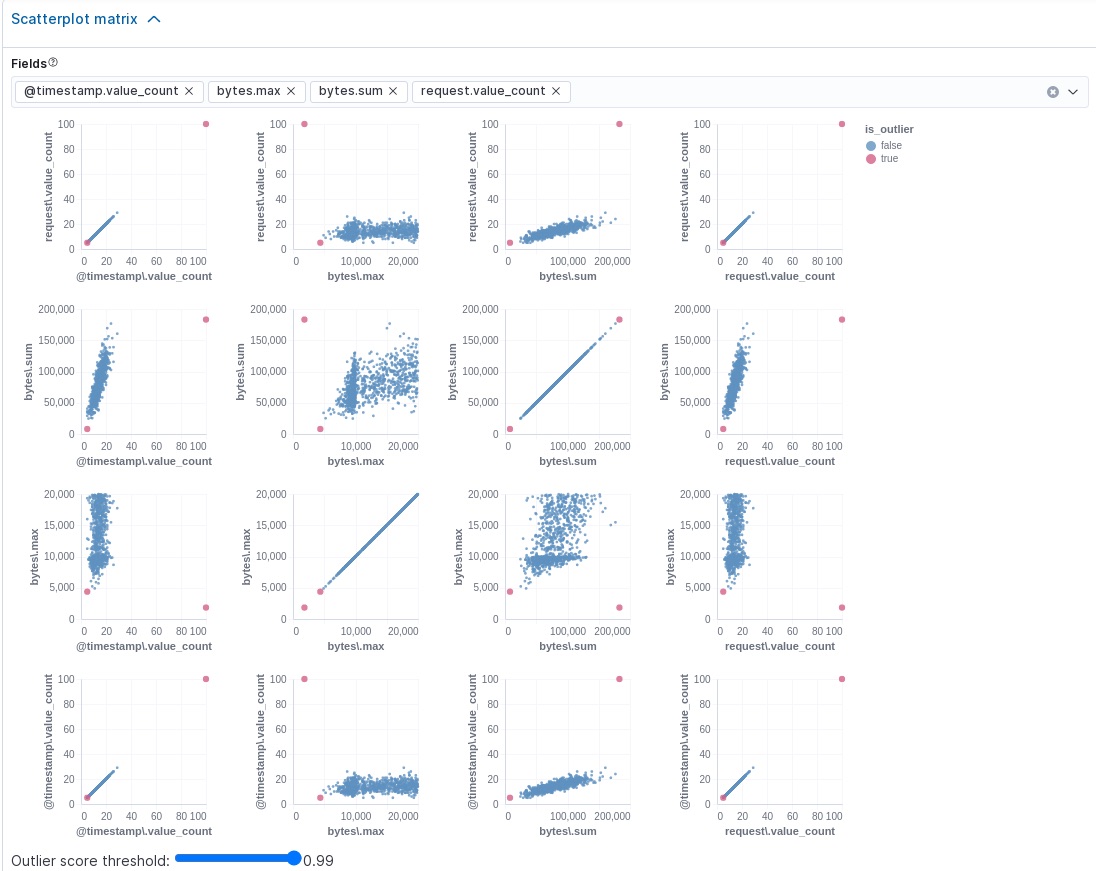
您可以在其中一个图表中突出显示一个区域,并且其余图表中也会突出显示相应的区域。此功能使您可以更轻松地专注于结果中的特定值和区域。除了样本大小和随机评分选项之外,还有一个 动态大小 选项。如果启用此选项,则每个点的大小都会受到其异常值分数的影响;也就是说,最大的点具有最高的异常值分数。这些图表和选项的目标是帮助您可视化和探索数据中的异常值。
既然您已经在示例数据集中发现了异常行为,请考虑如何将这些步骤应用于其他数据集。如果您有已经用真实异常值标记的数据,则可以使用评估数据帧分析 API 来确定异常值检测算法的执行情况。请参阅 6. 评估结果。
如果您不想保留转换和数据帧分析作业,可以在 Kibana 中删除它们,或者使用 删除转换 API 和 删除数据帧分析作业 API。当您在 Kibana 中删除转换和数据帧分析作业时,您可以选择同时删除目标索引和数据视图。
进一步阅读
编辑- 如果您想在 Jupyter 笔记本中查看另一个异常值检测示例,请点击这里。
- 这篇博客文章向您展示了如何使用异常值检测来捕获恶意软件。
- Elastic 机器学习中的异常值检测结果基准
On this page