- Elasticsearch 指南其他版本
- 8.17 中的新功能
- Elasticsearch 基础
- 快速入门
- 设置 Elasticsearch
- 升级 Elasticsearch
- 索引模块
- 映射
- 文本分析
- 索引模板
- 数据流
- 摄取管道
- 别名
- 搜索您的数据
- 重新排名
- 查询 DSL
- 聚合
- 地理空间分析
- 连接器
- EQL
- ES|QL
- SQL
- 脚本
- 数据管理
- 自动缩放
- 监视集群
- 汇总或转换数据
- 设置高可用性集群
- 快照和还原
- 保护 Elastic Stack 的安全
- Watcher
- 命令行工具
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- 优化
- 故障排除
- 修复常见的集群问题
- 诊断未分配的分片
- 向系统中添加丢失的层
- 允许 Elasticsearch 在系统中分配数据
- 允许 Elasticsearch 分配索引
- 索引将索引分配过滤器与数据层节点角色混合,以在数据层之间移动
- 没有足够的节点来分配所有分片副本
- 单个节点上索引的分片总数已超过
- 每个节点的分片总数已达到
- 故障排除损坏
- 修复磁盘空间不足的数据节点
- 修复磁盘空间不足的主节点
- 修复磁盘空间不足的其他角色节点
- 启动索引生命周期管理
- 启动快照生命周期管理
- 从快照恢复
- 故障排除损坏的存储库
- 解决重复的快照策略失败问题
- 故障排除不稳定的集群
- 故障排除发现
- 故障排除监控
- 故障排除转换
- 故障排除 Watcher
- 故障排除搜索
- 故障排除分片容量健康问题
- 故障排除不平衡的集群
- 捕获诊断信息
- REST API
- API 约定
- 通用选项
- REST API 兼容性
- 自动缩放 API
- 行为分析 API
- 紧凑和对齐文本 (CAT) API
- 集群 API
- 跨集群复制 API
- 连接器 API
- 数据流 API
- 文档 API
- 丰富 API
- EQL API
- ES|QL API
- 功能 API
- Fleet API
- 图表探索 API
- 索引 API
- 别名是否存在
- 别名
- 分析
- 分析索引磁盘使用量
- 清除缓存
- 克隆索引
- 关闭索引
- 创建索引
- 创建或更新别名
- 创建或更新组件模板
- 创建或更新索引模板
- 创建或更新索引模板(旧版)
- 删除组件模板
- 删除悬挂索引
- 删除别名
- 删除索引
- 删除索引模板
- 删除索引模板(旧版)
- 存在
- 字段使用情况统计信息
- 刷新
- 强制合并
- 获取别名
- 获取组件模板
- 获取字段映射
- 获取索引
- 获取索引设置
- 获取索引模板
- 获取索引模板(旧版)
- 获取映射
- 导入悬挂索引
- 索引恢复
- 索引段
- 索引分片存储
- 索引统计信息
- 索引模板是否存在(旧版)
- 列出悬挂索引
- 打开索引
- 刷新
- 解析索引
- 解析集群
- 翻转
- 收缩索引
- 模拟索引
- 模拟模板
- 拆分索引
- 解冻索引
- 更新索引设置
- 更新映射
- 索引生命周期管理 API
- 推理 API
- 信息 API
- 摄取 API
- 许可 API
- Logstash API
- 机器学习 API
- 机器学习异常检测 API
- 机器学习数据帧分析 API
- 机器学习训练模型 API
- 迁移 API
- 节点生命周期 API
- 查询规则 API
- 重新加载搜索分析器 API
- 存储库计量 API
- 汇总 API
- 根 API
- 脚本 API
- 搜索 API
- 搜索应用程序 API
- 可搜索快照 API
- 安全 API
- 身份验证
- 更改密码
- 清除缓存
- 清除角色缓存
- 清除权限缓存
- 清除 API 密钥缓存
- 清除服务帐户令牌缓存
- 创建 API 密钥
- 创建或更新应用程序权限
- 创建或更新角色映射
- 创建或更新角色
- 批量创建或更新角色 API
- 批量删除角色 API
- 创建或更新用户
- 创建服务帐户令牌
- 委托 PKI 身份验证
- 删除应用程序权限
- 删除角色映射
- 删除角色
- 删除服务帐户令牌
- 删除用户
- 禁用用户
- 启用用户
- 注册 Kibana
- 注册节点
- 获取 API 密钥信息
- 获取应用程序权限
- 获取内置权限
- 获取角色映射
- 获取角色
- 查询角色
- 获取服务帐户
- 获取服务帐户凭据
- 获取安全设置
- 获取令牌
- 获取用户权限
- 获取用户
- 授予 API 密钥
- 具有权限
- 使 API 密钥失效
- 使令牌失效
- OpenID Connect 准备身份验证
- OpenID Connect 身份验证
- OpenID Connect 注销
- 查询 API 密钥信息
- 查询用户
- 更新 API 密钥
- 更新安全设置
- 批量更新 API 密钥
- SAML 准备身份验证
- SAML 身份验证
- SAML 注销
- SAML 失效
- SAML 完成注销
- SAML 服务提供商元数据
- SSL 证书
- 激活用户配置文件
- 禁用用户配置文件
- 启用用户配置文件
- 获取用户配置文件
- 建议用户配置文件
- 更新用户配置文件数据
- 具有用户配置文件权限
- 创建跨集群 API 密钥
- 更新跨集群 API 密钥
- 快照和还原 API
- 快照生命周期管理 API
- SQL API
- 同义词 API
- 文本结构 API
- 转换 API
- 使用情况 API
- Watcher API
- 定义
- 迁移指南
- 发行说明
- Elasticsearch 版本 8.17.0
- Elasticsearch 版本 8.16.1
- Elasticsearch 版本 8.16.0
- Elasticsearch 版本 8.15.5
- Elasticsearch 版本 8.15.4
- Elasticsearch 版本 8.15.3
- Elasticsearch 版本 8.15.2
- Elasticsearch 版本 8.15.1
- Elasticsearch 版本 8.15.0
- Elasticsearch 版本 8.14.3
- Elasticsearch 版本 8.14.2
- Elasticsearch 版本 8.14.1
- Elasticsearch 版本 8.14.0
- Elasticsearch 版本 8.13.4
- Elasticsearch 版本 8.13.3
- Elasticsearch 版本 8.13.2
- Elasticsearch 版本 8.13.1
- Elasticsearch 版本 8.13.0
- Elasticsearch 版本 8.12.2
- Elasticsearch 版本 8.12.1
- Elasticsearch 版本 8.12.0
- Elasticsearch 版本 8.11.4
- Elasticsearch 版本 8.11.3
- Elasticsearch 版本 8.11.2
- Elasticsearch 版本 8.11.1
- Elasticsearch 版本 8.11.0
- Elasticsearch 版本 8.10.4
- Elasticsearch 版本 8.10.3
- Elasticsearch 版本 8.10.2
- Elasticsearch 版本 8.10.1
- Elasticsearch 版本 8.10.0
- Elasticsearch 版本 8.9.2
- Elasticsearch 版本 8.9.1
- Elasticsearch 版本 8.9.0
- Elasticsearch 版本 8.8.2
- Elasticsearch 版本 8.8.1
- Elasticsearch 版本 8.8.0
- Elasticsearch 版本 8.7.1
- Elasticsearch 版本 8.7.0
- Elasticsearch 版本 8.6.2
- Elasticsearch 版本 8.6.1
- Elasticsearch 版本 8.6.0
- Elasticsearch 版本 8.5.3
- Elasticsearch 版本 8.5.2
- Elasticsearch 版本 8.5.1
- Elasticsearch 版本 8.5.0
- Elasticsearch 版本 8.4.3
- Elasticsearch 版本 8.4.2
- Elasticsearch 版本 8.4.1
- Elasticsearch 版本 8.4.0
- Elasticsearch 版本 8.3.3
- Elasticsearch 版本 8.3.2
- Elasticsearch 版本 8.3.1
- Elasticsearch 版本 8.3.0
- Elasticsearch 版本 8.2.3
- Elasticsearch 版本 8.2.2
- Elasticsearch 版本 8.2.1
- Elasticsearch 版本 8.2.0
- Elasticsearch 版本 8.1.3
- Elasticsearch 版本 8.1.2
- Elasticsearch 版本 8.1.1
- Elasticsearch 版本 8.1.0
- Elasticsearch 版本 8.0.1
- Elasticsearch 版本 8.0.0
- Elasticsearch 版本 8.0.0-rc2
- Elasticsearch 版本 8.0.0-rc1
- Elasticsearch 版本 8.0.0-beta1
- Elasticsearch 版本 8.0.0-alpha2
- Elasticsearch 版本 8.0.0-alpha1
- 依赖项和版本
ES|QL 查询入门
编辑ES|QL 查询入门
编辑本指南介绍如何使用 ES|QL 查询和聚合数据。
此入门指南还提供 交互式 Python 笔记本,位于 elasticsearch-labs GitHub 存储库中。
前提条件
编辑要按照本指南中的查询进行操作,您可以设置自己的部署,或使用 Elastic 的公共 ES|QL 演示环境。
首先摄入一些示例数据。在 Kibana 中,打开主菜单并选择 Dev Tools。运行以下两个请求
resp = client.indices.create( index="sample_data", mappings={ "properties": { "client_ip": { "type": "ip" }, "message": { "type": "keyword" } } }, ) print(resp) resp1 = client.bulk( index="sample_data", operations=[ { "index": {} }, { "@timestamp": "2023-10-23T12:15:03.360Z", "client_ip": "172.21.2.162", "message": "Connected to 10.1.0.3", "event_duration": 3450233 }, { "index": {} }, { "@timestamp": "2023-10-23T12:27:28.948Z", "client_ip": "172.21.2.113", "message": "Connected to 10.1.0.2", "event_duration": 2764889 }, { "index": {} }, { "@timestamp": "2023-10-23T13:33:34.937Z", "client_ip": "172.21.0.5", "message": "Disconnected", "event_duration": 1232382 }, { "index": {} }, { "@timestamp": "2023-10-23T13:51:54.732Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 725448 }, { "index": {} }, { "@timestamp": "2023-10-23T13:52:55.015Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 8268153 }, { "index": {} }, { "@timestamp": "2023-10-23T13:53:55.832Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 5033755 }, { "index": {} }, { "@timestamp": "2023-10-23T13:55:01.543Z", "client_ip": "172.21.3.15", "message": "Connected to 10.1.0.1", "event_duration": 1756467 } ], ) print(resp1)
response = client.indices.create( index: 'sample_data', body: { mappings: { properties: { client_ip: { type: 'ip' }, message: { type: 'keyword' } } } } ) puts response response = client.bulk( index: 'sample_data', body: [ { index: {} }, { "@timestamp": '2023-10-23T12:15:03.360Z', client_ip: '172.21.2.162', message: 'Connected to 10.1.0.3', event_duration: 3_450_233 }, { index: {} }, { "@timestamp": '2023-10-23T12:27:28.948Z', client_ip: '172.21.2.113', message: 'Connected to 10.1.0.2', event_duration: 2_764_889 }, { index: {} }, { "@timestamp": '2023-10-23T13:33:34.937Z', client_ip: '172.21.0.5', message: 'Disconnected', event_duration: 1_232_382 }, { index: {} }, { "@timestamp": '2023-10-23T13:51:54.732Z', client_ip: '172.21.3.15', message: 'Connection error', event_duration: 725_448 }, { index: {} }, { "@timestamp": '2023-10-23T13:52:55.015Z', client_ip: '172.21.3.15', message: 'Connection error', event_duration: 8_268_153 }, { index: {} }, { "@timestamp": '2023-10-23T13:53:55.832Z', client_ip: '172.21.3.15', message: 'Connection error', event_duration: 5_033_755 }, { index: {} }, { "@timestamp": '2023-10-23T13:55:01.543Z', client_ip: '172.21.3.15', message: 'Connected to 10.1.0.1', event_duration: 1_756_467 } ] ) puts response
const response = await client.indices.create({ index: "sample_data", mappings: { properties: { client_ip: { type: "ip", }, message: { type: "keyword", }, }, }, }); console.log(response); const response1 = await client.bulk({ index: "sample_data", operations: [ { index: {}, }, { "@timestamp": "2023-10-23T12:15:03.360Z", client_ip: "172.21.2.162", message: "Connected to 10.1.0.3", event_duration: 3450233, }, { index: {}, }, { "@timestamp": "2023-10-23T12:27:28.948Z", client_ip: "172.21.2.113", message: "Connected to 10.1.0.2", event_duration: 2764889, }, { index: {}, }, { "@timestamp": "2023-10-23T13:33:34.937Z", client_ip: "172.21.0.5", message: "Disconnected", event_duration: 1232382, }, { index: {}, }, { "@timestamp": "2023-10-23T13:51:54.732Z", client_ip: "172.21.3.15", message: "Connection error", event_duration: 725448, }, { index: {}, }, { "@timestamp": "2023-10-23T13:52:55.015Z", client_ip: "172.21.3.15", message: "Connection error", event_duration: 8268153, }, { index: {}, }, { "@timestamp": "2023-10-23T13:53:55.832Z", client_ip: "172.21.3.15", message: "Connection error", event_duration: 5033755, }, { index: {}, }, { "@timestamp": "2023-10-23T13:55:01.543Z", client_ip: "172.21.3.15", message: "Connected to 10.1.0.1", event_duration: 1756467, }, ], }); console.log(response1);
PUT sample_data { "mappings": { "properties": { "client_ip": { "type": "ip" }, "message": { "type": "keyword" } } } } PUT sample_data/_bulk {"index": {}} {"@timestamp": "2023-10-23T12:15:03.360Z", "client_ip": "172.21.2.162", "message": "Connected to 10.1.0.3", "event_duration": 3450233} {"index": {}} {"@timestamp": "2023-10-23T12:27:28.948Z", "client_ip": "172.21.2.113", "message": "Connected to 10.1.0.2", "event_duration": 2764889} {"index": {}} {"@timestamp": "2023-10-23T13:33:34.937Z", "client_ip": "172.21.0.5", "message": "Disconnected", "event_duration": 1232382} {"index": {}} {"@timestamp": "2023-10-23T13:51:54.732Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 725448} {"index": {}} {"@timestamp": "2023-10-23T13:52:55.015Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 8268153} {"index": {}} {"@timestamp": "2023-10-23T13:53:55.832Z", "client_ip": "172.21.3.15", "message": "Connection error", "event_duration": 5033755} {"index": {}} {"@timestamp": "2023-10-23T13:55:01.543Z", "client_ip": "172.21.3.15", "message": "Connected to 10.1.0.1", "event_duration": 1756467}
本指南中使用的数据集已预加载到 Elastic ES|QL 公共演示环境中。访问 ela.st/ql 开始使用。
运行 ES|QL 查询
编辑在 Kibana 中,您可以使用控制台或 Discover 来运行 ES|QL 查询
要开始在控制台中使用 ES|QL,请打开主菜单并选择 Dev Tools。
ES|QL 查询 API 请求的一般结构如下
POST /_query?format=txt { "query": """ """ }
在两组三引号之间输入实际的 ES|QL 查询。例如
POST /_query?format=txt { "query": """ FROM sample_data """ }
要开始在 Discover 中使用 ES|QL,请打开主菜单并选择 Discover。接下来,从应用程序菜单栏中选择 Try ES|QL。
调整时间过滤器,使其包含示例数据中的时间戳(2023 年 10 月 23 日)。
切换到 ES|QL 模式后,查询栏会显示一个示例查询。您可以用本入门指南中的查询替换此查询。
为了更容易编写查询,自动完成功能会提供可能的命令和函数的建议
您可以通过拖动其底部边框来调整编辑器的高度,使其符合您的喜好。
您的第一个 ES|QL 查询
编辑每个 ES|QL 查询都以源命令开头。源命令生成一个表,通常包含来自 Elasticsearch 的数据。

FROM 源命令返回一个表,其中包含来自数据流、索引或别名的文档。结果表中的每一行代表一个文档。此查询从 sample_data 索引返回最多 1000 个文档
FROM sample_data
每列对应一个字段,可以通过该字段的名称进行访问。
ES|QL 关键字不区分大小写。以下查询与前一个查询相同
from sample_data
处理命令
编辑一个源命令后面可以跟一个或多个处理命令,用管道符分隔:|。处理命令通过添加、删除或更改行和列来更改输入表。处理命令可以执行过滤、投影、聚合等操作。
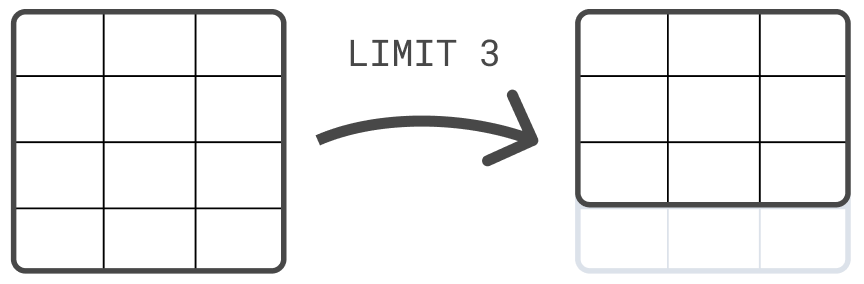
例如,您可以使用LIMIT命令来限制返回的行数,最多 10,000 行
FROM sample_data | LIMIT 3
为了方便阅读,您可以将每个命令放在单独的一行上。但是,您不必这样做。以下查询与前一个查询相同
FROM sample_data | LIMIT 3
排序表
编辑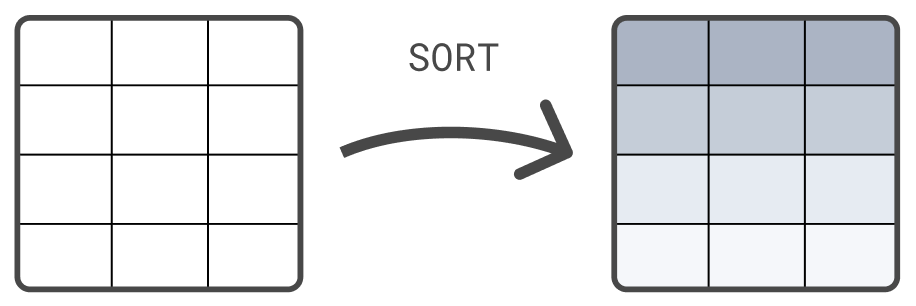
另一个处理命令是SORT命令。默认情况下,FROM 返回的行没有定义的排序顺序。使用 SORT 命令根据一个或多个列对行进行排序
FROM sample_data | SORT @timestamp DESC
查询数据
编辑使用WHERE命令来查询数据。例如,要查找所有持续时间超过 5 毫秒的事件
FROM sample_data | WHERE event_duration > 5000000
WHERE 支持几个运算符。例如,您可以使用LIKE对 message 列运行通配符查询
FROM sample_data | WHERE message LIKE "Connected*"
更多处理命令
编辑还有许多其他处理命令,例如 KEEP 和 DROP 用于保留或删除列,ENRICH 用于使用 Elasticsearch 中索引的数据丰富表,以及 DISSECT 和 GROK 用于处理数据。有关所有处理命令的概述,请参阅处理命令。
链式处理命令
编辑您可以链式处理命令,用管道符分隔:|。每个处理命令都对前一个命令的输出表进行操作。查询的结果是最终处理命令生成的表。
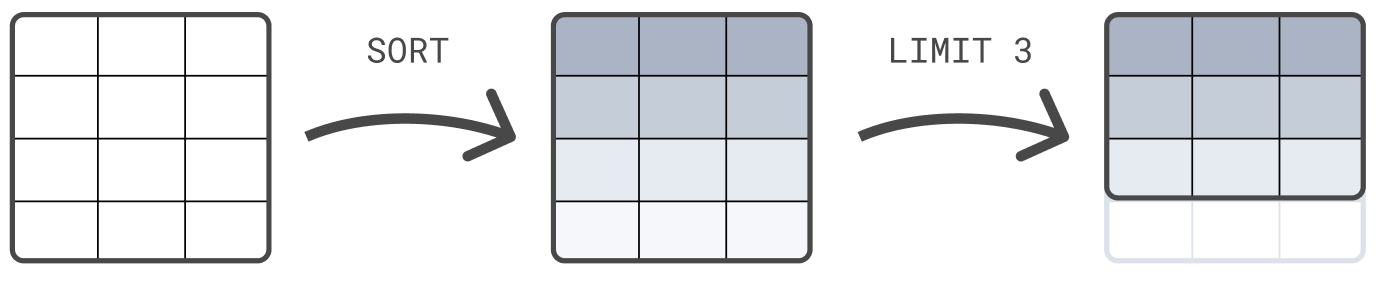
以下示例首先按 @timestamp 对表进行排序,然后将结果集限制为 3 行
FROM sample_data | SORT @timestamp DESC | LIMIT 3
处理命令的顺序很重要。在排序之前先将结果集限制为 3 行,很可能会返回与此示例不同的结果,在此示例中,排序在限制之前。
计算值
编辑使用EVAL命令向表中附加具有计算值的新列。例如,以下查询附加一个 duration_ms 列。列中的值通过将 event_duration 除以 1,000,000 来计算。换句话说:event_duration 从纳秒转换为毫秒。
FROM sample_data | EVAL duration_ms = event_duration/1000000.0
EVAL 支持多个函数。例如,要将数字四舍五入到具有指定位数的最接近数字,请使用ROUND函数
FROM sample_data | EVAL duration_ms = ROUND(event_duration/1000000.0, 1)
计算统计信息
编辑ES|QL 不仅可以用于查询数据,还可以用于聚合数据。使用STATS命令来计算统计信息。例如,中位数持续时间
FROM sample_data | STATS median_duration = MEDIAN(event_duration)
您可以使用一个命令计算多个统计信息
FROM sample_data | STATS median_duration = MEDIAN(event_duration), max_duration = MAX(event_duration)
使用 BY 按一个或多个列对计算的统计信息进行分组。例如,要计算每个客户端 IP 的中位数持续时间
FROM sample_data | STATS median_duration = MEDIAN(event_duration) BY client_ip
访问列
编辑您可以通过列的名称访问列。如果名称包含特殊字符,则需要用反引号 (`) 引起来。
为 EVAL 或 STATS 创建的列分配显式名称是可选的。如果您不提供名称,则新列名称等于函数表达式。例如
FROM sample_data | EVAL event_duration/1000000.0
在此查询中,EVAL 添加了一个名为 event_duration/1000000.0 的新列。由于其名称包含特殊字符,要访问此列,请用反引号将其引起来
FROM sample_data | EVAL event_duration/1000000.0 | STATS MEDIAN(`event_duration/1000000.0`)
创建直方图
编辑为了跟踪一段时间内的统计信息,ES|QL 使您能够使用 BUCKET 函数创建直方图。BUCKET 创建用户友好的存储桶大小,并为每一行返回一个值,该值对应于该行落入的存储桶。
将 BUCKET 与 STATS 结合使用以创建直方图。例如,要计算每小时的事件数
FROM sample_data | STATS c = COUNT(*) BY bucket = BUCKET(@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
或者每小时的中位数持续时间
FROM sample_data | KEEP @timestamp, event_duration | STATS median_duration = MEDIAN(event_duration) BY bucket = BUCKET(@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
丰富数据
编辑ES|QL 使您能够使用 ENRICH 命令使用 Elasticsearch 中索引的数据丰富表。
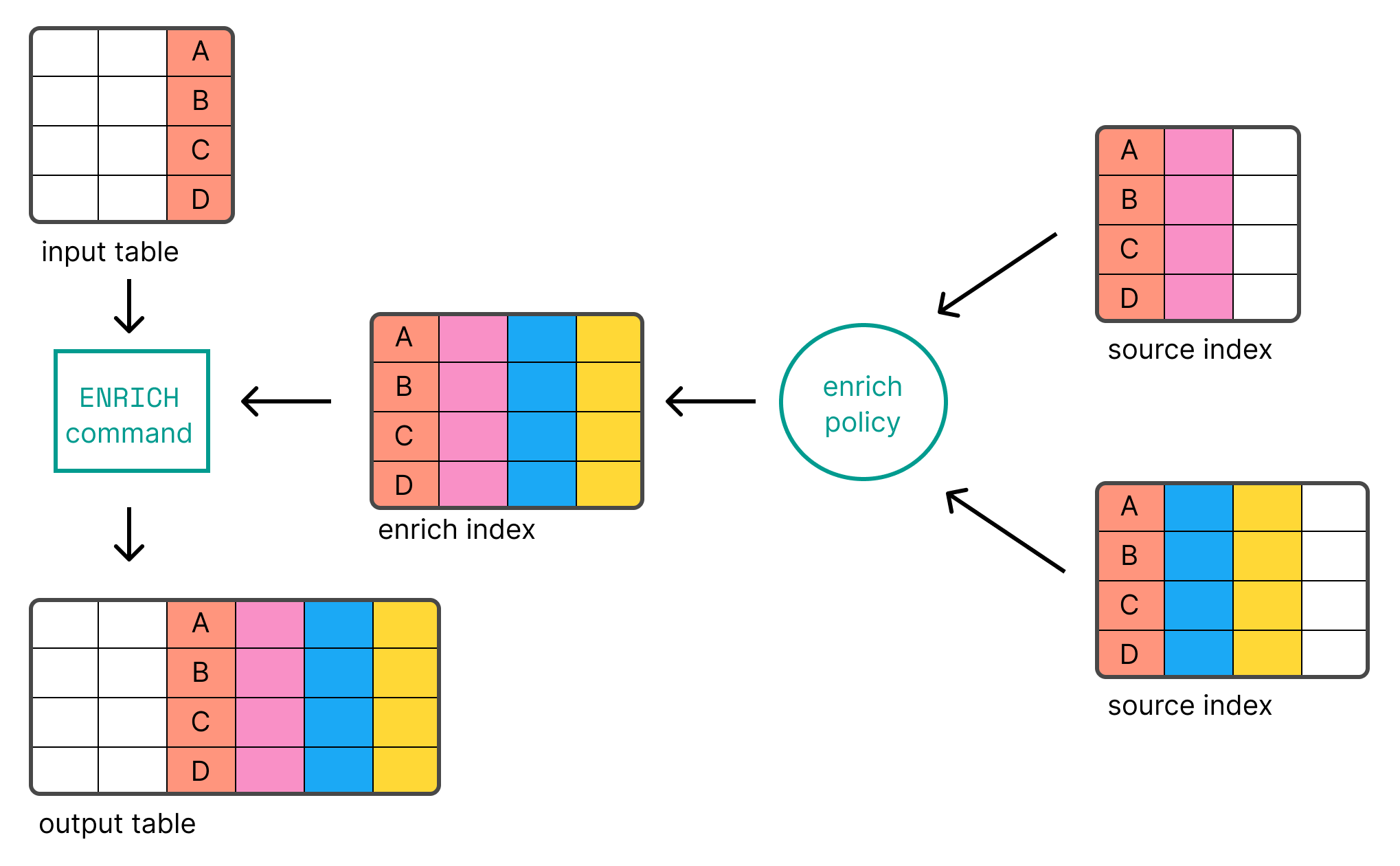
在您可以使用 ENRICH 之前,您首先需要创建并执行丰富策略。
以下请求创建并执行一个名为 clientip_policy 的策略。该策略将 IP 地址链接到环境(“开发”、“QA”或“生产”)
resp = client.indices.create( index="clientips", mappings={ "properties": { "client_ip": { "type": "keyword" }, "env": { "type": "keyword" } } }, ) print(resp) resp1 = client.bulk( index="clientips", operations=[ { "index": {} }, { "client_ip": "172.21.0.5", "env": "Development" }, { "index": {} }, { "client_ip": "172.21.2.113", "env": "QA" }, { "index": {} }, { "client_ip": "172.21.2.162", "env": "QA" }, { "index": {} }, { "client_ip": "172.21.3.15", "env": "Production" }, { "index": {} }, { "client_ip": "172.21.3.16", "env": "Production" } ], ) print(resp1) resp2 = client.enrich.put_policy( name="clientip_policy", match={ "indices": "clientips", "match_field": "client_ip", "enrich_fields": [ "env" ] }, ) print(resp2) resp3 = client.enrich.execute_policy( name="clientip_policy", wait_for_completion=False, ) print(resp3)
response = client.indices.create( index: 'clientips', body: { mappings: { properties: { client_ip: { type: 'keyword' }, env: { type: 'keyword' } } } } ) puts response response = client.bulk( index: 'clientips', body: [ { index: {} }, { client_ip: '172.21.0.5', env: 'Development' }, { index: {} }, { client_ip: '172.21.2.113', env: 'QA' }, { index: {} }, { client_ip: '172.21.2.162', env: 'QA' }, { index: {} }, { client_ip: '172.21.3.15', env: 'Production' }, { index: {} }, { client_ip: '172.21.3.16', env: 'Production' } ] ) puts response response = client.enrich.put_policy( name: 'clientip_policy', body: { match: { indices: 'clientips', match_field: 'client_ip', enrich_fields: [ 'env' ] } } ) puts response response = client.enrich.execute_policy( name: 'clientip_policy', wait_for_completion: false ) puts response
const response = await client.indices.create({ index: "clientips", mappings: { properties: { client_ip: { type: "keyword", }, env: { type: "keyword", }, }, }, }); console.log(response); const response1 = await client.bulk({ index: "clientips", operations: [ { index: {}, }, { client_ip: "172.21.0.5", env: "Development", }, { index: {}, }, { client_ip: "172.21.2.113", env: "QA", }, { index: {}, }, { client_ip: "172.21.2.162", env: "QA", }, { index: {}, }, { client_ip: "172.21.3.15", env: "Production", }, { index: {}, }, { client_ip: "172.21.3.16", env: "Production", }, ], }); console.log(response1); const response2 = await client.enrich.putPolicy({ name: "clientip_policy", match: { indices: "clientips", match_field: "client_ip", enrich_fields: ["env"], }, }); console.log(response2); const response3 = await client.enrich.executePolicy({ name: "clientip_policy", wait_for_completion: "false", }); console.log(response3);
PUT clientips { "mappings": { "properties": { "client_ip": { "type": "keyword" }, "env": { "type": "keyword" } } } } PUT clientips/_bulk { "index" : {}} { "client_ip": "172.21.0.5", "env": "Development" } { "index" : {}} { "client_ip": "172.21.2.113", "env": "QA" } { "index" : {}} { "client_ip": "172.21.2.162", "env": "QA" } { "index" : {}} { "client_ip": "172.21.3.15", "env": "Production" } { "index" : {}} { "client_ip": "172.21.3.16", "env": "Production" } PUT /_enrich/policy/clientip_policy { "match": { "indices": "clientips", "match_field": "client_ip", "enrich_fields": ["env"] } } PUT /_enrich/policy/clientip_policy/_execute?wait_for_completion=false
在 ela.st/ql 上的演示环境中,已经创建并执行了一个名为 clientip_policy 的丰富策略。该策略将 IP 地址链接到环境(“开发”、“QA”或“生产”)。
在创建和执行策略后,您可以将其与 ENRICH 命令一起使用
FROM sample_data | KEEP @timestamp, client_ip, event_duration | EVAL client_ip = TO_STRING(client_ip) | ENRICH clientip_policy ON client_ip WITH env
您可以使用 ENRICH 命令添加的新 env 列在后续命令中。例如,要计算每个环境的中位数持续时间
FROM sample_data | KEEP @timestamp, client_ip, event_duration | EVAL client_ip = TO_STRING(client_ip) | ENRICH clientip_policy ON client_ip WITH env | STATS median_duration = MEDIAN(event_duration) BY env
有关使用 ES|QL 进行数据丰富的更多信息,请参阅数据丰富。
处理数据
编辑您的数据可能包含您想要结构化的非结构化字符串,以便更容易分析数据。例如,示例数据包含如下日志消息
"Connected to 10.1.0.3"
通过从这些消息中提取 IP 地址,您可以确定哪个 IP 已接受最多的客户端连接。
要在查询时结构化非结构化字符串,您可以使用 ES|QL DISSECT 和 GROK 命令。DISSECT 通过使用基于分隔符的模式来分解字符串。 GROK 的工作方式类似,但使用正则表达式。这使得 GROK 更强大,但通常也更慢。
在这种情况下,不需要使用正则表达式,因为 message 非常直接: “Connected to ”,后跟服务器 IP。 要匹配此字符串,可以使用以下 DISSECT 命令
FROM sample_data | DISSECT message "Connected to %{server_ip}"
这将为那些 message 与此模式匹配的行添加一个 server_ip 列。 对于其他行,server_ip 的值是 null。
您可以在后续命令中使用 DISSECT 命令添加的新 server_ip 列。 例如,要确定每个服务器已接受多少个连接
FROM sample_data | WHERE STARTS_WITH(message, "Connected to") | DISSECT message "Connected to %{server_ip}" | STATS COUNT(*) BY server_ip
有关使用 ES|QL 进行数据处理的更多信息,请参阅 使用 DISSECT 和 GROK 进行数据处理。