- 机器学习其他版本
- 什么是 Elastic 机器学习?
- 设置和安全
- 异常检测
- 数据帧分析
- 自然语言处理
在集群中部署模型
编辑在集群中部署模型
编辑在导入模型和词汇表之后,您可以使用 Kibana 在机器学习 > 模型管理下查看和管理它们在集群中的部署。或者,您可以使用 启动已训练模型部署 API。
您可以通过在启动部署时分配唯一的部署 ID 来多次部署模型。
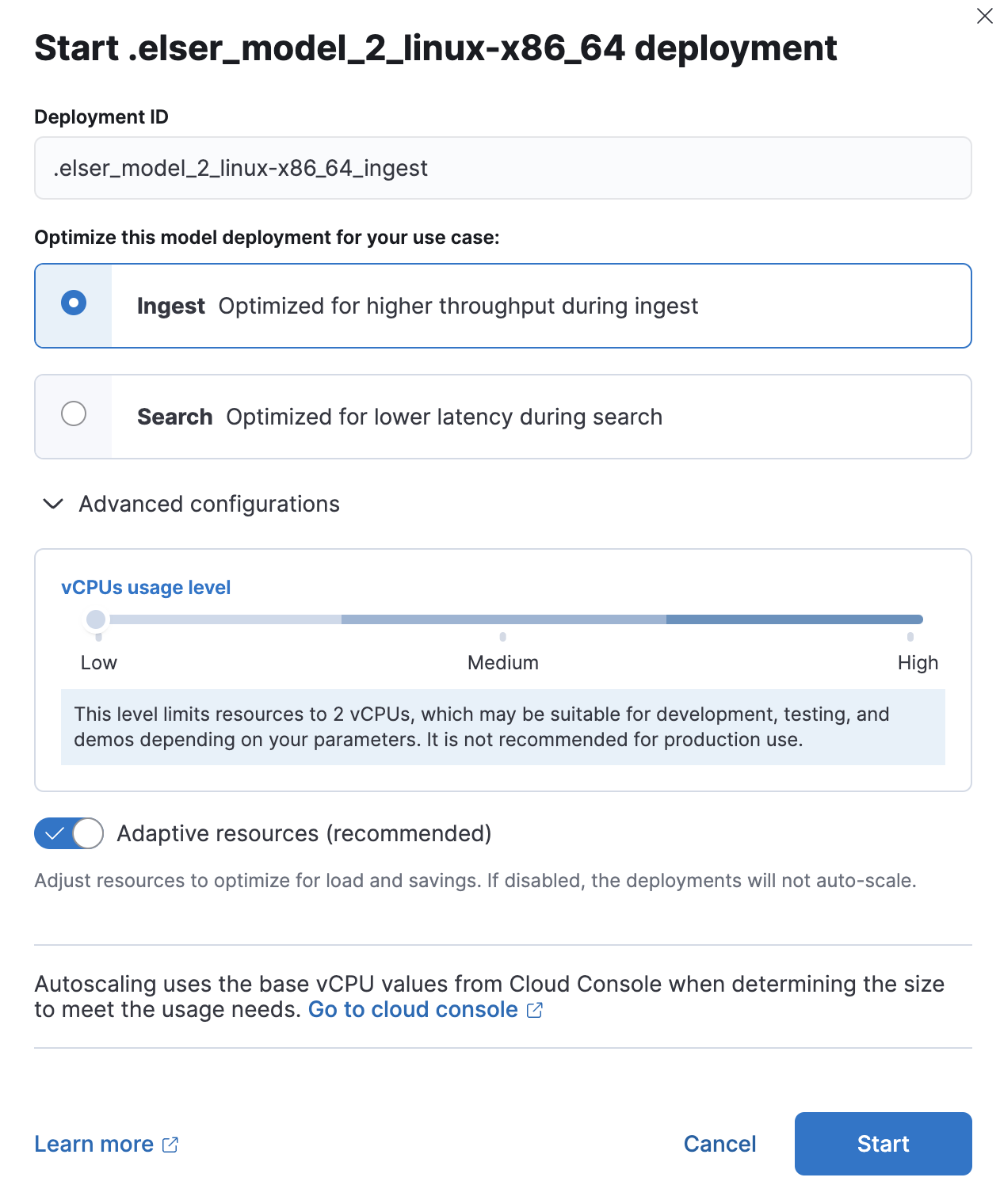
您可以针对典型的用例(例如搜索和摄取)优化您的部署。当您针对摄取进行优化时,吞吐量会更高,这会增加可以并行执行的推理请求数量。当您针对搜索进行优化时,搜索过程中的延迟会更低。当您为不同的目的进行专用部署时,您可以确保搜索速度不受摄取工作负载的影响,反之亦然。为搜索和摄取设置单独的部署可以减轻两者之间交互导致的性能问题,这些问题可能很难诊断。
每个部署都会根据您选择的特定目的自动进行微调。
由于 eland 使用 API 来部署模型,因此在保存的对象同步之前,您无法在 Kibana 中看到模型。您可以按照 Kibana 中的提示,等待自动同步,或者使用 同步机器学习保存的对象 API。
您可以在模型部署期间定义 NLP 模型的资源使用级别。资源使用级别的行为方式不同,具体取决于是否启用了自适应资源。当禁用自适应资源但启用机器学习自动缩放时,云部署的 vCPU 使用率来自云控制台,其功能如下
- 低:此级别将资源限制为两个 vCPU,这可能适用于开发、测试和演示,具体取决于您的参数。不建议用于生产环境。
- 中:此级别将资源限制为 32 个 vCPU,这可能适用于开发、测试和演示,具体取决于您的参数。不建议用于生产环境。
- 高:此级别可以使用云控制台中此部署可用的最大 vCPU 数量。如果最大值为 2 个或更少的 vCPU,则此级别等同于中或低级别。
有关启用自适应资源时的资源级别,请参阅 <已训练的模型自动缩放。
请求队列和搜索优先级
编辑模型部署的每个分配都有一个专用队列来缓冲推理请求。此队列的大小由 启动已训练模型部署 API 中的 queue_capacity 参数确定。当队列达到最大容量时,将拒绝新的请求,直到处理完一些排队的请求,从而再次创建可用容量。当多个摄取管道引用同一部署时,队列可能会填满,导致请求被拒绝。请考虑使用专用部署来避免这种情况。
来自搜索的推理请求(例如 text_expansion 查询)的优先级高于非搜索请求。推理摄取处理器生成普通优先级请求。如果搜索查询和摄取处理器都使用同一部署,则具有更高优先级的搜索请求会在队列中提前处理,然后处理较低优先级的摄取请求。这种优先级排序可以加快搜索响应速度,同时可能会减慢响应时间不太重要的摄取速度。
On this page