- Elasticsearch 指南其他版本
- 8.17 中的新功能
- Elasticsearch 基础
- 快速入门
- 设置 Elasticsearch
- 升级 Elasticsearch
- 索引模块
- 映射
- 文本分析
- 索引模板
- 数据流
- 摄取管道
- 别名
- 搜索您的数据
- 重新排名
- 查询 DSL
- 聚合
- 地理空间分析
- 连接器
- EQL
- ES|QL
- SQL
- 脚本
- 数据管理
- 自动缩放
- 监视集群
- 汇总或转换数据
- 设置高可用性集群
- 快照和还原
- 保护 Elastic Stack 的安全
- Watcher
- 命令行工具
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- 优化
- 故障排除
- 修复常见的集群问题
- 诊断未分配的分片
- 向系统中添加丢失的层
- 允许 Elasticsearch 在系统中分配数据
- 允许 Elasticsearch 分配索引
- 索引将索引分配过滤器与数据层节点角色混合,以在数据层之间移动
- 没有足够的节点来分配所有分片副本
- 单个节点上索引的分片总数已超过
- 每个节点的分片总数已达到
- 故障排除损坏
- 修复磁盘空间不足的数据节点
- 修复磁盘空间不足的主节点
- 修复磁盘空间不足的其他角色节点
- 启动索引生命周期管理
- 启动快照生命周期管理
- 从快照恢复
- 故障排除损坏的存储库
- 解决重复的快照策略失败问题
- 故障排除不稳定的集群
- 故障排除发现
- 故障排除监控
- 故障排除转换
- 故障排除 Watcher
- 故障排除搜索
- 故障排除分片容量健康问题
- 故障排除不平衡的集群
- 捕获诊断信息
- REST API
- API 约定
- 通用选项
- REST API 兼容性
- 自动缩放 API
- 行为分析 API
- 紧凑和对齐文本 (CAT) API
- 集群 API
- 跨集群复制 API
- 连接器 API
- 数据流 API
- 文档 API
- 丰富 API
- EQL API
- ES|QL API
- 功能 API
- Fleet API
- 图表探索 API
- 索引 API
- 别名是否存在
- 别名
- 分析
- 分析索引磁盘使用量
- 清除缓存
- 克隆索引
- 关闭索引
- 创建索引
- 创建或更新别名
- 创建或更新组件模板
- 创建或更新索引模板
- 创建或更新索引模板(旧版)
- 删除组件模板
- 删除悬挂索引
- 删除别名
- 删除索引
- 删除索引模板
- 删除索引模板(旧版)
- 存在
- 字段使用情况统计信息
- 刷新
- 强制合并
- 获取别名
- 获取组件模板
- 获取字段映射
- 获取索引
- 获取索引设置
- 获取索引模板
- 获取索引模板(旧版)
- 获取映射
- 导入悬挂索引
- 索引恢复
- 索引段
- 索引分片存储
- 索引统计信息
- 索引模板是否存在(旧版)
- 列出悬挂索引
- 打开索引
- 刷新
- 解析索引
- 解析集群
- 翻转
- 收缩索引
- 模拟索引
- 模拟模板
- 拆分索引
- 解冻索引
- 更新索引设置
- 更新映射
- 索引生命周期管理 API
- 推理 API
- 信息 API
- 摄取 API
- 许可 API
- Logstash API
- 机器学习 API
- 机器学习异常检测 API
- 机器学习数据帧分析 API
- 机器学习训练模型 API
- 迁移 API
- 节点生命周期 API
- 查询规则 API
- 重新加载搜索分析器 API
- 存储库计量 API
- 汇总 API
- 根 API
- 脚本 API
- 搜索 API
- 搜索应用程序 API
- 可搜索快照 API
- 安全 API
- 身份验证
- 更改密码
- 清除缓存
- 清除角色缓存
- 清除权限缓存
- 清除 API 密钥缓存
- 清除服务帐户令牌缓存
- 创建 API 密钥
- 创建或更新应用程序权限
- 创建或更新角色映射
- 创建或更新角色
- 批量创建或更新角色 API
- 批量删除角色 API
- 创建或更新用户
- 创建服务帐户令牌
- 委托 PKI 身份验证
- 删除应用程序权限
- 删除角色映射
- 删除角色
- 删除服务帐户令牌
- 删除用户
- 禁用用户
- 启用用户
- 注册 Kibana
- 注册节点
- 获取 API 密钥信息
- 获取应用程序权限
- 获取内置权限
- 获取角色映射
- 获取角色
- 查询角色
- 获取服务帐户
- 获取服务帐户凭据
- 获取安全设置
- 获取令牌
- 获取用户权限
- 获取用户
- 授予 API 密钥
- 具有权限
- 使 API 密钥失效
- 使令牌失效
- OpenID Connect 准备身份验证
- OpenID Connect 身份验证
- OpenID Connect 注销
- 查询 API 密钥信息
- 查询用户
- 更新 API 密钥
- 更新安全设置
- 批量更新 API 密钥
- SAML 准备身份验证
- SAML 身份验证
- SAML 注销
- SAML 失效
- SAML 完成注销
- SAML 服务提供商元数据
- SSL 证书
- 激活用户配置文件
- 禁用用户配置文件
- 启用用户配置文件
- 获取用户配置文件
- 建议用户配置文件
- 更新用户配置文件数据
- 具有用户配置文件权限
- 创建跨集群 API 密钥
- 更新跨集群 API 密钥
- 快照和还原 API
- 快照生命周期管理 API
- SQL API
- 同义词 API
- 文本结构 API
- 转换 API
- 使用情况 API
- Watcher API
- 定义
- 迁移指南
- 发行说明
- Elasticsearch 版本 8.17.0
- Elasticsearch 版本 8.16.1
- Elasticsearch 版本 8.16.0
- Elasticsearch 版本 8.15.5
- Elasticsearch 版本 8.15.4
- Elasticsearch 版本 8.15.3
- Elasticsearch 版本 8.15.2
- Elasticsearch 版本 8.15.1
- Elasticsearch 版本 8.15.0
- Elasticsearch 版本 8.14.3
- Elasticsearch 版本 8.14.2
- Elasticsearch 版本 8.14.1
- Elasticsearch 版本 8.14.0
- Elasticsearch 版本 8.13.4
- Elasticsearch 版本 8.13.3
- Elasticsearch 版本 8.13.2
- Elasticsearch 版本 8.13.1
- Elasticsearch 版本 8.13.0
- Elasticsearch 版本 8.12.2
- Elasticsearch 版本 8.12.1
- Elasticsearch 版本 8.12.0
- Elasticsearch 版本 8.11.4
- Elasticsearch 版本 8.11.3
- Elasticsearch 版本 8.11.2
- Elasticsearch 版本 8.11.1
- Elasticsearch 版本 8.11.0
- Elasticsearch 版本 8.10.4
- Elasticsearch 版本 8.10.3
- Elasticsearch 版本 8.10.2
- Elasticsearch 版本 8.10.1
- Elasticsearch 版本 8.10.0
- Elasticsearch 版本 8.9.2
- Elasticsearch 版本 8.9.1
- Elasticsearch 版本 8.9.0
- Elasticsearch 版本 8.8.2
- Elasticsearch 版本 8.8.1
- Elasticsearch 版本 8.8.0
- Elasticsearch 版本 8.7.1
- Elasticsearch 版本 8.7.0
- Elasticsearch 版本 8.6.2
- Elasticsearch 版本 8.6.1
- Elasticsearch 版本 8.6.0
- Elasticsearch 版本 8.5.3
- Elasticsearch 版本 8.5.2
- Elasticsearch 版本 8.5.1
- Elasticsearch 版本 8.5.0
- Elasticsearch 版本 8.4.3
- Elasticsearch 版本 8.4.2
- Elasticsearch 版本 8.4.1
- Elasticsearch 版本 8.4.0
- Elasticsearch 版本 8.3.3
- Elasticsearch 版本 8.3.2
- Elasticsearch 版本 8.3.1
- Elasticsearch 版本 8.3.0
- Elasticsearch 版本 8.2.3
- Elasticsearch 版本 8.2.2
- Elasticsearch 版本 8.2.1
- Elasticsearch 版本 8.2.0
- Elasticsearch 版本 8.1.3
- Elasticsearch 版本 8.1.2
- Elasticsearch 版本 8.1.1
- Elasticsearch 版本 8.1.0
- Elasticsearch 版本 8.0.1
- Elasticsearch 版本 8.0.0
- Elasticsearch 版本 8.0.0-rc2
- Elasticsearch 版本 8.0.0-rc1
- Elasticsearch 版本 8.0.0-beta1
- Elasticsearch 版本 8.0.0-alpha2
- Elasticsearch 版本 8.0.0-alpha1
- 依赖项和版本
搜索中的摄取管道
编辑搜索中的摄取管道
编辑您可以通过 Elasticsearch API 或 Kibana UI 管理摄取管道。
搜索下的内容 UI 具有一组工具,用于创建和管理针对搜索用例(非时间序列数据)优化的索引。您还可以在此 UI 中管理您的摄取管道。
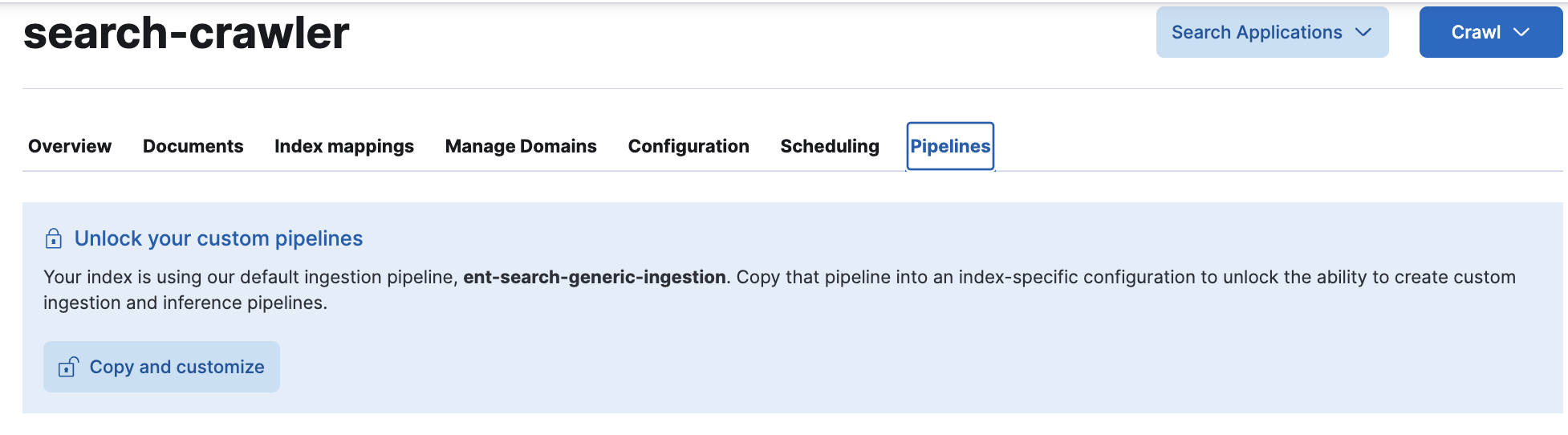
在内容 UI 中查找管道
编辑要使用这些 UI 工具处理摄取管道,您将使用搜索优化 Elasticsearch 索引上的管道选项卡。
在 Kibana UI 中查找此选项卡:
- 转到搜索 > 内容 > Elasticsearch 索引。
- 选择要使用的索引。例如,
search-my-index。 - 在索引的概述页面上,打开管道选项卡。
- 在这里,您可以按照说明创建自定义管道,并设置 ML 推理管道。
此选项卡在此屏幕截图中突出显示:
概述
编辑这些工具可以通过提供文档的自定义和后处理层来特别有帮助。例如:
- 提供从二进制数据类型一致提取文本的方法
- 确保一致的格式
- 提供一致的清理步骤(删除诸如电话号码或 SSN 之类的 PII)
从头开始设置和管理生产就绪的管道可能需要大量工作。必须考虑错误处理、条件执行、排序、版本控制和模块化等因素。
为此,当您为搜索用例创建索引时(包括Elastic Web 爬虫、连接器 和 API 索引),每个索引都已经设置了一个管道,其中包含多个处理器,这些处理器可优化您的搜索内容。
此管道称为 ent-search-generic-ingestion。虽然它是一个“托管”管道(意味着不应被篡改),但您可以通过 Kibana UI 或 Elasticsearch API 查看其详细信息。您还可以阅读更多关于其以下内容的信息。
您可以控制是否运行其中一些处理器。虽然默认情况下启用了所有功能,但它们可以选择退出。对于Elastic 爬虫和连接器,您可以选择每个索引退出(或重新进入),并且您的选择会被保存。对于 API 索引,您可以通过在文档中包含特定字段来选择退出(或重新进入)。请参阅下面的详细信息。
在部署级别,您可以更改所有新索引的默认设置。这不会影响现有索引。
每个索引还提供了轻松创建具有可自定义处理的特定于索引的摄取管道的功能。如果您需要额外的灵活性,可以通过转到您的管道设置并选择“复制并自定义”来创建自定义管道。这将使用 3 个新生成的管道替换索引对 ent-search-generic-ingestion 的使用
-
<索引名称> -
<索引名称>@custom -
<索引名称>@ml-inference
与 ent-search-generic-ingestion 一样,其中第一个是“托管的”,但其他两个可以并且应该修改以满足您的需求。您可以使用平台工具(Kibana UI、Elasticsearch API)查看这些管道,还可以阅读更多关于其以下内容的信息。
管道设置
编辑除了管道本身,您还有一些配置选项可以控制管道的各个功能。
- 提取二进制内容 - 这控制是否应处理二进制文档并提取任何文本内容。
- 减少空格 - 这控制是否应删除连续的、前导和尾随空格。这有助于在某些搜索体验中显示更多内容。
-
运行 ML 推理 - 仅在特定于索引的管道上可用。这控制是否将运行可选的
<索引名称>@ml-inference管道。默认情况下启用。
对于 Elastic Web 爬虫和连接器,您可以选择每个索引加入或退出。这些设置存储在 Elasticsearch 的 .elastic-connectors 索引中,位于与特定索引对应的文档中。可以在那里直接更改这些设置,也可以通过 Kibana UI 在搜索 > 内容 > 索引 > <您的索引> > 管道 > 设置中更改。
您还可以更改部署范围的默认值。这些设置存储在 Elasticsearch .elastic-connectors 的映射中的 _meta 部分。可以在那里直接更改这些设置,也可以在 Kibana UI 的搜索 > 内容 > 设置选项卡中更改。更改部署范围的默认值不会影响任何现有索引,只会影响任何新创建的索引的默认值。这些默认值仍然可以被特定于索引的设置覆盖。
使用 API
编辑这些设置不会为“使用 API”的索引持久化。相反,更改这些设置将实时更改显示的示例 cURL 请求。请注意,cURL 请求中的示例文档包含三个以下划线开头的字段:
{ ... "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true }
省略这些特殊字段之一与指定值为 false 相同。
您还必须在索引请求中指定管道。这也在示例 cURL 请求中显示。
如果未指定管道,则以下划线开头的字段实际上将被索引,并且不会影响任何处理行为。
详细信息
编辑ent-search-generic-ingestion 参考
编辑您可以使用Elasticsearch 摄取管道 API或通过 Kibana 的堆栈管理 > 摄取管道 UI 访问此管道。
此管道是一个“托管”管道。这意味着它不打算被编辑。手动编辑/更新此管道可能会导致意外行为,或未来升级困难。如果您想进行自定义,我们建议您使用特定于索引的管道(见下文),特别是<索引名称>@custom 管道。
处理器
编辑-
attachment- 这使用附件处理器将存储在文档的_attachment字段中的任何二进制数据转换为纯文本和元数据的嵌套对象。 -
set_body- 这使用设置处理器复制从上一步提取的任何纯文本,并将其保留在文档的body字段中。 -
remove_replacement_chars- 这使用Gsub处理器从body字段中删除诸如“�”之类的字符。 -
remove_extra_whitespace- 这使用Gsub处理器将body字段中连续的空格字符替换为单个空格。虽然对于每个用例(请参阅下文了解如何禁用)并非完美,但这可以确保搜索体验为搜索结果显示更多内容和突出显示,并减少空白空间。 -
trim- 这使用修剪处理器从body字段中删除任何剩余的前导或尾随空格。 -
remove_meta_fields- 管道的最后一步使用删除处理器删除可能已在管道中的其他位置使用的特殊字段,无论是作为临时存储还是作为控制流参数。
控制流参数
编辑ent-search-generic-ingestion 管道并非始终运行所有处理器。它利用摄取管道的功能,根据每个文档的内容有条件地运行处理器。
-
_extract_binary_content- 如果此字段存在并且源文档上的值为true,则管道将尝试运行attachment、set_body和remove_replacement_chars处理器。请注意,文档还需要一个填充了 base64 编码的二进制数据的_attachment字段,以便attachment处理器有任何输出。如果源文档中缺少_extract_binary_content字段或其值为false,则将跳过这些处理器。 -
_reduce_whitespace- 如果此字段存在并且源文档上的值为true,则管道将尝试运行remove_extra_whitespace和trim处理器。这些处理器仅适用于body字段。如果源文档中缺少_reduce_whitespace字段或其值为false,则将跳过这些处理器。
爬虫、本机连接器和连接器客户端将根据索引的“管道”选项卡中的设置自动添加这些控制流参数。要控制任何新索引在创建时将具有哪些设置,请参阅部署范围的内容设置。请参阅管道设置。
特定于索引的摄取管道
编辑在 Kibana UI 中,对于您的索引,通过单击“管道”选项卡,然后单击设置 > 复制并自定义,您可以快速生成 3 个特定于您的索引的管道。这 3 个管道将替换索引的 ent-search-generic-ingestion。此操作中没有任何损失,因为 <索引名称> 管道的功能是 ent-search-generic-ingestion 管道的超集。
并非在所有 Elastic 订阅级别都提供“复制和自定义”按钮。有关Elastic Cloud 和 自管理部署的信息,请参阅 Elastic 订阅页面。
<索引名称> 参考
编辑此管道的外观和行为与ent-search-generic-ingestion 管道非常相似,但有两个附加的处理器。
您不应重命名此管道。
此管道是一个“托管”管道。这意味着它不应被编辑。手动编辑/更新此管道可能会导致意外行为,或在将来升级时遇到困难。如果您想进行自定义,我们建议您使用<index-name>@custom 管道。
处理器
编辑除了从 ent-search-generic-ingestion 管道继承的处理器之外,特定于索引的管道还定义了:
控制流参数
编辑与 ent-search-generic-ingestion 管道类似,<index-name> 管道并非总是运行所有处理器。除了 _extract_binary_content 和 _reduce_whitespace 控制流参数之外,<index-name> 管道还支持:
-
_run_ml_inference- 如果源文档中存在此字段且值为true,则管道将尝试运行index_ml_inference_pipeline处理器。如果源文档中缺少_run_ml_inference字段或该字段的值为false,则将跳过此处理器。
爬虫、本机连接器和连接器客户端将根据索引的“管道”选项卡中的设置自动添加这些控制流参数。要控制任何新索引在创建时将具有哪些设置,请参阅部署范围的内容设置。请参阅管道设置。
<index-name>@ml-inference 参考
编辑此管道在开始时为空(没有处理器),但可以通过 Kibana UI 从索引的“管道”选项卡或从堆栈管理 > 摄取管道页面添加。与 ent-search-generic-ingestion 管道和 <index-name> 管道不同,此管道不是“托管”的。
可以在 内容 UI 中向索引添加一个或多个 ML 推理管道。此管道将作为为索引配置的所有 ML 推理管道的容器。添加到索引的每个 ML 推理管道都在 <index-name>@ml-inference 中使用 pipeline 处理器引用。
您不应重命名此管道。
要管理使用这些模型的 ML 模型和 ML 推理管道,需要 monitor_ml Elasticsearch 集群权限。
<index-name>@custom 参考
编辑此管道在开始时为空(没有处理器),但可以通过 Kibana UI 从索引的“管道”选项卡或从堆栈管理 > 摄取管道页面添加。与 ent-search-generic-ingestion 管道和 <index-name> 管道不同,此管道不是“托管”的。
我们鼓励您对此管道进行添加和编辑,前提是其名称保持不变。这提供了一个方便的钩子,可以从中添加自定义处理和数据转换。请务必阅读摄取管道的文档,了解有哪些可用选项。
您不应重命名此管道。
升级说明
编辑展开以查看升级说明
-
app_search_crawler- 自 8.3 版本以来,App Search Web 爬虫已使用此管道来支持其二进制内容提取。您可以在App Search 指南中阅读有关此管道及其用法的更多信息。从 8.3 升级到 8.5+ 时,请务必注意您对app_search_crawler管道所做的任何更改。这些更改应重新应用于每个索引的<index-name>@custom管道,以确保一致的数据处理体验。在 8.5+ 版本中,除了App Search 指南中提到的配置之外,还需要启用二进制内容的索引设置。 -
ent_search_crawler- 自 8.4 版本以来,Elastic Web 爬虫已使用此管道来支持其二进制内容提取。您可以在Elastic Web 爬虫指南中阅读有关此管道及其用法的更多信息。从 8.4 升级到 8.5+ 时,请务必注意您对ent_search_crawler管道所做的任何更改。这些更改应重新应用于每个索引的<index-name>@custom管道,以确保一致的数据处理体验。在 8.5+ 版本中,除了Elastic Web 爬虫指南中提到的配置之外,还需要启用二进制内容的索引设置。 -
ent-search-generic-ingestion- 自 8.5 版本以来,原生连接器、连接器客户端和新的(> 8.4)Elastic Web 爬虫索引都将默认使用此管道。您可以在上面阅读有关此管道的更多信息。由于此管道是“托管的”,因此不应对app_search_crawler和/或ent_search_crawler所做的任何修改对ent-search-generic-ingestion进行修改。相反,如果需要进行此类自定义,则应使用特定于索引的摄取管道,将所有修改放在<index-name>@custom管道中。
On this page