- Elasticsearch 指南其他版本
- 8.17 中的新功能
- Elasticsearch 基础
- 快速入门
- 设置 Elasticsearch
- 升级 Elasticsearch
- 索引模块
- 映射
- 文本分析
- 索引模板
- 数据流
- 摄取管道
- 别名
- 搜索您的数据
- 重新排名
- 查询 DSL
- 聚合
- 地理空间分析
- 连接器
- EQL
- ES|QL
- SQL
- 脚本
- 数据管理
- 自动缩放
- 监视集群
- 汇总或转换数据
- 设置高可用性集群
- 快照和还原
- 保护 Elastic Stack 的安全
- Watcher
- 命令行工具
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- 优化
- 故障排除
- 修复常见的集群问题
- 诊断未分配的分片
- 向系统中添加丢失的层
- 允许 Elasticsearch 在系统中分配数据
- 允许 Elasticsearch 分配索引
- 索引将索引分配过滤器与数据层节点角色混合,以在数据层之间移动
- 没有足够的节点来分配所有分片副本
- 单个节点上索引的分片总数已超过
- 每个节点的分片总数已达到
- 故障排除损坏
- 修复磁盘空间不足的数据节点
- 修复磁盘空间不足的主节点
- 修复磁盘空间不足的其他角色节点
- 启动索引生命周期管理
- 启动快照生命周期管理
- 从快照恢复
- 故障排除损坏的存储库
- 解决重复的快照策略失败问题
- 故障排除不稳定的集群
- 故障排除发现
- 故障排除监控
- 故障排除转换
- 故障排除 Watcher
- 故障排除搜索
- 故障排除分片容量健康问题
- 故障排除不平衡的集群
- 捕获诊断信息
- REST API
- API 约定
- 通用选项
- REST API 兼容性
- 自动缩放 API
- 行为分析 API
- 紧凑和对齐文本 (CAT) API
- 集群 API
- 跨集群复制 API
- 连接器 API
- 数据流 API
- 文档 API
- 丰富 API
- EQL API
- ES|QL API
- 功能 API
- Fleet API
- 图表探索 API
- 索引 API
- 别名是否存在
- 别名
- 分析
- 分析索引磁盘使用量
- 清除缓存
- 克隆索引
- 关闭索引
- 创建索引
- 创建或更新别名
- 创建或更新组件模板
- 创建或更新索引模板
- 创建或更新索引模板(旧版)
- 删除组件模板
- 删除悬挂索引
- 删除别名
- 删除索引
- 删除索引模板
- 删除索引模板(旧版)
- 存在
- 字段使用情况统计信息
- 刷新
- 强制合并
- 获取别名
- 获取组件模板
- 获取字段映射
- 获取索引
- 获取索引设置
- 获取索引模板
- 获取索引模板(旧版)
- 获取映射
- 导入悬挂索引
- 索引恢复
- 索引段
- 索引分片存储
- 索引统计信息
- 索引模板是否存在(旧版)
- 列出悬挂索引
- 打开索引
- 刷新
- 解析索引
- 解析集群
- 翻转
- 收缩索引
- 模拟索引
- 模拟模板
- 拆分索引
- 解冻索引
- 更新索引设置
- 更新映射
- 索引生命周期管理 API
- 推理 API
- 信息 API
- 摄取 API
- 许可 API
- Logstash API
- 机器学习 API
- 机器学习异常检测 API
- 机器学习数据帧分析 API
- 机器学习训练模型 API
- 迁移 API
- 节点生命周期 API
- 查询规则 API
- 重新加载搜索分析器 API
- 存储库计量 API
- 汇总 API
- 根 API
- 脚本 API
- 搜索 API
- 搜索应用程序 API
- 可搜索快照 API
- 安全 API
- 身份验证
- 更改密码
- 清除缓存
- 清除角色缓存
- 清除权限缓存
- 清除 API 密钥缓存
- 清除服务帐户令牌缓存
- 创建 API 密钥
- 创建或更新应用程序权限
- 创建或更新角色映射
- 创建或更新角色
- 批量创建或更新角色 API
- 批量删除角色 API
- 创建或更新用户
- 创建服务帐户令牌
- 委托 PKI 身份验证
- 删除应用程序权限
- 删除角色映射
- 删除角色
- 删除服务帐户令牌
- 删除用户
- 禁用用户
- 启用用户
- 注册 Kibana
- 注册节点
- 获取 API 密钥信息
- 获取应用程序权限
- 获取内置权限
- 获取角色映射
- 获取角色
- 查询角色
- 获取服务帐户
- 获取服务帐户凭据
- 获取安全设置
- 获取令牌
- 获取用户权限
- 获取用户
- 授予 API 密钥
- 具有权限
- 使 API 密钥失效
- 使令牌失效
- OpenID Connect 准备身份验证
- OpenID Connect 身份验证
- OpenID Connect 注销
- 查询 API 密钥信息
- 查询用户
- 更新 API 密钥
- 更新安全设置
- 批量更新 API 密钥
- SAML 准备身份验证
- SAML 身份验证
- SAML 注销
- SAML 失效
- SAML 完成注销
- SAML 服务提供商元数据
- SSL 证书
- 激活用户配置文件
- 禁用用户配置文件
- 启用用户配置文件
- 获取用户配置文件
- 建议用户配置文件
- 更新用户配置文件数据
- 具有用户配置文件权限
- 创建跨集群 API 密钥
- 更新跨集群 API 密钥
- 快照和还原 API
- 快照生命周期管理 API
- SQL API
- 同义词 API
- 文本结构 API
- 转换 API
- 使用情况 API
- Watcher API
- 定义
- 迁移指南
- 发行说明
- Elasticsearch 版本 8.17.0
- Elasticsearch 版本 8.16.1
- Elasticsearch 版本 8.16.0
- Elasticsearch 版本 8.15.5
- Elasticsearch 版本 8.15.4
- Elasticsearch 版本 8.15.3
- Elasticsearch 版本 8.15.2
- Elasticsearch 版本 8.15.1
- Elasticsearch 版本 8.15.0
- Elasticsearch 版本 8.14.3
- Elasticsearch 版本 8.14.2
- Elasticsearch 版本 8.14.1
- Elasticsearch 版本 8.14.0
- Elasticsearch 版本 8.13.4
- Elasticsearch 版本 8.13.3
- Elasticsearch 版本 8.13.2
- Elasticsearch 版本 8.13.1
- Elasticsearch 版本 8.13.0
- Elasticsearch 版本 8.12.2
- Elasticsearch 版本 8.12.1
- Elasticsearch 版本 8.12.0
- Elasticsearch 版本 8.11.4
- Elasticsearch 版本 8.11.3
- Elasticsearch 版本 8.11.2
- Elasticsearch 版本 8.11.1
- Elasticsearch 版本 8.11.0
- Elasticsearch 版本 8.10.4
- Elasticsearch 版本 8.10.3
- Elasticsearch 版本 8.10.2
- Elasticsearch 版本 8.10.1
- Elasticsearch 版本 8.10.0
- Elasticsearch 版本 8.9.2
- Elasticsearch 版本 8.9.1
- Elasticsearch 版本 8.9.0
- Elasticsearch 版本 8.8.2
- Elasticsearch 版本 8.8.1
- Elasticsearch 版本 8.8.0
- Elasticsearch 版本 8.7.1
- Elasticsearch 版本 8.7.0
- Elasticsearch 版本 8.6.2
- Elasticsearch 版本 8.6.1
- Elasticsearch 版本 8.6.0
- Elasticsearch 版本 8.5.3
- Elasticsearch 版本 8.5.2
- Elasticsearch 版本 8.5.1
- Elasticsearch 版本 8.5.0
- Elasticsearch 版本 8.4.3
- Elasticsearch 版本 8.4.2
- Elasticsearch 版本 8.4.1
- Elasticsearch 版本 8.4.0
- Elasticsearch 版本 8.3.3
- Elasticsearch 版本 8.3.2
- Elasticsearch 版本 8.3.1
- Elasticsearch 版本 8.3.0
- Elasticsearch 版本 8.2.3
- Elasticsearch 版本 8.2.2
- Elasticsearch 版本 8.2.1
- Elasticsearch 版本 8.2.0
- Elasticsearch 版本 8.1.3
- Elasticsearch 版本 8.1.2
- Elasticsearch 版本 8.1.1
- Elasticsearch 版本 8.1.0
- Elasticsearch 版本 8.0.1
- Elasticsearch 版本 8.0.0
- Elasticsearch 版本 8.0.0-rc2
- Elasticsearch 版本 8.0.0-rc1
- Elasticsearch 版本 8.0.0-beta1
- Elasticsearch 版本 8.0.0-alpha2
- Elasticsearch 版本 8.0.0-alpha1
- 依赖项和版本
修复其他角色节点磁盘空间不足
编辑修复其他角色节点磁盘空间不足
编辑Elasticsearch 可以使用专用节点来执行除存储数据或协调集群之外的其他功能,例如机器学习。如果这些节点中的一个或多个磁盘空间不足,您需要确保它们有足够的磁盘空间来运行。如果 健康 API 报告某个非主节点且不包含数据的节点磁盘空间不足,则您需要增加此节点的磁盘容量。
- 登录到 Elastic Cloud 控制台。
- 在 Elasticsearch 服务 面板上,点击与您的部署名称对应的
管理部署列下的齿轮图标。 -
转到
操作 > 编辑部署,然后根据诊断中列出的角色,转到协调实例或机器学习实例部分。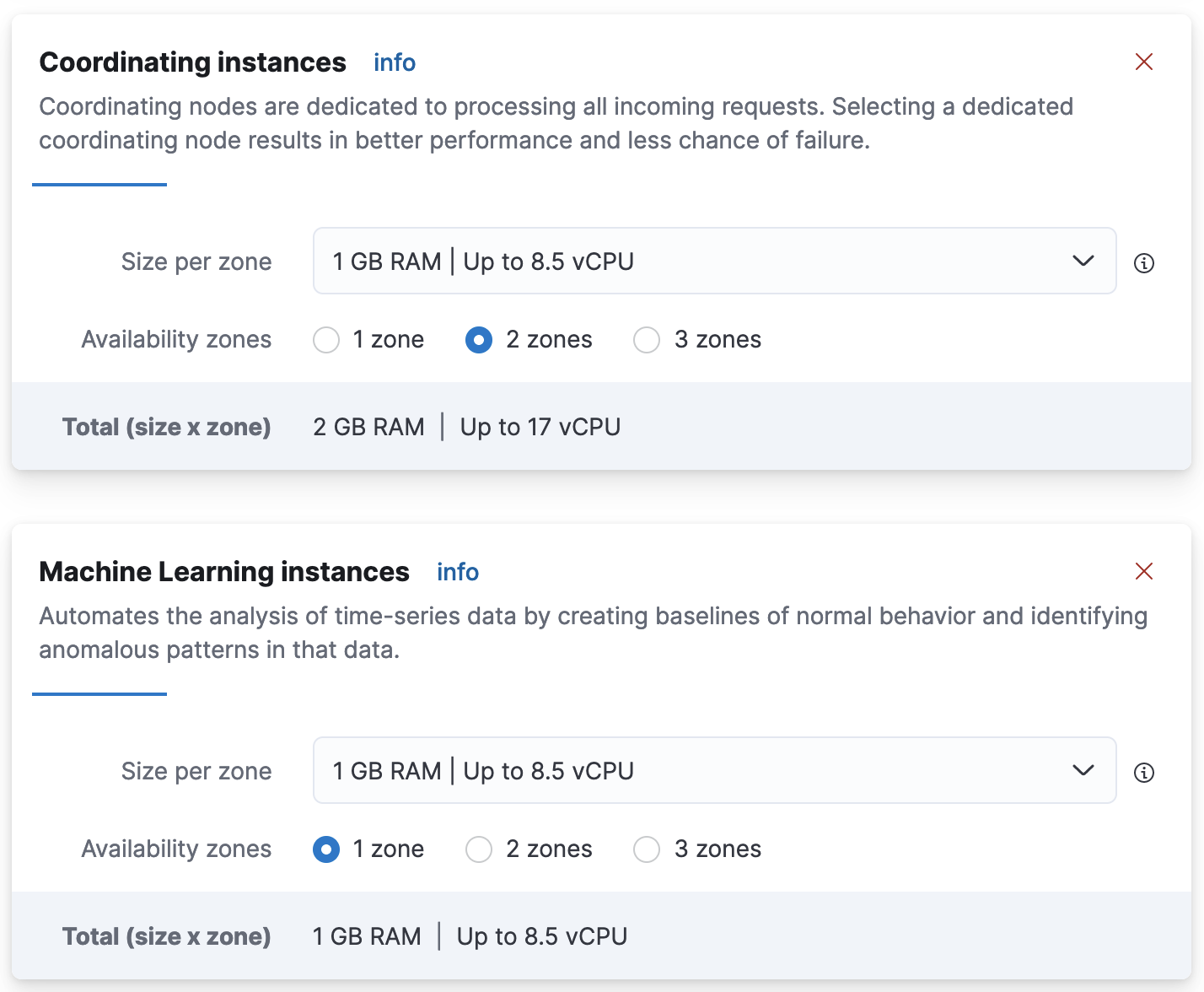
- 从下拉菜单中选择比预选容量更大的配置,然后点击
保存。等待计划应用,问题应该会得到解决。
为了增加任何其他节点的磁盘容量,您需要将磁盘空间不足的实例替换为磁盘容量更高的实例。
-
首先,检索将指示需要多少磁盘空间的磁盘阈值。相关的阈值是高水位线,可以通过以下命令检索
resp = client.cluster.get_settings( include_defaults=True, filter_path="*.cluster.routing.allocation.disk.watermark.high*", ) print(resp)
response = client.cluster.get_settings( include_defaults: true, filter_path: '*.cluster.routing.allocation.disk.watermark.high*' ) puts response
const response = await client.cluster.getSettings({ include_defaults: "true", filter_path: "*.cluster.routing.allocation.disk.watermark.high*", }); console.log(response);
GET _cluster/settings?include_defaults&filter_path=*.cluster.routing.allocation.disk.watermark.high*
响应将如下所示
{ "defaults": { "cluster": { "routing": { "allocation": { "disk": { "watermark": { "high": "90%", "high.max_headroom": "150GB" } } } } } }
以上意味着,为了解决磁盘短缺问题,我们需要将磁盘使用率降至 90% 以下,或者拥有超过 150GB 的可用空间。有关此阈值如何工作的更多信息,请点击此处阅读。
-
下一步是找出当前的磁盘使用情况,这将允许计算需要多少额外空间。在以下示例中,出于可读性的目的,我们仅显示一个机器学习节点
resp = client.cat.nodes( v=True, h="name,node.role,disk.used_percent,disk.used,disk.avail,disk.total", ) print(resp)
response = client.cat.nodes( v: true, h: 'name,node.role,disk.used_percent,disk.used,disk.avail,disk.total' ) puts response
const response = await client.cat.nodes({ v: "true", h: "name,node.role,disk.used_percent,disk.used,disk.avail,disk.total", }); console.log(response);
GET /_cat/nodes?v&h=name,node.role,disk.used_percent,disk.used,disk.avail,disk.total
响应将如下所示
name node.role disk.used_percent disk.used disk.avail disk.total instance-0000000000 l 85.31 3.4gb 500mb 4gb
- 理想情况是将磁盘使用率降至相关阈值以下,在我们的示例中为 90%。考虑添加一些填充,使其不会很快超过阈值。假设您已准备好新节点,请将此节点添加到集群。
-
验证新节点是否已加入集群
resp = client.cat.nodes( v=True, h="name,node.role,disk.used_percent,disk.used,disk.avail,disk.total", ) print(resp)
response = client.cat.nodes( v: true, h: 'name,node.role,disk.used_percent,disk.used,disk.avail,disk.total' ) puts response
const response = await client.cat.nodes({ v: "true", h: "name,node.role,disk.used_percent,disk.used,disk.avail,disk.total", }); console.log(response);
GET /_cat/nodes?v&h=name,node.role,disk.used_percent,disk.used,disk.avail,disk.total
响应将如下所示
name node.role disk.used_percent disk.used disk.avail disk.total instance-0000000000 l 85.31 3.4gb 500mb 4gb instance-0000000001 l 41.31 3.4gb 4.5gb 8gb
- 现在您可以删除磁盘空间不足的实例。
Was this helpful?
Thank you for your feedback.